写在前面的话
前面的主从,HA 都只是解决我们数据安全性方面的问题,并没有解决我们业务瓶颈的问题。当业务并发到达一定瓶颈的时候,我们需要对服务进行横向扩展,而不是纵向扩展。这就需要引入另外一个东西,Redis Cluster。
关于 Redis Cluster
为什么 Redis 集群能提升性能:
1. Redis 能够提供 16384 个槽位用于存储数据,在主从或者单节点架构中,这些槽位只能分布在一个节点上,Cluster 能够对这个槽位进行分片。
2. 存数据时,会将 KEY 做 CRC16 加密,然后与 16384 取模,这样得到值就在 0 - 16383 之间,然后将 KEY 放入响应的槽位。
3. 客户端连接节点如果不是想访问的槽位节点,集群会将客户端连接到想访问的节点进行数据处理。
集群规划:
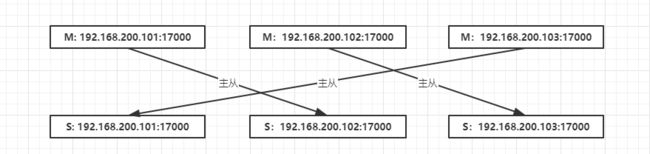
这里采用交叉构建主从的方式,其目的在于即使某台机器挂掉,至少那个切片节点还有其它服务器可以提供访问。
当然,该结构如果挂了两台服务器就另说,那就需要 6 台或者更多继续扩展,这里只是提供一个方案。
搭建 Redis Cluster
安装 Redis Cluster 官方提供了相关的脚本,但是需要 ruby 环境:
网上大多文档使用 epel 源安装的 Ruby 在 CentOS 中都是 2.0 版本,而安装 Redis 插件需要 2.2+ 版本。需要使用其它方法:
# 下载安装rvm curl -L get.rvm.io | bash -s stable source /usr/local/rvm/scripts/rvm # 查看可供安装的版本 rvm list known # 安装ruby 2.3 rvm install 2.3 # 查看版本 ruby --version # 安装Redis插件 gem install redis -v 3.3.3
注意,这里不能安装 4 版本,会有 BUG!!!!
在执行 curl 的时候可能报错,只需要执行报错中的命令,再执行 curl 即可:

如果本机已经安装了其它 ruby 版本,如 2.0,可以卸载:
rvm remove 2.0
1. 在三台机器都执行以下命令,搭建6个redis节点:
mkdir -p /data/{backup,data,logs,packages,services} cd /data/packages # 上传包 tar -zxf redis-4.0.14.tar.gz cd redis-4.0.14/ make make PREFIX=/data/services/redis/master-17000 install make PREFIX=/data/services/redis/slave-18000 install cd /data/services/redis/master-17000 mkdir data logs conf cd /data/services/redis/slave-18000 mkdir data logs conf
2. 配置 master 配置文件:
cat > /data/services/redis/master-17000/conf/redis-17000.conf << EOF ################################################################################################# # Redis 配置文件 ################################################################################################# ################################################################################################# # 基础配置 ################################################################################################# protected-mode yes bind 0.0.0.0 port 17000 tcp-backlog 2048 timeout 0 tcp-keepalive 300 daemonize yes supervised no pidfile /data/services/redis/master-17000/logs/redis-17000.pid loglevel notice logfile "/data/services/redis/master-17000/logs/redis-17000.log" databases 16 always-show-logo yes # requirepass helloworld ################################################################################################# # RDB持久化配置 ################################################################################################# dbfilename dump-17000.rdb dir "/data/services/redis/master-17000/data" save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes ################################################################################################# # AOF持久化配置 ################################################################################################# appendonly yes appendfilename "appendonly-17000.aof" appendfsync everysec no-appendfsync-on-rewrite yes auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes aof-use-rdb-preamble no ################################################################################################# # 主从配置 ################################################################################################# # slaveof# masterauth helloworld slave-serve-stale-data yes slave-read-only yes repl-diskless-sync no repl-diskless-sync-delay 5 repl-ping-slave-period 10 repl-timeout 60 repl-disable-tcp-nodelay no repl-backlog-size 1mb repl-backlog-ttl 3600 slave-priority 100 min-slaves-to-write 1 min-slaves-max-lag 10 ################################################################################################# # 集群配置 ################################################################################################# # 集群开关 cluster-enabled yes # 集群配置文件名称,每个集群都有一个集群配置相关文件用于持久化保存集群信息。Redis 自动生成 cluster-config-file /data/services/redis/master-17000/conf/nodes.conf # 节点连接超时毫秒数 cluster-node-timeout 5000 # 判断slave是否和master断开连接过长而导致数据过旧,这种节点旧不会倍选为主 # cluster-slave-validity-factor 10 # slave数量大于该值,slave才能迁移到其它孤立的master # cluster-migration-barrier 1 # 默认所有节点的切片都正常集权状态才是OK # cluster-require-full-coverage yes # cluster-slave-no-failover no EOF
3. 配置 slave 配置文件:
cat > /data/services/redis/slave-18000/conf/redis-18000.conf << EOF ################################################################################################# # Redis 配置文件 ################################################################################################# ################################################################################################# # 基础配置 ################################################################################################# protected-mode yes bind 0.0.0.0 port 18000 tcp-backlog 2048 timeout 0 tcp-keepalive 300 daemonize yes supervised no pidfile /data/services/redis/slave-18000/logs/redis-18000.pid loglevel notice logfile "/data/services/redis/slave-18000/logs/redis-18000.log" databases 16 always-show-logo yes # requirepass helloworld ################################################################################################# # RDB持久化配置 ################################################################################################# dbfilename dump-18000.rdb dir "/data/services/redis/slave-18000/data" save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes ################################################################################################# # AOF持久化配置 ################################################################################################# appendonly yes appendfilename "appendonly-18000.aof" appendfsync everysec no-appendfsync-on-rewrite yes auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes aof-use-rdb-preamble no ################################################################################################# # 主从配置 ################################################################################################# # slaveof# masterauth helloworld slave-serve-stale-data yes slave-read-only yes repl-diskless-sync no repl-diskless-sync-delay 5 repl-ping-slave-period 10 repl-timeout 60 repl-disable-tcp-nodelay no repl-backlog-size 1mb repl-backlog-ttl 3600 slave-priority 100 min-slaves-to-write 1 min-slaves-max-lag 10 ################################################################################################# # 集群配置 ################################################################################################# # 集群开关 cluster-enabled yes # 集群配置文件名称,每个集群都有一个集群配置相关文件用于持久化保存集群信息。Redis 自动生成 cluster-config-file /data/services/redis/slave-18000/conf/nodes.conf # 节点连接超时毫秒数 cluster-node-timeout 5000 # 判断slave是否和master断开连接过长而导致数据过旧,这种节点旧不会倍选为主 # cluster-slave-validity-factor 10 # slave数量大于该值,slave才能迁移到其它孤立的master # cluster-migration-barrier 1 # 默认所有节点的切片都正常集权状态才是OK # cluster-require-full-coverage yes # cluster-slave-no-failover no EOF
4. 启动所有节点:
/data/services/redis/master-17000/bin/redis-server /data/services/redis/master-17000/conf/redis-17000.conf
/data/services/redis/slave-18000/bin/redis-server /data/services/redis/slave-18000/conf/redis-18000.conf
进程如下:
![]()
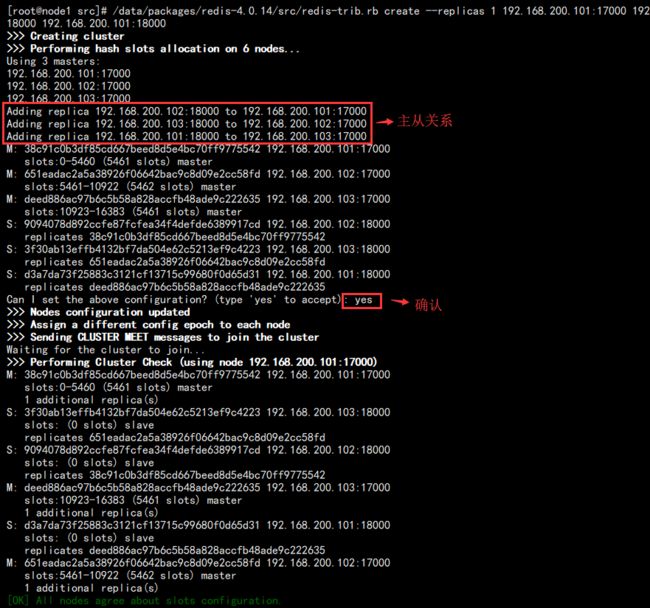
5. 构建集群,在 redis 的解压包中有脚本:
/data/packages/redis-4.0.14/src/redis-trib.rb create --replicas 1 192.168.200.101:17000 192.168.200.102:17000 192.168.200.103:17000 192.168.200.102:18000 192.168.200.103:18000 192.168.200.101:18000
后面节点的顺序直接影响着主从关系。
6. 查看集群状态:
# 查看master /data/services/redis/master-17000/bin/redis-cli -p 17000 cluster nodes | grep master # 查看slave /data/services/redis/master-17000/bin/redis-cli -p 17000 cluster nodes | grep slave
结果如下:

可以看到 0 - 16383 的内存槽位倍均分成了3个。
7. 模拟故障,假如节点 1 的master 挂了:
# 查看master /data/services/redis/master-17000/bin/redis-cli -p 18000 cluster nodes | grep master # 查看slave /data/services/redis/master-17000/bin/redis-cli -p 18000 cluster nodes | grep slave
结果如图:

可以看到从顶了上去。此时恢复 17000 主节点:

可以看到启动了变成了 slave,如果我们希望恢复成主,只需要停掉对应的18000 主节点(也就是102的18000)让他切换过去,再启动即可。
8. 数据测试:
此时在 102:17000 设置一个 key:

然后去 101:17000 读取:
![]()
会提示让我们切换节点。
增加节点
随着业务的扩展,可能三个节点慢慢的无法满足我们的需求,所以需要新加入节点。此时我们以新加一个主从节点为例。
1. 运行 17000 / 18000 方法和上面的一样,并搭建ruby环境。
![]()
2. 使用之前的集群构建脚本添加节点:
/data/packages/redis-4.0.14/src/redis-trib.rb add-node 192.168.200.104:17000 192.168.200.101:17000
结果如图:
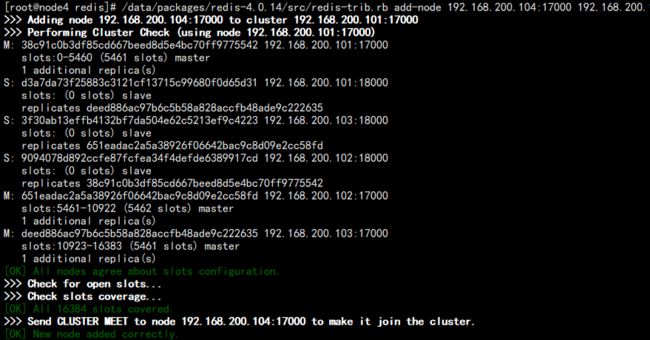
此时查看 master 节点:
/data/services/redis/master-17000/bin/redis-cli -p 17000 cluster nodes | grep master
结果如图:

能够看到新节点,但是存在一个问题,我们之前说过,Redis 有 16384 个内存分片,可以看到另外三个节点都有分片,但是这个节点并没有。说明该节点是不能使用的。所以开始分片。
特殊情况说明:
如果 gem 安装的 4 版本,这一步一定要执行,否则扩展可能失败,并且没法修复!
如果你 gem 安装的是 3 版本,则不需要管这一步,直接跳到第三步开始迁移即可!
网上有很多都是直接迁移,在 4.0 中迁移其实会报错,其实是 redis 的 BUG:

官方答复原因为 gem 版本差异造成的,在 5.0 版本中会弃用,修复也很简单,修改 redis-trib.rb 文件:
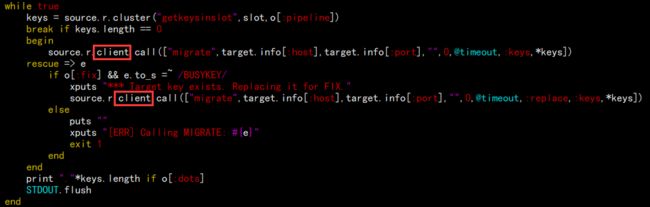
去掉这两个 client 即可,为了确保以后会用到,建议所有节点的包都做修改:
sed -i "s#source.r.client.call#source.r.call#g" /data/packages/redis-4.0.14/src/redis-trib.rb
3. 迁移切片到新节点:
/data/packages/redis-4.0.14/src/redis-trib.rb reshard 192.168.200.101:17000
如图:

后面还需要 yes 做个确认!
此时查看节点状态:

由于每个节点都分了一部分过来,所有分片由三个部分组成!
4. 最后给该节点添加一个从节点:
/data/packages/redis-4.0.14/src/redis-trib.rb add-node --slave --master-id 38e6a292a54f4d9c4bf44c28cbac91cb35b2bcaf 192.168.200.104:18000 192.168.200.101:17000
其中 master-id 为刚刚新加的 ID,此时添加节点完成:

删除节点
对于刚刚我们添加的节点,也可以删除它,但是删除需要分为两步,第一步将分片归还回去,第二步是删除节点。
对于归还切片,则需要一部分一部分的归还:
/data/packages/redis-4.0.14/src/redis-trib.rb reshard 192.168.200.101:17000
开始重新分片,上面的结果我们可以知道,新节点的分片为:
0-1364 5461-6826 10923-12287
那么第一部的数量为:1365,第二部分的数量为:1366,第三部分也是 1366。

后面 yes 确认即可!
此时查看新节点就少了一截:

其余两部分同理,最终效果:

所有的切片都归还回去了,此时再去节点1上删除节点,便于观察:
# 删除 master /data/packages/redis-4.0.14/src/redis-trib.rb del-node 192.168.200.104:17000 38e6a292a54f4d9c4bf44c28cbac91cb35b2bcaf # 删除 slave /data/packages/redis-4.0.14/src/redis-trib.rb del-node 192.168.200.104:18000 465ca1f687c0c05f40dccca8f7a142ee18eefb16
然后查看:

至此,删除节点完成!
当然,这种增删节点是一种解决方案,更好的其实还是重新搭建重新规划,这样分片更连续,另外,做这种操作应该避开业务高峰期做。