1 现象描述及初步分析
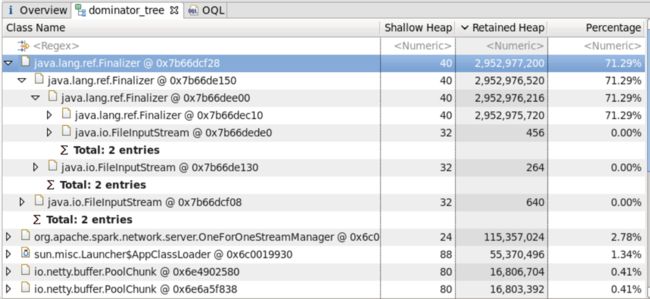
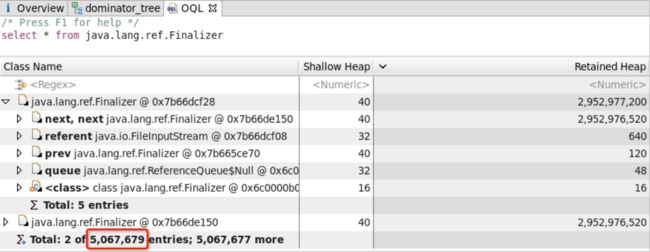
近期公司yarn集群中存在NodeManager因OOM 而挂掉的情况, 且发生OOM前存在大量的Spark Shuffle Services相关信息, 通过分析最近Crash的NodeManager进程的dump信息发现存在大量的Finalizer,占用了大部分分的内存资源,其中dump分析结果如下所示:
附:NodeManager日志信息
java.lang.OutOfMemoryError: GC overhead limit exceeded
通过dump分析可知,OOM原因为:FileInputStream引发的Finalizer对象堆集所致。
该对象为Shuffle Server在处理Shuffle Client数据请求时所创建。 其中包含如下代码部分(Spark1.6):
/**
* Sort-based shuffle data uses an index called "shuffle_ShuffleId_MapId_0.index" into a data file
* called "shuffle_ShuffleId_MapId_0.data". This logic is from IndexShuffleBlockResolver,
* and the block id format is from ShuffleDataBlockId and ShuffleIndexBlockId.
*/
private ManagedBuffer getSortBasedShuffleBlockData(
ExecutorShuffleInfo executor, int shuffleId, int mapId, int reduceId) {
File indexFile = getFile(executor.localDirs, executor.subDirsPerLocalDir,
"shuffle_" + shuffleId + "_" + mapId + "_0.index");
DataInputStream in = null;
try {
in = new DataInputStream(new FileInputStream(indexFile));
in.skipBytes(reduceId * 8);
long offset = in.readLong();
long nextOffset = in.readLong();
return new FileSegmentManagedBuffer(
conf,
getFile(executor.localDirs, executor.subDirsPerLocalDir,
"shuffle_" + shuffleId + "_" + mapId + "_0.data"),
offset,
nextOffset - offset);
} catch (IOException e) {
throw new RuntimeException("Failed to open file: " + indexFile, e);
} finally {
if (in != null) {
JavaUtils.closeQuietly(in);
}
}
}
其中 创建FileInputStream的作用是为了拿到索引文件中的数据偏移量及文件长度,用于读取数据。(备注:读取shuffle数据时也会创建FileInputStream对象,上述代码供献1/2的对象数量。)并且,该实现中每次数据请求都会创建一个FileInputStream对象用于读取索引文件。
2 存在大量FileInputStream相关Fanalizer的原因
其FileInputStream自定义了finalize()方法,因此JVM会为每一个FileInputStream对象创建一个Finalizer引用对象,用于确保FileInputStream最终处理关闭状态。
/**
* Cleans up the connection to the file, and ensures that the
* close method of this file output stream is
* called when there are no more references to this stream.
*
* @exception IOException if an I/O error occurs.
* @see java.io.FileInputStream#close()
*/
protected void finalize() throws IOException {
if (fd != null) {
if (fd == FileDescriptor.out || fd == FileDescriptor.err) {
flush();
} else {
/*
* Finalizer should not release the FileDescriptor if another
* stream is still using it. If the user directly invokes
* close() then the FileDescriptor is also released.
*/
runningFinalize.set(Boolean.TRUE);
try {
close();
} finally {
runningFinalize.set(Boolean.FALSE);
}
}
}
}
所有的Finalizer组成一个双向链表,其共同维护一个ReferenceQueue,进入队列中的对象可以被gc回收。
同时,JVM中存在一个守护线程:FinalizerThread 其优先级为 8,用于从双向链表中清除进入ReferenceQueue中的Finalizer,以便在下次GC时回收这部分Finalizer。
资源充足的情况下,FinalizerThread线程可以被调度执行,从而ReferenceQueue中的Finalizer会很快被清理掉,从而在GC时释放占用内存。
而在External Shuffle Services 场景中 Shuffle Server作为NodeManager进程中的daemon线程执行,并且其创建了大量提供数据服务 的shuffle-server服务线程(数量默认为NodeManager管理的cores * 2, 因此配制最低的机型拥有48个线程), 该线程优先级为5.
经过上述分析,我们可知NodeManager中有
- 一个消费Finalizer的FinalizerThread线程,优先级为8
- 48 个用于生产Finalizer的shuffle-server线程,优先级为5
- 其它大量线程(如Thread-7872425匿名线程等),此处不一一给出
"Thread-7872425" #8190511 prio=5 os_prio=0 tid=0x00007f1aa8d51000 nid=0xc671 runnable [0x00007f1a83435000] java.lang.Thread.State: RUNNABLE at java.io.FileInputStream.readBytes(Native Method) at java.io.FileInputStream.read(FileInputStream.java:255)
在Java中线程优先级的范围是:1-10,且数字越大优先级越高,线程优先级高仅仅表示线程获取的 CPU时间片的几率高。然而,由于shuffle-server线程数量较多,当Shuffle Client端请求频繁(大量reduce任务Fetch数据)时,shuffle-server线程被调度的机率会比Finalizer线程大,这会导致shuffle-server线程生产Finalizer的速率远大于FinalizerTread线程清理的速率,从而导致Finalizer堆集。
3 实验复现方案
其于如前所述的原因分析:Client端请求频繁时,会导致shuffle-server线程生产Finalizer的速率远大于FinalizerTread线程清理的速率,会导致Finalizer堆集。因此,可增加部分节点的shuffle-server线程,使用问题更易复现。
- 调整实验集群中一个节点的NodeManager管理的Cores的数量
操作方法:yarn.nodemanager.resource.cpu-vcore = 80 <更大的值> 或 spark.shuffle.io.serverThreads=160
备注: 该问题会出现在Shuffle fetch密集的场景(即分布式任务并发度高的场景)。
3.1 模拟实验
复现方案中提出以调参的方式增加服务线程数量,从而增加shuffle-server线程被调度的机率。但复现的前提是要造出大量的密集的Fetch请求,然而,目前测试集群规模无法与生产环境相提并论,不易造出上述场景;而且,用户应用负载及数据的获取不易。因此,进行以下实验模拟真实环境的执行情况。
3.1.1 实验
实验一
50个线程创建FileInputStream-
实验二
100个线程创建FileInputStream上述实验,采用Java 8,采用JVM默认配制,并在相同的节点中进行。
3.1.2 结果
- 实验一
Full GC时,ParOldGen(老年代)可以正常回收。 - 实验二
Full GC时,ParOldGen(老年代)几乎不能回收,从而引发如下异常:
Exception in thread "shuffle-server-5" java.lang.OutOfMemoryError: GC overhead limit exceeded
异常发生时,Java Heap信息:
Heap
PSYoungGen total 465920K, used 226578K [0x0000000795580000, 0x00000007c0000000, 0x00000007c0000000)
eden space 232960K, 97% used [0x0000000795580000,0x00000007a32c4bb0,0x00000007a3900000)
from space 232960K, 0% used [0x00000007b1c80000,0x00000007b1c80000,0x00000007c0000000)
to space 232960K, 0% used [0x00000007a3900000,0x00000007a3900000,0x00000007b1c80000)
ParOldGen total 1398272K, used 1397883K [0x0000000740000000, 0x0000000795580000, 0x0000000795580000)
object space 1398272K, 99% used [0x0000000740000000,0x000000079551ee20,0x0000000795580000)
Metaspace used 2718K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 291K, capacity 386K, committed 512K, reserved 1048576K
3.1.3 实验结果分析
上述实验唯一区别为线程数量不同,即FileInputStream的生产线程与Finalizer线程竞争执行资源的激烈程度不同。
实验一 由于线程数量较少,竞争激烈程度低,FinalizerThread线程可以被调度执行,从而可以从Finalizer链表中清除无引用的对象,进而在GC时回收掉Finalizer.
实验二 线程数量较大,竞争激烈程度高,FinalizerThread线程被调度的机会少,从而Finalizer链表(双向链表)中的对象无法被回收,只能在Heap的 from 区 及 to 区进行拷贝,多个回合后进入old区(老年代)。当FinalizerThread持续被阻塞时,就会发生Finalizer堆满old区的情况。由于Finalizer对象在一个双向链表中相互引用,Full GC 依然会无法回收,最终会引发:“java.lang.OutOfMemoryError: GC overhead limit exceeded”。
在真实的NodeManager中,除了存在shuffle-server线程外,还存在大量其它大量线程(有些线程也会产生FileInputStream)。在负载较高时,这些线程都会与FinalizerThread发生竞争,从而降低FinalizerThread执行的机率。
- 附1:GC overhead limit exceeded发生的原因
This message means that for some reason the garbage collector is taking an excessive amount of time (by default 98% of all CPU time of the process) and recovers very little memory in each run (by default 2% of the heap)
- 附2:实验过程中jstack快照
"shuffle-server-28" #37 prio=5 os_prio=31 tid=0x00007faea901f000 nid=0x8503 waiting for monitor entry [0x000070000e6e7000]
java.lang.Thread.State: BLOCKED (on object monitor)
at java.lang.ref.Finalizer.add(Finalizer.java:51)
"- waiting to lock <0x000000074127c070> (a java.lang.Object)"
at java.lang.ref.Finalizer.(Finalizer.java:82)
at java.lang.ref.Finalizer.register(Finalizer.java:87)
at java.lang.Object.(Object.java:37)
at java.io.InputStream.(InputStream.java:45)
at java.io.FileInputStream.(FileInputStream.java:123)
at java.io.FileInputStream.(FileInputStream.java:93)
at TestThread.run(Test.java:32)
"shuffle-server-26" #35 prio=5 os_prio=31 tid=0x00007faea88c9800 nid=0x8103 waiting for monitor entry [0x000070000e4e1000]
java.lang.Thread.State: BLOCKED (on object monitor)
at java.lang.ref.Finalizer.add(Finalizer.java:51)
"- waiting to lock <0x000000074127c070> (a java.lang.Object)"
at java.lang.ref.Finalizer.(Finalizer.java:82)
at java.lang.ref.Finalizer.register(Finalizer.java:87)
at java.lang.Object.(Object.java:37)
at java.io.InputStream.(InputStream.java:45)
at java.io.FileInputStream.(FileInputStream.java:123)
at java.io.FileInputStream.(FileInputStream.java:93)
at TestThread.run(Test.java:32)
......
"Finalizer" #3 daemon prio=8 os_prio=31 tid=0x00007faeaa00d800 nid=0x3103 waiting for monitor entry [0x000070000c37e000]
java.lang.Thread.State: BLOCKED (on object monitor)
at java.lang.ref.Finalizer.remove(Finalizer.java:61)
"- waiting to lock <0x000000074127c070> (a java.lang.Object)"
at java.lang.ref.Finalizer.runFinalizer(Finalizer.java:93)
- locked <0x00000007bacfba70> (a java.lang.ref.Finalizer)
at java.lang.ref.Finalizer.access$100(Finalizer.java:34)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:210)
4 结论
通过上述分析及实验可知,NodeManager发生OOM的主要原因为:其内部线程生产Finalizer的速率大于FinalizerTread线程清理的速率,从而使Finalizer链表(双向链表)中无法回收的对象,只能在Heap的 from 区 及 to 区进行拷贝,多个回合后进入old区(老年代)。当FinalizerThread持续被阻塞时,就会发生Finalizer堆满old区的情况,由于Finalizer对象在一个双向链表中相互引用,Full GC依然会无法回收,最终会引发:“java.lang.OutOfMemoryError: GC overhead limit exceeded”。
5 拟解决方案
shuffle-server线程存在为获取得Shuffle IndexFile中reduce任务对应数据的偏移量及数据长度而创建FileInputStream的情况,且原有方案中每次获取都重新打开一次文件,即创建一个FileInputStream对象。 因此,可以引入缓存机制减少读取该文件的次数。
-
引入缓存机制减少读取该文件的次数。
一个IndexFile中包含一个APP在该节点中的所有数据索引,因此引入缓存具有
较大收益。Spark-15074中已引入缓存特性,且#SPARK-21501对缓存方案进行了完善,
因此可merge官方feature 达到缓解问题的目的。
缺点:缓存只能涵盖读取IndexFile时产生FileInputStream的场景,仅覆盖
Shuffle Server中1/2的FileInputStream对象。
除此之外,还可以使用以下方式进行调整:
使用Files NIO替换FileInputStream
因为该问题主要是FileInputStream中实现了finalize()方法所置。
缺点:不能减少文件频繁读写的开销, 对Netty等的影响暂无法评估。减少shuffle-server线程数量,降低FileInputStream产生速率,通过参数io.serverThreads调整。
缺点:机型较多,一种配制可能不能满足三种机型, 且不合适的配制可能影响作业的执行效率,目前缺少数据支撑。
综上所述:为将风险降至最低,可以先尝试 1 或1、3结合的方案。最后尝试1、2结合方案(事实证明1、2结合可以有效解决问题)。
文献:http://www.oracle.com/technetwork/java/javamail/finalization-137655.html 中提到Finalizer产生的原因及一些处理办法。