作者:田逸([email][email protected][/email])
首发:[url]http://server.it168.com/server/2007-12-04/200712041012131.shtml[/url]
首发:[url]http://server.it168.com/server/2007-12-04/200712041012131.shtml[/url]
在linux环境下,开源工具Awstats是一个非常受欢迎的网站日志处理工具。在linux环境安装和配置awstats比较容易成功,但要同时处理多个apache日志(比如web集群的环境),还是有许多工作需要做的。
平台环境
1、 服务器3个,2个运行apache的web 服务器,一个专门处理日志的Awstats服务器。
2、 运行平台:全部为redhat AS 4。
设计思路
日志处理服务器每天定期从2个apache服务器获取日志文件,对取得的压缩文件解压,接着把2个单独的日志文件合并成一个,再用awstats处理生成报告。下面我们就按照这个思路来进行具体的部署。
一、Apache日志的生成和处理
1、 apache日志生成:
通过修改apache的配置文件 httpd.conf来达到这个目的,下面是某个apache服务器的配置文件关于日志记录的修改部分:
SetEnvIf Request_URI \.gif p_w_picpath-request
SetEnvIf Request_URI \.jpg p_w_picpath-request
SetEnvIf Request_URI \.png p_w_picpath-request
SetEnvIf Request_URI \.js p_w_picpath-request
SetEnvIf Request_URI \.css p_w_picpath-request
SetEnvIf Request_URI \.swf p_w_picpath-request
ErrorLog /var/log/web/sery.com-error_log
CustomLog "|/opt/apache2/bin/rotatelogs /var/log/web/sery.com-access%Y%m%d.log.%H 28800 480" combined env=!p_w_picpath-request
在这里简单说明一下上面各个项目的意义。SetEnvIf Request_URI设置判断环境变量“p_w_picpath-request”,“CustomLog "|/opt/apache2/bin/rotatelogs /var/log/web/sery.com-access%Y%m%d.log.%H 28800 480" combined env=!p_w_picpath-request
”表示不记图片请求所产生的日志,并且使用apache的日志轮转工具rotatelogs对日志进行分割,以年月日及小时方式命名文件,这样用脚本处理日志时就非常方便了。这个CustomLog有点特别,不要把命令前面的”|”等符号写丢了。通过运行apache服务,将在目录/var/log/web/生成日志文件sery.com-access20071120.log.00.
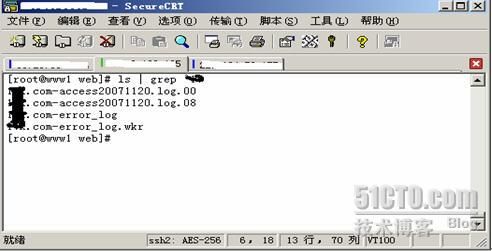
由于使用了日志轮转功能,从上图可以看见2个日志文件。
1、 日志备份和压缩:
进入日志所在的目录,把同一天不同时间段的日志合并成一个文件,压缩后移动到另外的一个位置/var/log/weblog-backup。为什么要把它放在另外的位置并且压缩呢?主要的原因是为了在传输时节省时间。当然我们不可能每天手动来执行这个操作,自然而言,用shell脚本来干这个事情了。下面给出脚本的内容:
|
#!/bin/sh
lastlogdate=`date "+%Y%m%d" -d yesterday`
touch /var/log/web/sery.com-access$lastlogdate.log
for i in /var/log/web/sery.com-access$lastlogdate.log.*
do cat $i >> /var/log/web/sery.com-access$lastlogdate.log
rm -f $i
done
touch /var/log/web/sery.com-access$lastlogdate.log
gzip /var/log/web/sery.com-access$lastlogdate.log
if [[ -f /var/log/web/sery.com-access$lastlogdate.log.gz ]]
then
mv /var/log/web/sery.com-access$lastlogdate.log.gz /var/log/weblog-backup/
fi
rm -rf `find /var/log/weblog-backup/ -atime 7`
|
把这个脚本命名为merge_log.sh,放在目录/usr/local/bin下面,并赋予执行权限。然后在自动任务里加入这个任务,让它每天自动执行一次。运行crontab –e 把下面的行加入其中:
|
5 0 * * * /usr/local/bin/merge_log.sh
|
为检查脚本的正确性,至少手动执行一遍脚本merge_log.sh,看是否在目录/var/log/weblog_backup生成压缩文件。如果如愿生成类似 sery.com-access20071119.log.gz这样的文件,表明脚本正确地按照我们的意图工作了。
2、 允许awstats取得apache的日志文件:
部署ftp服务,创建一个ftp用户,然后把这个ftp的用户目录定位到“/var/log/weblog-backup”,即第2步生成压缩文件的目录。使用下列的命令产生ftp用户和指定目录:
|
[root@www1 ~]# useradd –d /var/log/weblog-backup -s /sbin/nologin sery
[root@www1 ~]# passwd sery
[root@www1 ~]# chmod 755 –R /var/log/weblog-backup
|
由于vsftpd配置非常容易,这里就不再多说。启用ftp服务,用刚才创建的用户测试一下,看是否可以看见“/var/log/weblog_back”里的文件。
到这一步,我们需要在apache服务器上进行的操作就结束了。多个apache服务器,只需要重复上面的操作即可。当然,为了适应你自己的环境,请自行修改相关的目录和文件。
一、获取日志文件
是awstats服务器从apache服务器取得日志文件,在本案中,我将从2个apache服务器取得日志文件。取日志也是每天自动进行一次。有一点必须注意,那就是必须要等“第二步”操作正常结束后再进行取日志;回过头去看“第二步”的“/usr/local/bin/merge_log.sh”执行时间在00:05分,考虑执行程序的开销,估计1小时左右可以完成这个操作,所以在凌晨2点去取文件是合时的。下面给出取日志的脚本:
|
#
!/bin/bash
wget --active-ftp -m --directory-prefix=/root/logs/web1/ --tries=3\ --output-file=/root/script/weblog-get.log\ [url]ftp://sery:[email protected]/sery[/url]*.gz
wget --active-ftp -m --directory-prefix=/root/logs/web2/ --tries=3\
--output-file=/root/script/weblog-get.log \
[url]ftp://sery:[/url] [email][email protected][/email]/sery*.gz
|
脚本成功运行后,将把第一个apache服务器的日志文件放在”/root/logs/web 1” 目录,第2个apache服务器的日志文件放在”/root/logs/web 2” 目录,并且把操作日志记录到文件“/root/script/weblog-get.log”,以方便检查脚本执行的状况。把这个脚本放在目录/usr/local/bin下,命名为weblog-get.sh,赋予执行权限,然后手动运行脚本/usr/local/bin/weblog-get.sh,看是否取得了远程apache服务器的2个压缩日志文件。正确无误后,把它加在crontab 里。
|
crontab –e
00 02 * * * /usr/local/bin/weblog-get.sh
|
每天凌晨2点,awstats所在的服务器就会主动从2个远程的apache服务器取来日志文件。
二、日志合并(在awstats服务器上进行):
由于用ftp取得的日志文件有多个(本案是2个),不便于处理,因此很有必要对日志进行解压和合并。处理使用下面的脚本来完成:
|
#!/bin/bash
#define variables
AwsLogDir=/root/logs/awstats_log
Web1Log=/root/logs/web1
Web1OrigLog=$Web1Log/sery.com-access$(date +%Y%m%d --date='1 days ago').log.gz
Web2Log=/root/logs/web2
Web2OrigLog=$Web1Log/sery.com-access$(date +%Y%m%d --date='1 days ago').log.gz
OldFile=/root/logs/awstats_logs/sery.com-access$(date +%Y%m%d --date='4 days ago').log*
#########################################################################
#get logfiles
cd $Web1Log
if [[ -f $Web1OrigLog ]]
then
gunzip -d $Web1OrigLog
fi
FileLog1=sery.com-access$(date +%Y%m%d --date='1 days ago').log
if [[ -f $FileLog1 ]]
then
mv sery.com-access$(date +%Y%m%d --date='1 days ago').log $AwsLogDir/17k.com-access$(date +%Y%m%d --date='1 days ago').log.1
fi
cd $Web2Log
if [[ -f $Web2OrigLog ]]
then
gunzip -d $Web2OrigLog
fi
FileLog2=sery.com-access$(date +%Y%m%d --date='1 days ago').log
if [[ -f $FileLog2 ]]
then
mv sery.com-access$(date +%Y%m%d --date='1 days ago').log $AwsLogDir/sery.com-access$(date +%Y%m%d --date='1 days ago').log.2
fi
#########################################################################
# conbine two web logs to one
cd $AwsLogDir
File1Log=sery.com-access$(date +%Y%m%d --date='1 days ago').log.1
File2Log=sery.com-access$(date +%Y%m%d --date='1 days ago').log.2
if [[ -f $File1Log && -f $File2Log ]]
then
cat $File1Log $File2Log >sery.com-access.log
fi
if [[ -f $OldFile ]]
then
rm $OldFile
fi
|
上述脚本正常运行后,将在/root/logs/awstats目录生成文件sery.com-access.log,这个文件正是awstats所需要的。如果从更多apache服务器取来更多日志文件,上述脚本需要更改才能简洁高效。方法是—用循环方式生成那个sery.com-access.log文件。
三、配置awstats系统
1、 安装awstats。
|
(1) 下载awstats
wget [url]http://downloads.sourceforge.net/awstats/awstats-6.7.tar.gz?modtime=1183813789&[/url]
big_mirror=0
(2) 解压
tar xvf wstats-6.7.tar.gz
mv awstats-6.7 /usr/local/awstats
|
awstats需要apache协同工作,请自行安装之。Apache安装好以后,运行命令/usr/local/apache/bin/httpd –l | grep mod_cgi.c 看是否把模块编译进来,这个模块是必须的。接着再检查perl工具是否被安装到系统,如果没有安装,请手动安装。
2、 配置awstats。
|
cd /usr/local/awstats/tools
执行配置脚本,这是一个交互程序,可根据自己的实际情况回答
perl awstats_configure.pl
----- AWStats awstats_configure 1.0 (build 1.7) (c) Laurent Destailleur -----
This tool will help you to configure AWStats to analyze statistics for
one web server. You can try to use it to let it do all that is possible
in AWStats setup, however following the step by step manual setup
documentation (docs/index.html) is often a better idea. Above all if:
- You are not an administrator user,
- You want to analyze downloaded log files without web server,
- You want to analyze mail or ftp log files instead of web log files,
- You need to analyze load balanced servers log files,
- You want to 'understand' all possible ways to use AWStats...
Read the AWStats documentation (docs/index.html).
-----> Running OS detected: Linux, BSD or Unix
-----> Check for web server install
Found Web server Apache config file '/usr/local/apache2/conf/httpd.conf'
-----> Check and complete web server config file '/usr/local/apache2/conf/httpd.conf'
-----> Update model config file '/usr/local/awstats/wwwroot/cgi-bin/awstats.model.conf'
File awstats.model.conf updated.
-----> Need to create a new config file ?
Do you want me to build a new AWStats config/profile
file (required if first install) [y/N] ?
|
执行完配置后,将生成配置文件/etc/aswstats/ awstats.sery.conf,修改
|
LogFile=/root/logs/awstats_log/17k.com-access.log
|
然后再执行 perl /usr/local/awstats/wwwroot/cgi-bin/awstats.pl -config=sery.com –update 如果没有错误的话,在浏览器输入awstats服务器的ip地址即可得到访问日志报告。我们不想无关的人看见日志报告,用apache用户验证功能来完成,把下面的内容加入到apache配置文件httpd.conf即可:
Alias /awstatsclasses "/usr/local/awstats/wwwroot/classes/"
Alias /awstatscss "/usr/local/awstats/wwwroot/css/"
Alias /awstatsicons "/usr/local/awstats/wwwroot/icon/"
ScriptAlias /awstats/ "/usr/local/awstats/wwwroot/cgi-bin/"
AuthType Basic
Options ExecCGI
AllowOverride None
Order allow,deny
Allow from all
AuthName "17k awstats Access"
AuthUserFile /usr/local/awstats/.htpasswd
Require valid-user
把awstats更新加入 crontab,让它每天自动执行一次。
|
crontab –e
00 06 * * * /usr/local/bin/awstats_update.sh
|
脚本/usr/local/bin/awstats_update的内容:
#!/bin/bash
perl /usr/local/awstats/wwwroot/cgi-bin/awstats.pl -config=sery.com -update >> /usr/local/awstats/awstats_update.log
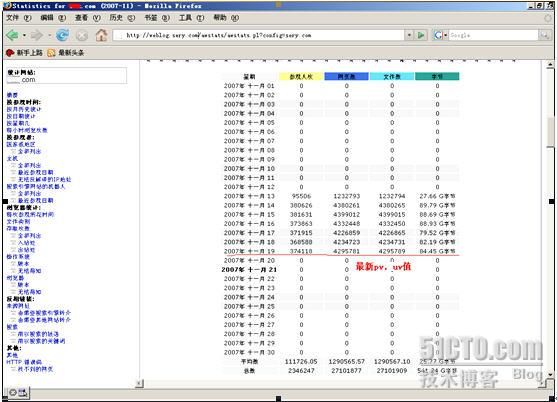
每天早上6点会自动执行一次更新操作,对日志文件进行处理,最后在浏览器里读出所需数据。
输入正确的用户名和密码