在聊这一话题之前,我们先看看屏幕是如何显示图像的。
屏幕显示图像的原理

首先从过去的 CRT 显示器原理说起。CRT 的电子枪按照上面方式,从上到下一行行扫描,扫描完成后显示器就呈现【一帧画面】,随后电子枪回到初始位置继续下一次扫描。
为了把显示器的显示过程和系统的视频控制器进行同步,显示器(或者其他硬件)会用硬件时钟产生一系列的定时信号。当电子枪换到新的一行,准备进行扫描时,显示器会发出一个水平同步信号(horizonal synchronization),简称 HSync;而当一帧画面绘制完成后,电子枪回复到原位,准备画下一帧前,显示器会发出一个垂直同步信号(vertical synchronization),简称 VSync。
显示器通常以固定频率进行刷新,这个刷新率就是 VSync 信号产生的频率。尽管现在的设备大都是液晶显示屏了,但原理仍然没有变。
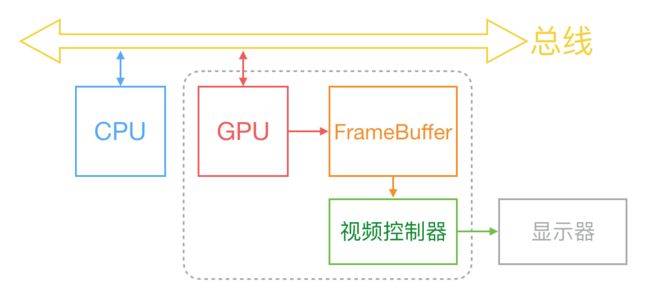
通常来说,计算机系统中 CPU、GPU、显示器是以上面这种方式协同工作的。CPU 计算好显示内容提交到 GPU,GPU 渲染完成后将渲染结果放入帧缓冲区,随后视频控制器会按照 VSync 信号逐行读取帧缓冲区的数据,经过可能的数模转换传递给显示器显示。
在最简单的情况下,帧缓冲区只有一个,这时帧缓冲区的读取和刷新都都会有比较大的效率问题。为了解决效率问题,显示系统通常会引入两个缓冲区,即双缓冲机制。在这种情况下,GPU 会预先渲染好一帧放入一个缓冲区内,让视频控制器读取,当下一帧渲染好后,GPU 会直接把视频控制器的指针指向第二个缓冲器。如此一来效率会有很大的提升。
双缓冲虽然能解决效率问题,但会引入一个新的问题。当视频控制器还未读取完成时,即屏幕内容刚显示一半时,GPU 将新的一帧内容提交到帧缓冲区并把两个缓冲区进行交换后,视频控制器就会把新的一帧数据的下半段显示到屏幕上,造成画面撕裂现象。
为了解决这个问题,GPU 通常有一个机制叫做垂直同步(简写也是 V-Sync),当开启垂直同步后,GPU 会等待显示器的 VSync 信号发出后,才进行新的一帧渲染和缓冲区更新。这样能解决画面撕裂现象,也增加了画面流畅度,但需要消费更多的计算资源,也会带来部分延迟。
下图就是IOS应用界面渲染到展示的流程:


Display 的上一层便是图形处理单元 GPU,GPU 是一个专门为图形高并发计算而量身定做的处理单元。这也是为什么它能同时更新所有的像素,并呈现到显示器上。它并发的本性让它能高效的将不同纹理合成起来。我们将有一小块内容来更详细的讨论图形合成。关键的是,GPU 是非常专业的,因此在某些工作上非常高效。比如,GPU 非常快,并且比 CPU 使用更少的电来完成工作。通常 CPU 都有一个普遍的目的,它可以做很多不同的事情,但是合成图像在 CPU 上却显得比较慢。
卡顿产生的原因
由于垂直同步的机制,如果在一个 VSync 时间内,CPU 或者 GPU 没有完成内容提交,则那一帧就会被丢弃,等待下一次机会再显示,而这时显示屏会保留之前的内容不变。这就是界面卡顿的原因。
因此,我们需要平衡 CPU 和 GPU 的负荷避免一方超负荷运算。为了做到这一点,我们首先得了解 CPU 和 GPU 各自负责哪些内容。

CPU和GPU的职责

在 iOS 系统中,图像内容展示到屏幕的过程需要 CPU 和 GPU 共同参与。
- CPU 负责计算显示内容,比如视图的创建、布局计算、图片解码、文本绘制等。
- 随后 CPU 会将计算好的内容提交到 GPU 去,由 GPU 进行变换、合成、渲染。
- 之后 GPU 会把渲染结果提交到帧缓冲区去,等待下一次 VSync 信号到来时显示到屏幕上。
CPU 消耗型任务
布局计算
布局计算是 iOS 中最为常见的消耗 CPU 资源的地方,如果【视图层级关系比较复杂】,计算出所有图层的布局信息就会消耗一部分时间。因此我们应该尽量提前计算好布局信息,然后在合适的时机调整对应的属性。【还要避免不必要的更新】,只在真正发生了布局改变时再更新。
对象创建
对象创建过程伴随着内存分配、属性设置、甚至还有读取文件等操作,比较消耗 CPU 资源。尽量用轻量的对象代替重量的对象,可以对性能有所优化。比如 CALayer 比 UIView 要轻量许多,如果视图元素不需要响应触摸事件,用 CALayer 会更加合适。
通过 Storyboard 创建视图对象还会涉及到文件反序列化操作,其资源消耗会比直接通过代码创建对象要大非常多,在性能敏感的界面里,Storyboard 并不是一个好的技术选择。
Autolayout
Autolayout 对于复杂视图来说常常会产生严重的性能问题,【对于性能敏感的页面建议还是使用手动布局的方式】,并控制好刷新频率,做到真正需要调整布局时再重新布局。
文本计算
如果一个界面中包含大量文本(比如微博、微信朋友圈等),文本的宽高计算会占用很大一部分资源,并且不可避免。
一个比较常见的场景是在 UITableView 中,heightForRowAtIndexPath
这个方法会被频繁调用。这里的优化就是尽量避免每次都重新进行文本的行高计算,缓存高度即可。如UITableView-FDTemplateLayoutCell
文本渲染
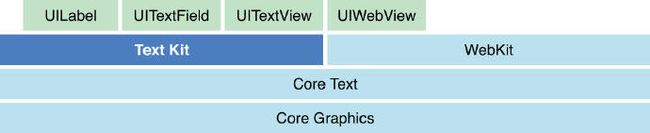
屏幕上能看到的所有文本内容控件,包括 UIWebView,在底层都是通过 CoreText 排版、绘制为 Bitmap 显示的。常见的文本控件 ,其排版和绘制都是在主线程进行的,当显示大量文本时,CPU 的压力会非常大。
这一部分的性能优化就需要我们放弃使用系统提供的上层控件转而直接使用 CoreText 进行排版控制。
Wherever possible, try to avoid making changes to the frame of a view that contains text, because it will cause the text to be redrawn. For example, if you need to display a static block of text in the corner of a layer that frequently changes size, put the text in a sublayer instead.
图像的绘制
图像的绘制通常是指用那些以 CG 开头的方法把图像绘制到画布中,然后从画布创建图片并显示的过程。前面的模块图里介绍了 CoreGraphic 是作用在 CPU 之上的,因此调用 CG 开头的方法消耗的是 CPU 资源。我们可以将绘制过程放到后台线程,然后在主线程里将结果设置到 layer 的 contents 中。代码如下:
- (void)display {
dispatch_async(backgroundQueue, ^{
CGContextRef ctx = CGBitmapContextCreate(...);
// draw in context...
CGImageRef img = CGBitmapContextCreateImage(ctx);
CFRelease(ctx);
dispatch_async(mainQueue, ^{
layer.contents = img;
});
});
}
图片的解码
Once an image file has been loaded, it must then be decompressed. This decompression can be a computationally complex task and take considerable time. The decompressed image will also use substantially more memory than the original.(图片被加载后需要解码,图片的解码是一个复杂耗时的过程,并且需要占用比原始图片还多的内存资源)
【为什么需要解码?】
把图片从PNG或JPEG等格式中解压出来,得到像素数据。如果GPU不支持这种颜色各式,CPU需要进行格式转换。
比如应用中有一些从网络下载的图片,而GPU恰好不支持这个格式,这就需要CPU预先进行格式转化。SDwebImageDecoder就是这个作用。
【默认延迟解码】
当你用 UIImage 或 CGImageSource 的那几个方法创建图片时,为了节省内存,图片数据并不会立刻解码。图片设置到 UIImageView 或者 CALayer.contents 中去,并且 CALayer 被提交到 GPU 前,CGImage 中的数据才会得到解码。这一步是发生在主线程的,并且不可避免。
如果想要绕开这个机制,可以使用 ImageIO 【怎么使用?】或者提前在后台线程先把图片绘制到 CGBitmapContext 中,然后从 Bitmap 直接创建图片。目前常见的网络图片库都自带这个功能。
【不一定是默认延迟解码】
常用的 UIImage 加载方法有 imageNamed和 imageWithContentsOfFile。其中 imageNamed加载图片后会马上解码,并且系统会将解码后的图片缓存起来,但是这个缓存策略是不公开的,我们无法知道图片什么时候会被释放。因此在一些性能敏感的页面,我们还可以用 static 变量 hold 住 imageNamed加载到的图片避免被释放掉,以空间换时间的方式来提高性能。
imageWithContentsOfFile解码后的UIImage对象如果作为临时变量被释放了,则它下次仍然会解码。【所以如果在tableview-cell,即使是读取本地(Bundle或者沙盒)路径图片,仍然建议使用SDWebImage异步缓存读取】
关于图片解码可以参考:
iOS中的imageIO与image解码
[iOS]如何避免图像解压缩的时间开销[还介绍了图片的时间和空间消耗]
GPU消耗型任务
相对于 CPU 来说,GPU 能干的事情比较单一:接收提交的纹理(Texture)和顶点描述(三角形),应用变换(transform)、混合并渲染,然后输出到屏幕上。宽泛的说,【大多数 CALayer 的属性都是用 GPU 来绘制】。
以下一些操作会降低 GPU 绘制的性能,
大量几何结构
所有的 Bitmap,包括图片、文本、栅格化的内容,最终都要由内存提交到显存,绑定为 GPU Texture。不论是提交到显存的过程,还是 GPU 调整和渲染 Texture 的过程,都要消耗不少 GPU 资源。当在较短时间显示大量图片时(比如 TableView 存在非常多的图片并且快速滑动时),CPU 占用率很低,GPU 占用非常高,界面仍然会掉帧。
避免这种情况的方法只能是尽量减少在短时间内大量图片的显示,尽可能将多张图片合成为一张进行显示。
另外当图片过大,超过 GPU 的最大纹理尺寸时,图片需要先由 CPU 进行预处理,这对 CPU 和 GPU 都会带来额外的资源消耗。目前来说,iPhone 4S 以上机型,【纹理尺寸上限都是 4096x4096】,更详细的资料可以看这里:iosres.com。所以,尽量不要让图片和视图的大小超过这个值。
视图以及图层的混合
屏幕上每一个点都是一个像素,像素有R、G、B三种颜色构成(有时候还带有alpha值)。如果某一块区域上覆盖了多个layer,最后的显示效果受到这些layer的共同影响。举个例子,上层是蓝色(RGB=0,0,1),透明度为50%,下层是红色(RGB=1,0,0)。那么最终的显示效果是紫色(RGB=0.5,0,0.5)。
公式:
0.5 0 0.5
R = S + D * (1 - Sa) = 0 + 0 * (1 - 0.5) = 0
0 1 0.5
当多个视图(或者说 CALayer)重叠在一起显示时,GPU 会首先把他们混合到一起。如果视图结构过于复杂,混合的过程也会消耗很多 GPU 资源。为了减轻这种情况的 GPU 消耗,【应用应当尽量减少视图数量和层次,并且减少不必要的透明视图】
离屏渲染
离屏渲染是指图层在被显示之前,GPU在当前屏幕缓冲区以外新开辟一个缓冲区进行渲染操作。离屏渲染耗时是发生在离屏这个动作上面,而不是渲染。为什么离屏这么耗时?原因主要有创建缓冲区和上下文切换。创建新的缓冲区代价都不算大,付出最大代价的是上下文切换。
【上下文切换】
不管是在GPU渲染过程中,还是一直所熟悉的进程切换,上下文切换在哪里都是一个相当耗时的操作。首先我要保存当前屏幕渲染环境,然后切换到一个新的绘制环境,申请绘制资源,初始化环境,然后开始一个绘制,绘制完毕后销毁这个绘制环境,如需要切换到On-Screen Rendering或者再开始一个新的离屏渲染重复之前的操作。
【渲染流程】
我们先看看最基本的渲染通道流程:

我们再来看看需要Offscreen Render的渲染通道流程:
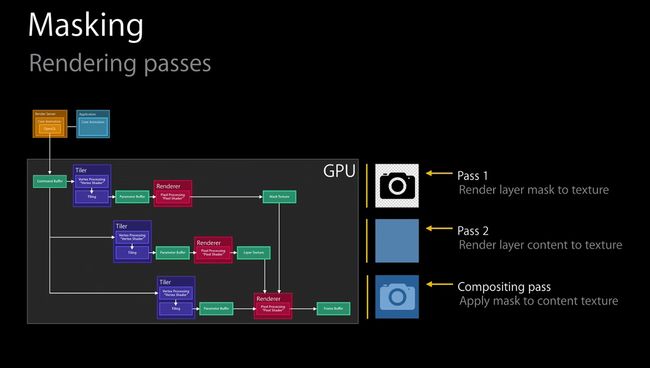
一般情况下,OpenGL会将应用提交到Render Server的动画直接渲染显示(基本的Tile-Based渲染流程),但对于一些复杂的图像动画的渲染并不能直接渲染叠加显示,而是需要根据Command Buffer分通道进行渲染之后再组合,这一组合过程中,就有些渲染通道是不会直接显示的;对比基本渲染通道流程和Masking渲染通道流程图,我们可以看到到Masking渲染需要更多渲染通道和合并的步骤;而这些没有直接显示在屏幕的上的通道(如上图的 Pass 1 和 Pass 2)就是Offscreen Rendering Pass。
Offscreen Render为什么卡顿,从上图我们就可以知道,Offscreen Render需要更多的渲染通道,而且不同的渲染通道间切换需要耗费一定的时间,这个时间内GPU会闲置,当通道达到一定数量,对性能也会有较大的影响;
【为什么会产生离屏渲染?】
首先,OpenGL提交一个命令到Command Buffer,随后GPU开始渲染,渲染结果放到Render Buffer中,这是正常的渲染流程。【但是有一些复杂的效果无法直接渲染出结果,它需要分步渲染最后再组合起来】,比如添加一个蒙版(mask)。
会造成 offscreen rendering 的原因有:
阴影(UIView.layer.shadowOffset/shadowRadius/…)
圆角(当 UIView.layer.cornerRadius 和 UIView.layer.maskToBounds 一起使用时)
图层蒙板(Mask)
开启光栅化(shouldRasterize = true,同时设置 rasterizationScale)
【Mask】
一个图层可以有一个和它相关联的 mask(蒙板),mask 是一个拥有 alpha 值的【位图】【不是矢量图,所以矢量图是不能作为遮罩】。只有在 mask 中显示出来的(即图层中的部分)才会被渲染出来。
使用阴影时同时设置 shadowPath 就能避免离屏渲染大大提升性能,圆角触发的离屏渲染可以用 CoreGraphics 将图片处理成圆角来避免。
CALayer 有一个 shouldRasterize 属性,将这个属性设置成 true 后就开启了光栅化。
【什么是光栅化】
光栅化其实是一种将几何图元变为二维图像的过程。
你模型的那些顶点在经过各种矩阵变换后也仅仅是顶点。而由顶点构成的图形要在屏幕上显示出来,除了需要顶点的信息以外,还需要确定构成这个图形的所有像素的信息。
【光栅化优缺点】
开启光栅化后会将图层绘制到一个屏幕外的图像,然后这个图像将会被缓存起来并绘制到实际图层的 contents 和子图层,对于有很多的子图层或者有复杂的效果应用,这样做就会比重绘所有事务的所有帧来更加高效。但是光栅化原始图像需要时间,而且会消耗额外的内存。
光栅化也会带来一定的性能损耗,是否要开启就要根据实际的使用场景了,图层内容频繁变化时不建议使用。最好还是用 Instruments 比对开启前后的 FPS 来看是否起到了优化效果。
离屏渲染请参考:iOS 离屏渲染的研究
参考资料:
1.iOS进阶之页面性能优化
2.绘制像素到屏幕上
3.iOS 保持界面流畅的技巧
4.如何正确地写好一个界面