众所周知,我们这次使用的MTCNN的模型存在侧脸无法检测等,这次准备仔细看看源码,除了观察能否通过修改配置参数改善检测问题之外,还希望通过研究代码加深对mtcnn原理的研究,为未来自己训练模型打下基础。
一、MTCNN模型构成简介
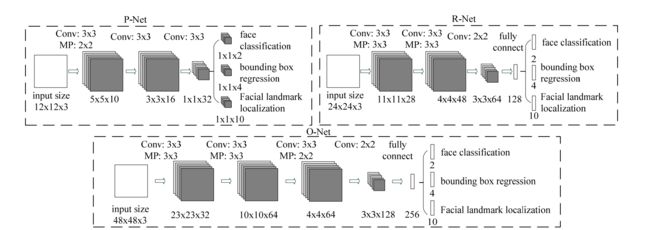
mtcnn模型是由三个子神经网络构成的,分别为P_net,R_Net和O_net。
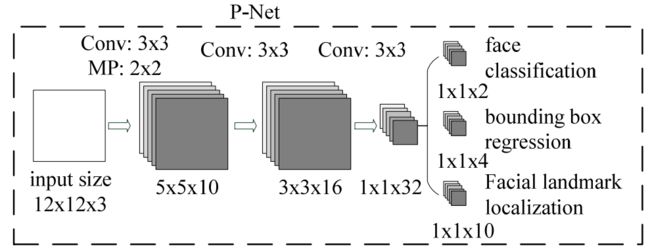
- PNet:12 x 12,负责粗选得到候选框,功能有:分类、回归。
P_net是一个全连接的卷积网络,它输出可能的人脸矩形框的对端坐标点以及其相应的是人脸的概率值。 - RNet:24 x 24,负责筛选PNet的粗筛结果,并微调box使得更加准确和过滤虚警,功能有:分类、回归。
R_Net的输入不仅仅是图片,还有P_net输出的可能是人脸的矩形框坐标点向量。R_Net也是一个卷积神经网络,他过滤掉大部分非人脸的矩形框。它输出人脸的对端坐标点和该矩形框是人脸的概率值。 - ONet:48 x 48,负责最后的筛选判定,并微调box,回归得到keypoint的位置,功能有:分类、回归、关键点。Onet的结构和R_net类似,但是它输出的还有人脸的五个坐标点。
二、代码结构简介
因为我们并不会真的训练模型,而是调用前辈们已经学习好的参数构建模型,因此在MTCNN_model中保存已经训练好的模型参数。
train_models中保存了1.三个网络的构建方法保存在这个文件夹的mtcnn_model.py中。2. 训练三个网络的语句
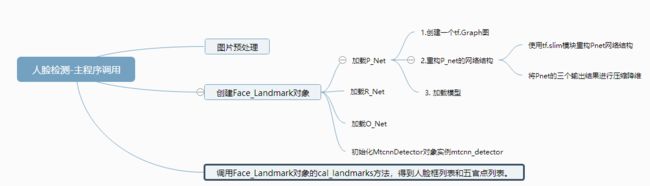
三、主程序调用简介
主程序很简单,首先将一张图片进行转码处理之后,传入Face_Landmarks对象的cal_landmarks方法中,然后返回人脸框列表和五官点列表。
if __name__ == '__main__':
image_path = './zhgaoliy2.jpg'
img_file = open(image_path, "rb").read()
img_b64encode = base64.urlsafe_b64encode(img_file).decode('utf-8')
img_b64decode = base64.urlsafe_b64decode(img_b64encode) # base64解码
img_array = np.fromstring(img_b64decode, np.uint8) # 转换np序列
frame = cv2.imdecode(img_array, cv2.COLOR_BGR2RGB)
image = np.array(frame)
face = Face_Landmarks()
boxes_c, landmarks = face.cal_landmarks(image)
print(boxes_c, landmarks)
Face_landmarks对象的初始化过程就是加载P_Net,R_Net和O_Net,将这三个detector传入MtcnnDetector对象中,初始化MtcnnDetector对象,并命名为mtcnn_detector。
mtcnn_detector的传入参数有min_face_size、 stride步长、threshold阈值、slide_window滑动窗口。其中阈值用于控制三个网络对输出的人脸框,当输出的人脸概率face_classification大于阈值,才会被当成可信的结果。
而cal_landmarks()方法则调用了初始化之后的mtcnn_detector的detect方法,输出人脸矩形框和人脸五官点坐标。
from Detection.MtcnnDetector import MtcnnDetector
from Detection.detector import Detector
from Detection.fcn_detector import FcnDetector
from train_models.mtcnn_model import P_Net, R_Net, O_Net
test_mode = "onet"
thresh = [0.01, 0.01, 0.01]
min_face_size = 24
stride = 2
slide_window = False
shuffle = False
# vis = True
prefix = ['./MTCNN_model/PNet_landmark/PNet', './MTCNN_model/RNet_landmark/RNet', './MTCNN_model/ONet_landmark/ONet']
epoch = [18, 14, 16]
model_path = ['%s-%s' % (x, y) for x, y in zip(prefix, epoch)]
class Face_Landmarks:
def __init__(self):
detectors = [None, None, None]
PNet = FcnDetector(P_Net, model_path[0])
detectors[0] = PNet
RNet = Detector(R_Net, 24, 1, model_path[1])
detectors[1] = RNet
ONet = Detector(O_Net, 48, 1, model_path[2])
detectors[2] = ONet
self.mtcnn_detector = MtcnnDetector(detectors=detectors, min_face_size=min_face_size,
stride=stride, threshold=thresh, slide_window=slide_window)
def cal_landmarks(self, frame):
if self.mtcnn_detector:
image = np.array(frame)
boxes_c, landmarks = self.mtcnn_detector.detect(image)
return boxes_c, landmarks
四、深入Face_Landmark的初始化模块
1. 三个网络的初始化构建---以P_net为例
在Face_Landmarks的初始化语句中,使用了PNet = FcnDetector(P_Net, model_path[0])初始化P_net.我们深入Detection.fcn_detector.FcnDetector中,看看如何构建P_net。
PNet的实例的构建传入参数有两个,第一个神经网络的名称,第二个是神经网络的参数位置path。
先简单的介绍一下tensorflow。TensorFlow是符号式编程。将图的定义和图的运行完全分开。符号式计算一般是先定义各种变量,然后建立一个数据流图,在数据流图中规定各个变量之间的计算关系,最后需要对数据流图进行编译,但此时的数据流图还是一个空壳儿,里面没有任何实际数据,只有把需要运算的输入放进去后,才能在整个模型中形成数据流,从而形成输出值。TensorFlow 中涉及的运算都要放在图中,而图的运行只发生在会话(session)中。开启会话后,就可以用数据去填充节点,进行运算;
FcnDetector的初始化函数__init__只负责定义数据流图,具体的执行不涉及。__init__做的工作可以分为三个部分,定义tf的变量,重构Pnet网络结构和加载模型。
首先创建一个图,在图中,使用填充机制 tf.placeholder()临时替代操作的张量,image_op是图片的参数,width_op 是宽度的参数,height_op是长度的参数,image_reshape是将image_op调整维度之后的新的tensor.
重构P_net的网络结构。调用
self.cls_prob, self.bbox_pred, _ = net_factory(image_reshape, training=False)完成了P_net网络结构的构建。在下面的1.1中会详细讲解- 加载模型,创建一个tf.session,实例化一个tf.train.Saver(),用于恢复模型,使用 saver.restore() 方法,重载模型的参数。模型重载的路径需要包括如下的内容。简单的理解就是权重等参数被保存到 .ckpt.data 文件中,以字典的形式;图和元数据被保存到 .ckpt.meta 文件中,可以被 tf.train.import_meta_graph 加载到当前默认的图。
 模型参数
模型参数
class FcnDetector(object):
def __init__(self, net_factory, model_path):
#create a graph
graph = tf.Graph()
with graph.as_default():
#define tensor and op in graph(-1,1)
self.image_op = tf.placeholder(tf.float32, name='input_image')
self.width_op = tf.placeholder(tf.int32, name='image_width')
self.height_op = tf.placeholder(tf.int32, name='image_height')
image_reshape = tf.reshape(self.image_op, [1, self.height_op, self.width_op, 3])
#self.cls_prob batch*2
#self.bbox_pred batch*4
#construct model here
self.cls_prob, self.bbox_pred, _ = net_factory(image_reshape, training=False)
self.sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,gpu_options=tf.GPUOptions(allow_growth=True)))
saver = tf.train.Saver()
#check whether the dictionary is valid
model_dict = '/'.join(model_path.split('/')[:-1])
#model_dict = '/'+model_dict
ckpt = tf.train.get_checkpoint_state(model_dict)
print(model_path)
readstate = ckpt and ckpt.model_checkpoint_path
assert readstate, "the params dictionary is not valid"
print("restore models' param")
saver.restore(self.sess, model_path)
1.1 构建P-net的网络结构
在上面我们提到了,FcnDetector中使用了self.cls_prob, self.bbox_pred, _ = net_factory(image_reshape, training=False)完成了P_net网络结构的构建。这里我们详细进入train_models查看mtcnn_model.py中研究一下Pnet的网络结构。首先再来巩固一下Pnet的网络结构,这是一个四层卷积神经网络,有三个中间卷积层,没有全连接层,输出是三个卷积结果。
因为代码中涉及到了TF-Slim,所以先简单的介绍一下TF-Slim。TF-Slim是tensorflow中定义、训练和评估复杂模型的轻量级库。tf-slim中的组件可以轻易地和原生tensorflow框架以及例如tf.contrib.learn这样的框架进行整合。slim模型的arg_scope允许用户在这个scope中对特定的方法定义默认的参数。比如代码中,对slim.conv2d这个卷积方法,它定义默认的激活函数、参数初始化方法、偏置初始化方法、正则化规则和卷积的填充方式。
这份代码也可以分为两个部分,第一部分是构建Pnet结构,第二部分是
- 代码中net张量依次通过conv2d,max_pool2d,conv2d,conv2d然后定义了三个输出张量分别为人脸置信概率conv4_1、人脸矩形坐标bbox_pred、人脸五官点坐标 landmark_pred(并没有使用)。
_activation_summary(net)函数是用于tensorboard观察数据使用的,这里不扩展。 - 将Pnet的三个输出结果进行压缩降维
#construct Pnet
#label:batch
def P_Net(inputs,label=None,bbox_target=None,landmark_target=None,training=True):
#define common param
with slim.arg_scope([slim.conv2d],
activation_fn=prelu,
weights_initializer=slim.xavier_initializer(),
biases_initializer=tf.zeros_initializer(),
weights_regularizer=slim.l2_regularizer(0.0005),
padding='valid'):
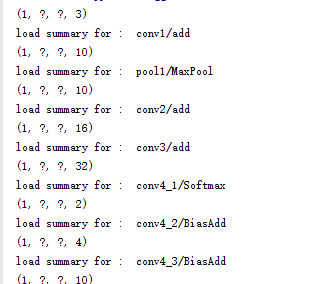
print(inputs.get_shape())
net = slim.conv2d(inputs, 10, 3, stride=1,scope='conv1')
_activation_summary(net)
print(net.get_shape())
net = slim.max_pool2d(net, kernel_size=[2,2], stride=2, scope='pool1', padding='SAME')
_activation_summary(net)
print(net.get_shape())
net = slim.conv2d(net,num_outputs=16,kernel_size=[3,3],stride=1,scope='conv2')
_activation_summary(net)
print(net.get_shape())
#
net = slim.conv2d(net,num_outputs=32,kernel_size=[3,3],stride=1,scope='conv3')
_activation_summary(net)
print(net.get_shape())
#batch*H*W*2
conv4_1 = slim.conv2d(net,num_outputs=2,kernel_size=[1,1],stride=1,scope='conv4_1',activation_fn=tf.nn.softmax)
_activation_summary(conv4_1)
#conv4_1 = slim.conv2d(net,num_outputs=1,kernel_size=[1,1],stride=1,scope='conv4_1',activation_fn=tf.nn.sigmoid)
print (conv4_1.get_shape())
#batch*H*W*4
bbox_pred = slim.conv2d(net,num_outputs=4,kernel_size=[1,1],stride=1,scope='conv4_2',activation_fn=None)
_activation_summary(bbox_pred)
print (bbox_pred.get_shape())
#batch*H*W*10
landmark_pred = slim.conv2d(net,num_outputs=10,kernel_size=[1,1],stride=1,scope='conv4_3',activation_fn=None)
_activation_summary(landmark_pred)
print (landmark_pred.get_shape())
# add projectors for visualization
#cls_prob_original = conv4_1
#bbox_pred_original = bbox_pred
if training:
#batch*2
# calculate classification loss
cls_prob = tf.squeeze(conv4_1,[1,2],name='cls_prob')
cls_loss = cls_ohem(cls_prob,label)
#batch
# cal bounding box error, squared sum error
bbox_pred = tf.squeeze(bbox_pred,[1,2],name='bbox_pred')
bbox_loss = bbox_ohem(bbox_pred,bbox_target,label)
#batch*10
landmark_pred = tf.squeeze(landmark_pred,[1,2],name="landmark_pred")
landmark_loss = landmark_ohem(landmark_pred,landmark_target,label)
accuracy = cal_accuracy(cls_prob,label)
L2_loss = tf.add_n(slim.losses.get_regularization_losses())
return cls_loss,bbox_loss,landmark_loss,L2_loss,accuracy
#test
else:
#when test,batch_size = 1
cls_pro_test = tf.squeeze(conv4_1, axis=0)
bbox_pred_test = tf.squeeze(bbox_pred,axis=0)
landmark_pred_test = tf.squeeze(landmark_pred,axis=0)
return cls_pro_test,bbox_pred_test,landmark_pred_test
参考资料
Tensorflow的模型保存和读取tf.train.Saver
tf.train.get_checkpoint_state
理解tf.squeeze():用于删除维度维1的维度