概述
对于逃逸分析和TLAB两种技术之间的关联一直没有理清楚,今天抽时间专门整理了一下这两门技术。
通过这篇文章,我们可以了解到什么:
- 对象的分配流程
- 对象在年轻代是采用什么算法进行内存的分配
- 什么是逃逸分析技术
- 逃逸分析和TLAB两门技术的结合,提高JVM虚拟机性能
- 编译器和解释器的混合模式
TLAB
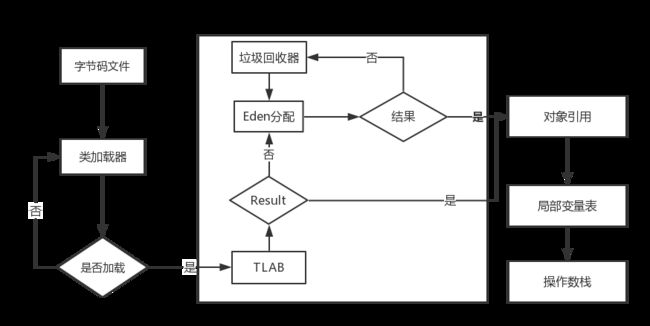
我们都知道对象是在堆区中为对象分配内存,并且堆区被多个线程共享(JVM采用共享内存模型),当多个线程同时进行 new 操作时,需要通过同步操作保证数据的正确。在JVM虚拟中先尝试通过CAS操作为对象分配内存,如果分配不成功才会尝试获得堆区的锁,进行对象的分配
- CAS分配
if (gen0->should_allocate(size, is_tlab)) {//对大小进行判断,比如是否超过eden区能分配的最大大小
result = gen0->par_allocate(size, is_tlab);///while循环+指针碰撞+CAS分配
if (result != NULL) {
assert(gch->is_in_reserved(result), "result not in heap");
return result;
}
}
- 对堆区进行加锁
............省略.............
MutexLocker ml(Heap_lock);//锁
if (PrintGC && Verbose) {
gclog_or_tty->print_cr("TwoGenerationCollectorPolicy::mem_allocate_work:"
" attempting locked slow path allocation");
}
// Note that only large objects get a shot at being
// allocated in later generations.
//需要注意的是,只有大对象可以被分配在老年代。一般情况下都是false,所以first_only=true
bool first_only = ! should_try_older_generation_allocation(size);
//在年轻代分配
result = gch->attempt_allocation(size, is_tlab, first_only);
if (result != NULL) {
assert(gch->is_in_reserved(result), "result not in heap");
return result;
}
通过同步操作虽然保证了内存分配的正确性,但是却限制了对象分配的效率,JVM通过TLAB来减少了同步的操作,TLAB全称是ThreadLocalAllocBuffer,这块内存是从堆空间中划分出来给线程管理。TLAB数据结构如下:
class ThreadLocalAllocBuffer: public CHeapObj {
HeapWord* _start; // address of TLAB
HeapWord* _top; // address after last allocation
HeapWord* _pf_top; // allocation prefetch watermark
HeapWord* _end; // allocation end (excluding alignment_reserve)
size_t _desired_size; // desired size (including alignment_reserve)
size_t _refill_waste_limit; // hold onto tlab if free() is larger than this
.....................省略......................
}
TLAB空间主要有3个指针:_start、_top、_end。_start指针表示TLAB空间的起始内存,_end指针表示TLAB空间的结束地址,通过_start和_end指针,表示线程管理的内存区域;
当进行对象的内存划分的时候,就会通过移动_top指针分配内存(TLAB,Eden,To,From 区主要采用指针碰撞来分配内存(pointer bumping)),在TLAB空间为对象分配内存需要遵循下面的原则:
- obj_size + tlab_top <= tlab_end,直接在TLAB空间分配对象
- obj_size + tlab_top >= tlab_end && tlab_free > tlab_refill_waste_limit,对象不在TLAB分配,在Eden区分配。(tlab_free:剩余的内存空间,tlab_refill_waste_limit:允许浪费的内存空间)
- obj_size + tlab_top >= tlab_end && tlab_free < _refill_waste_limit,重新分配一块TLAB空间,在新的TLAB中分配对象
按照上面的规则,如果对象先TLAB划分失败,那么对象会在Eden空间划分对象,首先尝试CAS方式,如果失败,通过同步加锁的方式进行分配,下面是 new 一个对象的流程图:
逃逸分析
逃逸分析技术是当虚拟机采用编译器执行代码的一种优化方案。
逃逸分析主要是分析对象的作用域,如果一个变量的作用域在方法体内,并且没有将该变量赋给方法体外的变量,那么这个对象就没有发生逃逸现象,为了提高性能,在栈上分配该对象的内存,当栈帧从Java虚拟机栈中弹出,就自动销毁这个对象。减小垃圾回收器压力。
编译器根据逃逸分析的结果,会对程序进行优化:(参考:《深入理解Java虚拟机》)
- 栈上分配:如果确定一个对象不会逃逸出方法之外,那么让对象在栈上分配内存,对象所占用的内存空间就可以随着栈帧的出栈而销毁
- 同步消除:如果逃逸分析能够确定一个变量不会逃逸出线程,无法被其他线程访问,那么这个变量的读写就不会有竞争,对这个变量的同步操作可以消除
- 标量替换:如果逃逸分析确认一个对象的内存结构不需要连续,并且可以拆散,那么创建他的成员变量来代替对象的创建。
接下来通过一个案例来测试采用逃逸分析和不采用逃逸分析得到得结果,参考代码如下:
public class EscapeAnalysis {
private static class Foo {
private int x;
private static int counter;
public Foo() {
x = (++counter);
}
}
public static void main(String[] args) {
long start = System.nanoTime();
for (int i = 0; i < 1000 * 1000 * 10; ++i) {
Foo foo = new Foo();
}
long end = System.nanoTime();
System.out.println("Time cost is " + (end - start));
}
}
不开启逃逸分析
程序参数如下:
-server -verbose:gc -XX:-DoEscapeAnalysis -XX:-UseTLAB -Xmx20m -Xms20m -Xmn10m
程序打印的日志:
[GC (Allocation Failure) 8191K->792K(19456K), 0.0018773 secs]
[GC (Allocation Failure) 8984K->696K(19456K), 0.0010031 secs]
[GC (Allocation Failure) 8888K->784K(19456K), 0.0009671 secs]
[GC (Allocation Failure) 8976K->728K(19456K), 0.0009667 secs]
[GC (Allocation Failure) 8920K->712K(19456K), 0.0009643 secs]
[GC (Allocation Failure) 8904K->744K(19456K), 0.0007664 secs]
[GC (Allocation Failure) 8936K->632K(19456K), 0.0009849 secs]
[GC (Allocation Failure) 8824K->632K(18432K), 0.0005136 secs]
[GC (Allocation Failure) 7800K->632K(18944K), 0.0006147 secs]
[GC (Allocation Failure) 7800K->632K(18944K), 0.0003694 secs]
[GC (Allocation Failure) 7800K->632K(18944K), 0.0004741 secs]
[GC (Allocation Failure) 7800K->632K(18944K), 0.0003157 secs]
[GC (Allocation Failure) 7800K->632K(18944K), 0.0005349 secs]
[GC (Allocation Failure) 7800K->632K(18944K), 0.0003457 secs]
[GC (Allocation Failure) 7800K->632K(18944K), 0.0011141 secs]
[GC (Allocation Failure) 7800K->632K(19456K), 0.0007234 secs]
[GC (Allocation Failure) 8312K->632K(18944K), 0.0005562 secs]
[GC (Allocation Failure) 8312K->632K(19456K), 0.0004954 secs]
[GC (Allocation Failure) 8824K->632K(19456K), 0.0008478 secs]
[GC (Allocation Failure) 8824K->632K(19456K), 0.0004709 secs]
Time cost is 153997979
开启逃逸分析
程序参数如下:
-server -verbose:gc -XX:+DoEscapeAnalysis -XX:-UseTLAB -Xmx20m -Xms20m -Xmn10m
程序打印的日志:
Time cost is 6618854
根据打印出来的日志,明显的看出开启逃逸分析以后,性能提高了很多,而且也减少了GC的压力。
逃逸分析与TLAB结合
经过逃逸分析,发现对象发生了逃逸,那么对象就会在年轻代进行分配,分配的流程和我们之前的分析的对象分配流程一致。通过结合逃逸分析技术和TLAB,提高了对象分配的性能,减少了GC的压力。
扩展
在上一小节,当我们开启了逃逸分析,打印的日志就只有程序执行的时间,如果我们调小启动参数中年轻代的内存,会发现一个有趣的现象。
程序参数如下:
-server -verbose:gc -XX:+DoEscapeAnalysis -XX:-UseTLAB -Xmx20m -Xms20m -Xmn3m
程序打印的日志:
[GC (Allocation Failure) 2047K->652K(19968K), 0.0011765 secs]
Time cost is 7006804
从上面的日志中我们可以看到有GC日志,为啥会有GC呢??我们明明开启的逃逸分析,按理来说,应该会在栈上分配对象的啊。下面将回答这个问题
我使用的是JDK1.8,默认使用混合模式,你可以会问:什么是混合模式?
在Hotspot中采用的是解释器和编译器并行的架构,所谓的混合模式就是解释器和编译器搭配使用,当程序启动初期,采用解释器执行(同时会记录相关的数据,比如函数的调用次数,循环语句执行次数),节省编译的时间。在使用解释器执行期间,记录的函数运行的数据,通过这些数据发现某些代码是热点代码,采用编译器对热点代码进行编译,以及优化(逃逸分析就是其中一种优化技术)现在我们知道了什么是混合模式,但是我们怎么知道我们的JDK采用了混合模式呢?
在windows系统中,我们通过cmd命令进行命令行窗口,执行命令
java -verion
执行结果:
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
//mixed mode 表示用的混合模式,interpreted mode 表示使用解释器, compiled mode 表示采用编译器
为什么会有GC日志?
在程序启动初期,我们使用的解释器执行,使用解释器执行没有逃逸分析的技术,因此对象在年轻代进行分配,关于对象的分配和我们上面的分析流程一致,当年轻代空间不足,就会触发GC,关于对象的创建以及GC的触发可以参考我的文章:http://www.jianshu.com/p/941fe93d21c2
使用解释器执行,积累的程序执行的相关数据,使用编译器对热点代码进行编译,并且采用逃逸分析技术进行优化。对象将在栈上分配,随着栈帧的出栈而消亡。只使用编译器执行上面的代码会是什么效果?
启动参数:
-server -Xcomp -verbose:gc -XX:+DoEscapeAnalysis -XX:-UseTLAB -Xmx20m -Xms20m -Xmn3m
程序打印的日志:
Time cost is 144426438
对比上面的日志,我们发现使用的时间多了两个数量级,而且没有GC日志,为什么呢?
没有GC日志是因为程序使用编译器来执行程序,并进行了逃逸分析的优化操作;时间多了两个数量级是因为编译器编译的过程缓慢,今天先来点开胃小菜,接下来将写其他的文章来讲解编译器和解释器的混合。
参考资料
http://blog.csdn.net/yangzl2008/article/details/43202969
http://blog.csdn.net/yangzl2008/article/details/43202969
结尾
就写到这里了,先逃了,如果发现文章的错误,请留言指出,大家一起进步,谢谢!!!!。
自我介绍
我是何勇,现在重庆猪八戒,多学学!!!