图文|娘酷
上一篇文章中我介绍了Web Scraper的基本用法,接下来的内容中,我将接着介绍Web Scraper在收集多层级的数据的进阶套路。
进阶套路
仍然以我的关注列表为例,这一次我不仅想要收集我都关注了谁,我还想要他们的一些个人信息,如:他们的粉丝数,关注数,文章数,一共写过多少字。

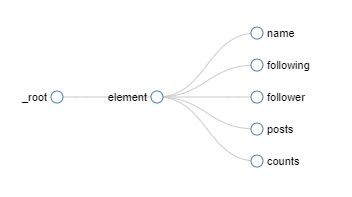
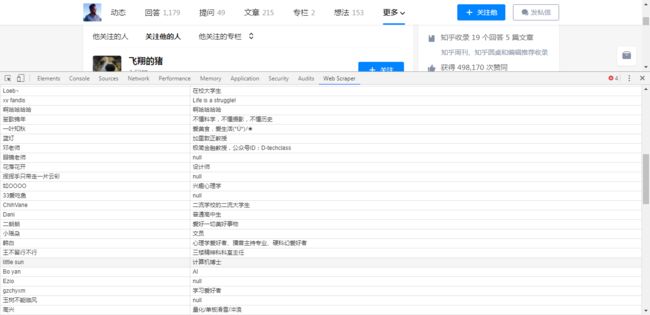
我的关注列表中有96张如图所示的卡片,我们暂且称之为名片。每张名片中包含了此人的多维度信息,头像、网名、关注数、粉丝数、文章数、写了多少字,获得了多少个喜欢,甚至还可以算上单击他网名跳转的个人主页的链接。那么这里,就存在一个二级包含关系,名片是要收集的一级对象,而名字,粉丝数,关注数则是二级对象。而像名片这样在页面中存在多个,自己本身也包含多个二级对象的目标,我们称其为元素。抓取时Type选择为Element。
新建:shift+ctrl+I 唤出开发者工具 -> Web Scraper -> Create New Sitemap -> Sitemap Name:niangkufollowers; sitemap URL: https://www.jianshu.com/users/f354e815185f/following
添加元素对象(element):元素就像是一个书包内部可以包含多个目标,所以此处为了收集每个人的相关信息,将每一个名片看做一个元素。创建Selector,Type设定为Element,单击“select”按钮后,将鼠标移至名片处,选中第一个和第二个名片后,WS会自动圈起页面上其他名片(这个页面上有多个名片记得要勾选multiple)。Done Selecting! -> Save Selector
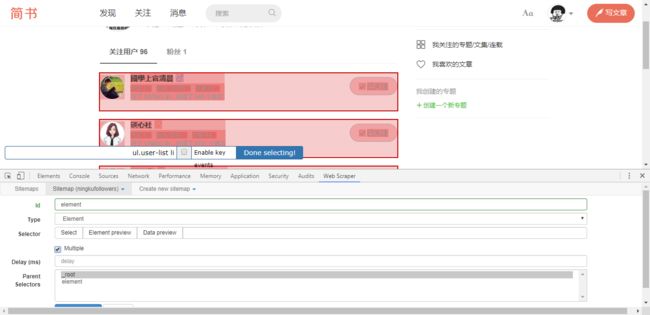
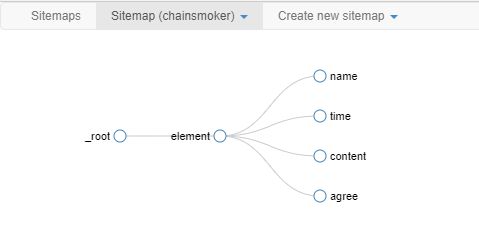
添加元素内二级目标:单击Element -> 依次添加二级目标(Add New Selector ):网名(name), 关注数(following),粉丝数(follower),文章数(posts),字数(counts)。类型全部选择“Text”。因为每个元素内都只含有一个网名,则不用勾选multiple。添加过程参照 基础套路

有时想要选中的目标是带有跳转连接的,如本例中的网名,单击后会跳转就无法在selector中保存,这里的小技巧是,可以在“Done Selecting!”按钮左侧单击“Enable key”,就可以使用键盘进行操作。将鼠标移至对象上,单击键盘S键,就可以选中了。
让我们再爬一次!不用设置delay直接启动!Sitemap(niangkufollowers) -> Scrape
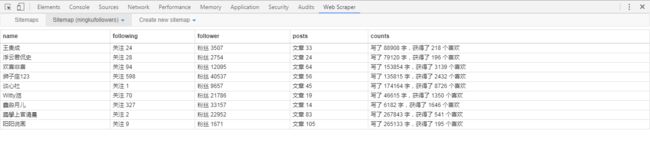
YEAH!我们有了更多维度的数据
虽然我们有了更多维度的数据,但仍结果只有9个。如果我们想要跟多的数据该怎么办?仔细看一下这个网页,你会发现,它的加载方式是:滑到底部时会自动加载9条名片。滑动时加载,是动态加载的一种方式。除了滑动加载,还有点击更多按钮加载,点击页码加载。只有解决了网页的加载,让网页顺顺利利的把数据吐出来,我们才能完成完整的收集。
滑动加载
点击Sitemap(niangkufollowers) -> Selectors ->点击"Edit"编辑一级元素

果断把element的type改成“Element scroll down”

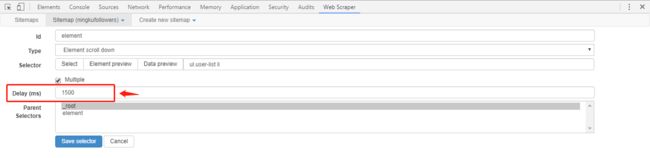
这个Delay的意思就是让它向下滚动的时候等一会,滚太快抓不完就GG了,有时候抓太快也会触发网页的防爬虫机制就直接把你的网页关了。所以慢一点等一会效果更好噢。
让我们再试一次!Scrape!

YESSSSS! 搞定!
让我们再来看看其他加载方式下该如何操作呢
页码加载
当你想要抓取的页面地址带有页码的时候,处理办法在大欣的回答里有体现,直接加上你要抓取页数就好了。如:
https://www.zhihu.com/people/amuro1230/followers?page=2
其他步骤操作方法如上,只用在新建sitemap时将地址改写为:https://www.zhihu.com/people/amuro1230/followers?page=[1-69],虫虫就会自动翻页至第69页时结束
点击加载
有些页面的加载方式是地址不变,点击页码,或者固定按钮如“下一页”,“点击加载”等进行加载。那么这里也分为两类情况来讨论:只点击一次(如数字页码每个页码只点击一次),和点击多次(如多次点击同一个翻页按钮)
点击一次(Click Once)
我们以虾米上烟鬼的新歌Sick boy这首歌为例,讲一下如何收集虾米音乐的歌曲页面下方的评论列表内容。
http://www.xiami.com/album/9cCZb9eaeb8?spm=a1z1s.6843761.1478643713.4.mAVSas

可以看到评论仍然是呈卡片式的,可以设置为元素类型,每个卡片包含网名,时间,评论,赞数,弱数。 抓取评论的逻辑是:先逐条抓下该页的卡片,然后点击下一个页码,再重复以上动作。点击下一个页码意味着:2,3,4依次点击,对象唯一且只点击一次。我们先按照进阶套路中的步骤设置好element和二级目标。
然后按照滑动加载中步骤,进入element编辑页面,将type修改为element click。
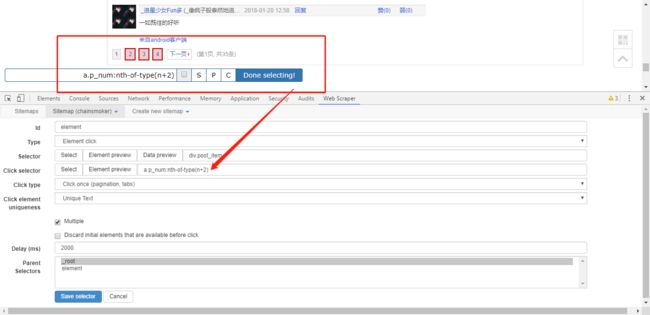
Selector的设置方法与上述元素的选择相同(如果是如上述步骤进行修改到这一步的,则不用重新选择)
在Click Selector处将页码依次选上,同时下方勾选multiple;Click type 点击类型为点击一次,即选中的对象每个只点击一次;Click element uniqueness 点击对象的唯一性中选择唯一文本,即每个数字只出现一次;delay 延迟设置为2000.
让我们试一次!Scrape!
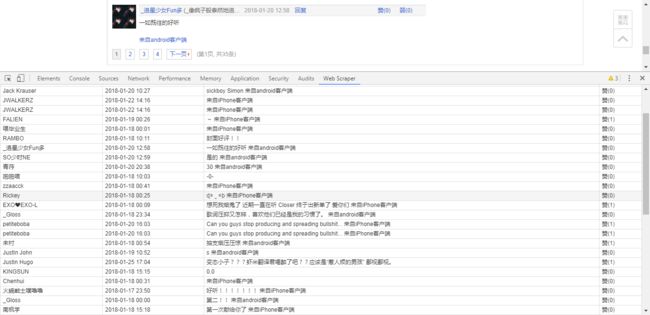
ヾ(◍°∇°◍)ノ゙完美
点击多次(Click More)
在以上抓取虾米音乐评论的逻辑是顺序单击每个页码,我们也可以采取另一种方法,多次点击“下一页”这一个按钮,直到这个网页没有更多新内容。这种方法适用于没有页码按钮,只有“下一页”或者“查看更多”按钮时的状况,比如:

本例选择了绝对伏特加的广告页面(不知道网址是否永久):
http://absolutnights.cn/100nights/
目标仍然为收集卡片上的信息:地址,标题,内容,点赞数,评论数等等。Element和二级目标的设置参照上述步骤。
进入element编辑页面,将type修改为element click -> Click Selector 选择“查看更多”按钮 -> Click type选择Click more -> Delay 设置为2000 -> Save !!

然我们来看一下结果。

以上。
到这里,相信大家已经可以处理大部分的网页了,下一期我将具体介绍每种类型的选择器的应用场景(Selector),大家就会在设置虫虫的过程中更加得心应手了。