随着公司业务的发展,想必各位都或多或少遇到过服务过多日益混乱的情况,刚开始的做法不再适用于当前的规模。所以我们决定将关于服务治理的一些实践分享出来,相互交流学习。
在ezbuy我们也遇到类似的问题,首先介绍一下我们使用Go的背景:
- 由于Go先天缺少范型支持,而我们的业务有很多相似的地方。所以我们大量使用了代码生成,比如数据库ORM,进程间rpc以及跨语言的公开api调用(手机app,web等),从而避免重复劳动
- 负责项目开发的人负责自己的项目。相应的人可以通过运维开发的系统 更新/重启 自己线上的 Go 程序,二进制文件由开发人员自己上传到svn,再用程序通知线上机器从svn拉取。
- 在线上,我们使用双机部署策略,每个服务默认会在两台机器都部署一份,当程序更新时,会先用 supervisor 统一重启一台机器的服务,再重启另一台,从而达到不停机更新的目的。
- 项目的第三方依赖采用glide来管理
可以看出,很多东西我们都是怎么简单怎么来。但是当后面服务、仓库数一多,就暴露出一些问题:
- 感受最深的是在新人刚接触项目的时候,需要下载大量的第三方包。国内的环境大家都懂的,那时候用了整整一个下午我才能够把第三方包下载完。而且项目与项目之间的第三方库不能相互共享,因为glide会改变第三方库的版本,如果两个库采用的版本不一致,就会导致版本切来切去。
- 项目结构相当分散,约束力全靠人工。这样一样,比如说配置文件的位置,就我看过的就有4种命名方式,想做自动化完全不可行。
- 我们定义接口文件并没有和项目相关联。这样一来,在项目内,可以知道这个项目实现了哪个接口,但是通过接口,不能知道由哪个项目实现,从而无法找到对应哪个代码仓库。而如果出现问题,对于不熟悉这个业务的人(值班或测试人员)所能知道的只有接口名字,或者某人想要了解某一部分的逻辑,他所能找到的只有入口,如果无法直接通过接口推断出具体的代码位置,那就只能去问人了。
- 数据没有隔离。通过上面背景的交代,我们是通过一个叫 ezorm 的工具来生成数据 orm 代码,而他依赖的其实就是一个yaml文件去定义数据库的schema。这样当多个项目同时需要共享同一个数据源的时候,问题就演变成为了怎么在多个repo共享一个yaml文件的问题。但在实践中,常常出现一方修改yaml后另一方没办法及时更新,导致脏数据出现。
- 代码生成过程混乱。背景提到,我们大量使用了代码生成,实际中,我们最大的项目包含了上百行的生成命令(bash),全部都是人工手写。人的思想总是在变,项目又有多个人在进行开发,这样一来,生成的目录相当不统一,命名也是不规范。而且每次在新增业务的时候,都会去上面copy一下生成代码,完全是没必要。
- 编译过程没有集中化,无法重现。编译过程分散在不同的环境,一旦出现问题,其他人无法直接干预与排查。并且编译所在的机器如果要使用最新的工具链进行编译,就必须自己每次都去获取更新,而工具链的更新是持续性的,一般情况下人都不会主动拉取更新,导致工具链的更新反馈到实际项目非常麻烦。
goflow
从问题来看,第一眼能够感觉到缺少一个统一的机制,可以让每个人可以处于一个相对一致的环境。据笔者之前所经历的公司(均为使用Go的创业公司),没有见过一家让这一体系规范化,导致每个人各有各的环境,在推进一些机制的时候需要额外得去解决各种各样环境下引起的问题,新人进来需要一段时间去适应和搭建环境,甚至创建自己的规范。
所以,我们第一步是统一使用环境,这套环境我们称之为 goflow。goflow在设计的时候,会考虑以下几个因素:
- 开发环境和编译环境都会使用这套环境,我们开发基本使用的是mac(正式员工如果没有公司会帮忙配一台),所以支持的操作系统只需要是linux和macOS
- goflow需要能够容纳全部公司项目,并且能够与个人项目相互独立同时存在。
- goflow本身也是一套工具集,也会持续开发,所以本身需要有方便的升级方案。
- 所有项目应该都在goflow环境下使用(编译),goflow本身应该需要零依赖。
- goflow应该是一套在命令行下工作的工具。
- goflow应该兼容go官方本身推荐的项目结构。
根据以上特征,初步敲定使用bash来编写,可以很方便得编写各种命令,并且侵入进环境内。为了方便定位,所有goflow命令均以 ez 开头。

在安装上,只需要在clone项目后,在 bash_rc 加入 source ezbuy.sh 这样一行就可以了。

但是为了不对现有环境造成太大的环境污染,默认并不会执行任何命令,修改任何环境变量,只是添加了几个进入goflow的快捷命令。比如上图中的ezhome,是进入goflow的入口命令,在执行入库命令后,goflow会认为当前terminal的session都会被goflow接管,会尝试写入各种环境变量(GOPATH)。为了能够有一个一目了然的引导提示当前session被goflow接管了,会打印一个大大的 “ezbuy”,生成于这里.
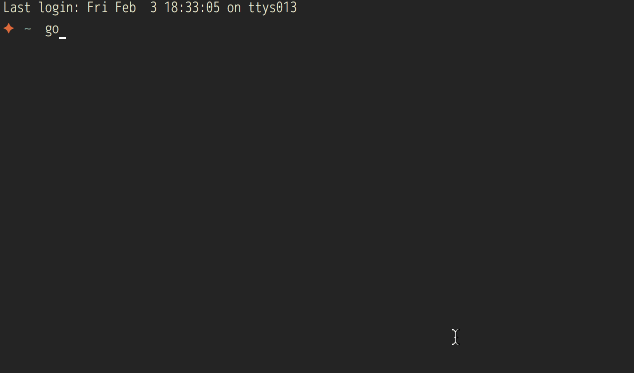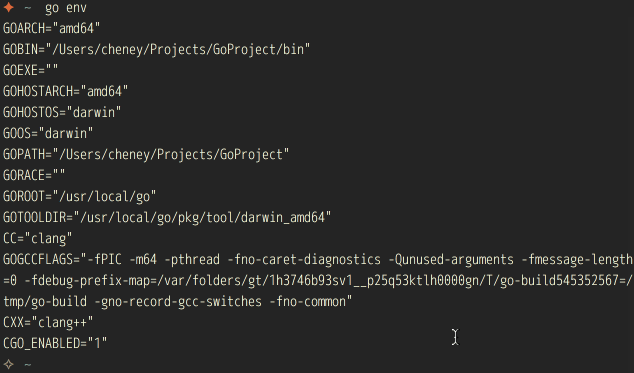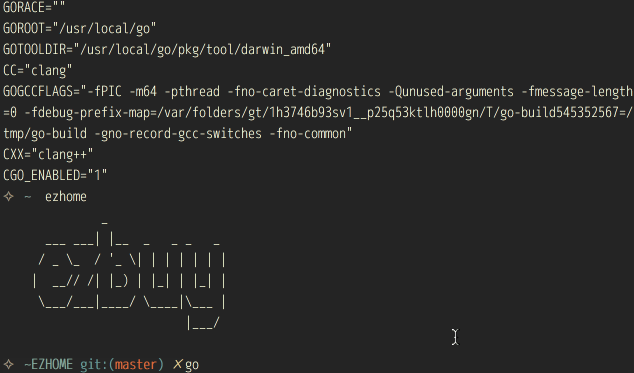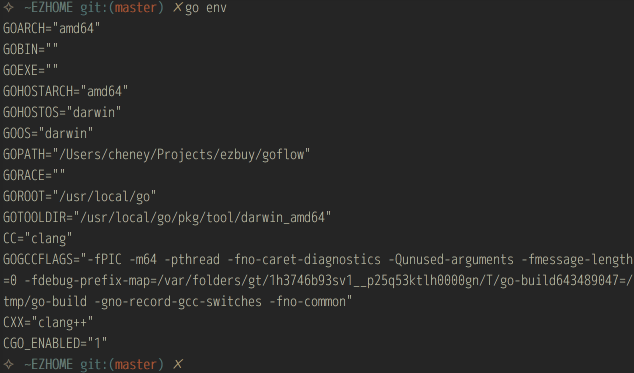

从目录结构可以看出,goflow就只是一个独立的GOPATH,完全遵循go本身的项目结构。所有的项目会放置在 src/ 目录下,二进制文件均放在 bin 下。scripts存放goflow本身的扩展bash脚本。而goflow下的bin目录也是加入到 PATH 环境下。
所以,在goflow下,各种编辑器都能有很好的支持,没有太多的黑魔法。同时,goflow又是一个很好的切入点,可以让工具可以植入到各位的机器当中。
依赖管理
虽然理论上可以让每个代码仓库管理各自的依赖,这样一来如果让所有仓库共享一份依赖逻辑上就会存在问题。那为了能够让全部仓库共享一份第三方库依赖,就需要让所有仓库使用同一个依赖库版本基线,仔细想想这个做法并没有什么毛病... 而且共享一份依赖对于编译速度也是节省很多。
接下来,就是要将代码存放在goflow的哪个地方。传统的做法,比如直接通过go get获取的,他会直接放到 src 下面,与我们自己的代码在一起。这样显得比较混乱,也比较难管理。然而说到go的依赖管理,都会想起 vendor 机制,vendor机制特别简单:
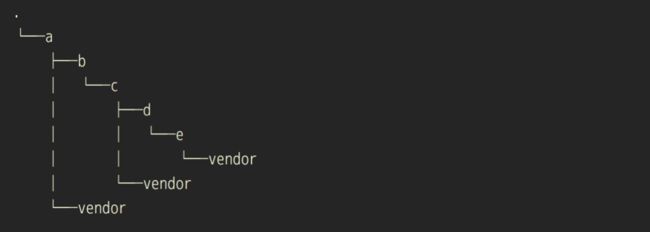
vender目录可以认为是另一个GOPATH下的src,比如 /a/vendor/github.com/ezbuy/ezorm, 在作用范围内的go代码的引入路径,会优先改写成vendor里面存在路径,即 github.com/ezbuy/ezorm -> /a/vendor/github.com/ezbuy/ezorm. 那怎么算作用范围呢?那就是vendor所在目录下面的所有目录。比如 /a/vendor 可以在 /a, /a/b, ... 下使用。当在多个vendor内同时存在一样引入路径时,则选路径最长的。
所以,那我们就可以将所有的依赖库放到vendor目录下来达到管理的目的,那vendor目录放哪里呢?假设我们现在代码放在 ezbuy.com 下,对应的路径

这样,我们只要创建一个名字叫 vendor 的git仓库就可以了,甚至可以直接用 go get 直接获取。
剩下的问题,就是如何将第三方库放到一个git仓库中,也就是如何在一个git仓库引用其他git仓库,甚至是hg仓库的问题。在git中,有subtree和submodule两种方案,都能达到目的。当然在使用上也有一些差别:
submodule不会将子仓库存下来,而是仅仅储存一个版本。然后需要在用户执行 git submodule update 的时候再分开拉取。而subtree则直接将这些仓库的commit提交该仓库中(可以合并成一个commit)
上面是直观的差别,还有一些pull和push的差别,理论上subtree是通过一堆bash脚本来模拟管理git仓库,而submodule本身就是git仓库。笔者主观上都能够接受,因为submodule需要的额外操作可以由goflow来完成,并没有到很麻烦的地步,反而能够节省空间(远程)。所以最开始我是使用submodule来做的,讽刺的是最后vendor库做完竟然在本地占用了1G的空间(在.git/module目录),而使用subtree则只有80M,所以我们在最后的选择上使用了subtree。刚刚查了一下,vendor有220M,如果在公司内用5Gwifi网络下载(20MB/s),新人只要十几秒就能全量下载,马上就能够搭建完开发环境。
与goflow的结合
vendor库也是会持续更新,包括每个人都可以去添加第三方库。所以我们让vendor和goflow是绑在一起的,在初始化goflow的时候会全量下载,在goflow更新时同时更新vendor。还有一些工具链,比如ezorm,都是直接添加到vendor库里面,在goflow更新时,会去尝试增量更新这些工具,并且存放到goflow下的bin目录,最终达到goflow更新时能够让所有的工具链能够更新。
持续集成
上面说到,之前编译行为是在每个人的机器上面完成的,想要让其集中化。从大一点的方面来想,这个其实属于持续集成的范畴。比较理想的流程是只要代码一进入master,通过webhook触发各种编译动作,生成二进制文件,部署到线上。然后说到持续集成,我们还需要有一个测试环境,而测试环境应该允许存在还未进入master的代码。
鉴于此,对于git仓库,我们会定义几种分支类型:
- master: 要发布的代码合并进来,当有新代码进入时,会触发CI编译并且部署上线
- feature/xxx:业务分支
- test:测试分支
开发流程是这样:
对于不同的业务,在不同的feature上开发,开发过程中,在进行测试的时候,将自己的feature合并到test分支,触发测试环境编译与更新。如果发现bug,继续在feature上开发,然后持续把自己feature分支合并到test分支来达到测试的目的。对于项目引用到一些submodule的库,也会有相应的test分支,确保test分支的submodule也是落在test分支上。当开发完成后,对feature分支进行rebase master,review完合并进master完成上线。对于test分支,需要定期通过merge master来更新,他甚至可以被 reset --hard master 。test的作用在于可以让多人在同一个测试环境进行。
对于CI,我们使用jenkins搭建,我们把测试环境和线上环境分开成两个目录,也就是两个goflow环境,两个环境是同时存在并且相互独立。gitlab可以通过webhook通知到jenkins
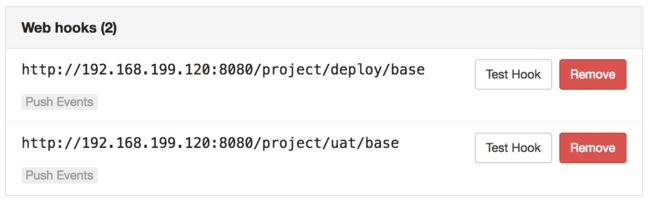
对于进入test分支的代码,在编译完成后,打包二进制文件到docker,重启docker实例。对于进入master的代码,会在编译完成后,上传到svn(还是沿用原来的方案),触发线上部署。
goflow工具集
goflow本身提供了一些快捷命令,比如上文提到的 ezhome,他后面可以加参数来快速跳转到某个项目(支持补全),如果什么都不加,则跳转到goflow目录
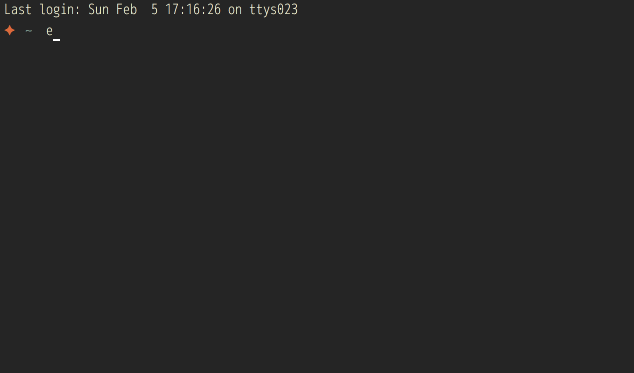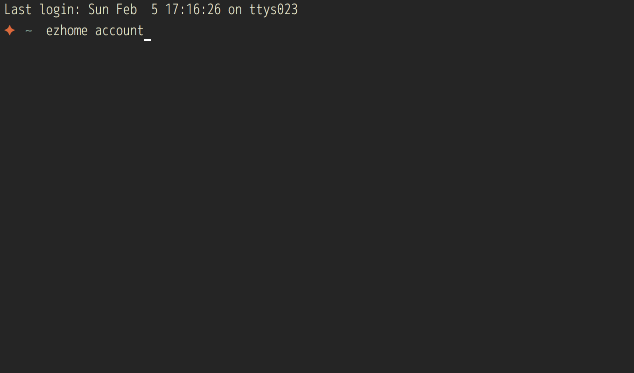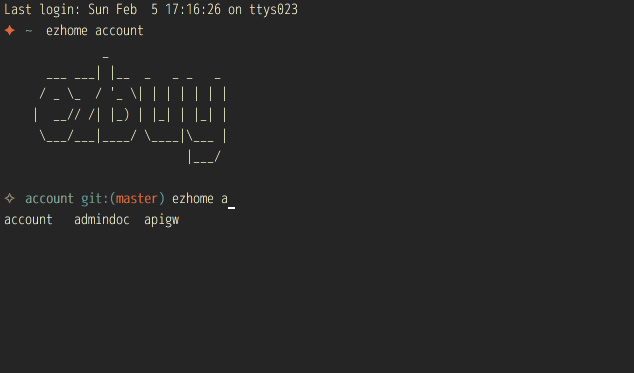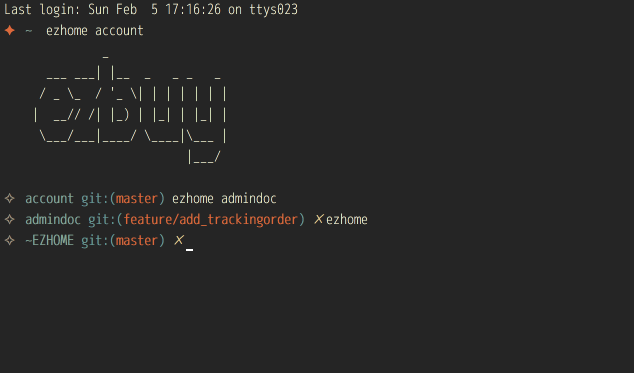
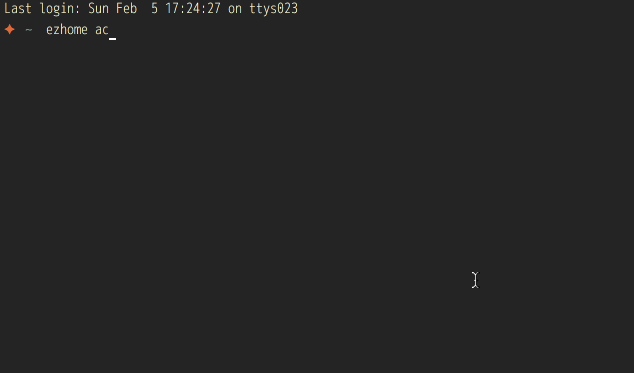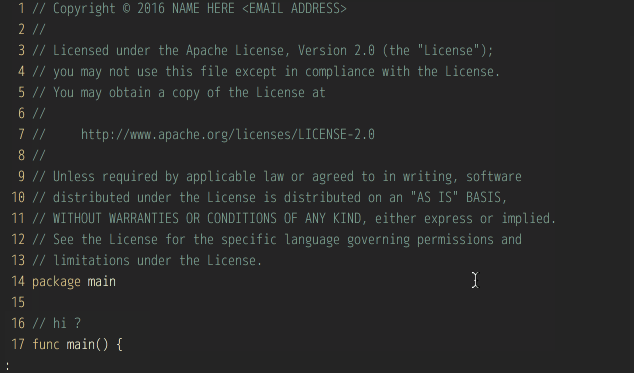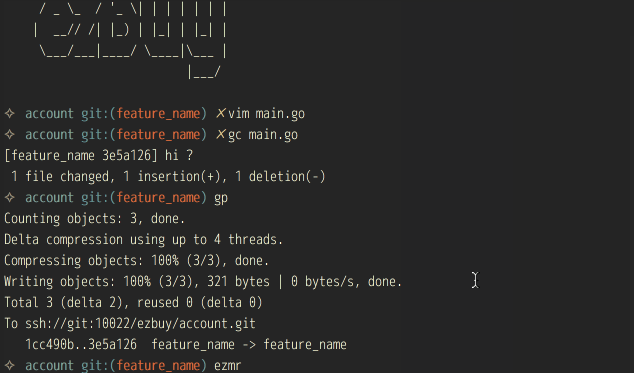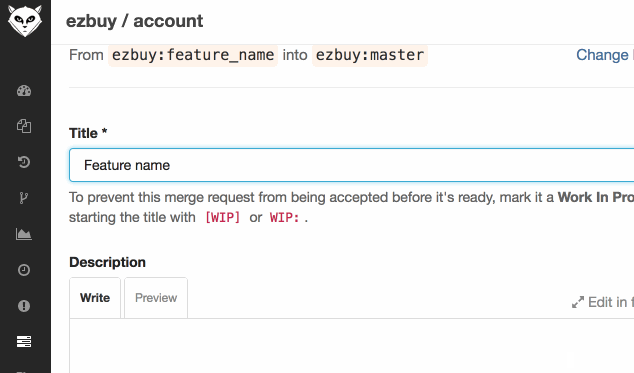
还有一个用的比较多的是快速提交mr,如果你们公司也有类似的流程,那我们可以重新开一个terminal窗口来比较一下效率, :)
关于环境的大概就这么多,下一篇我们将介绍关于微服务化的一些实践与心得,敬请期待。