SQLite3 API 包括很多函数,但是只有大概8个函数是实际处理连接、查询、断开与数据库连接所必需的。
一、查询封装
1、连接与断开连接
执行SQL命令前,要先连接数据库,也叫打开数据库。结束时,要断开连接,也叫关闭数据库。
打开数据库的函数有:
- sqlite3_open_v2():推荐使用
- sqlite3_open()
- sqlite3_open16()
int sqlite3_open_v2(
const char *filename, /*数据库文件名*/
sqlite3 **ppDb /*OUT:SQLite数据库句柄*/
int flags, /*标志*/
const char *zVfs /*要使用的VFS模块的名称*/
)
说明:
- filename:可以为操作系统文件、文本字符串‘memory’、空字符串。filename为‘memory’时,表示将在内存中创建数据库;为空字符串或null时,表示打开临时磁盘文件,并在连接关闭时自动删除文件。为其他选项时,尝试打开参数指定的文件,若文件不存在且flags不等于SQLITE_OPEN_CREATE,则返回错误。
- ppDb:在打开完成后,sqlite3_open_v2会初始化sqlite3结构体传递给ppDb参数,是事务上下文环境。代表一个连接句柄,而不是一个数据库句柄,因为可能会附加多个数据库到一个连接上。
- flags:是一个比特向量,包括以下几种值:SQLite_OPEN_READONLY、SQLite_OPEN_READWRITE、SQLITE_OPEN_CREATE等。SQLite_OPEN_READONLY、SQLite_OPEN_READWRITE分别表示只读和读/写模式打开数据库,若文件不存在,就返回错误。
- zVfs:表示允许调用者覆写默认的sqlite3_vfs操作系统接口。
关闭连接的函数:
int sqlite3_close(sqlite3*);
说明:
- sqlite3_close要成功执行,须完成连接中所有的查询。若有一个未完成,就会返回SQLITE_BUSY,并显示错误消息。
- sqlite3_close关闭连接时,若连接上有打开的事务,该事务将自动回滚。
2、执行查询
执行SQL命令的函数:
int sqlite3_exec(
sqlite3*, /*打开的数据库*/
const char *sql, /*要执行的SQL*/
sqlite_callback, /*回调函数*/
void *data /*回调函数的第一个参数*/
char **errmsg /*错误信息*/
);
说明:
- sqlite3_exec()解析执行sql语句中的每个命令,知道遇到该字符串的末尾或遇到错误。
- sqlite3_exec()提供了获取select语句结果的回调机制。
- sqlite_callback:回调函数的指针,调用函数会处理每个sql语句中执行的select语句的结果。
sqlite_callback回调函数的声明:
typedef int (*sqlite3_callback)(
void*, /*该参数就是sqlite3_exec的第四个参数提供的数据*/
int, /*行中字段的数目*/
char**, /*代表行中字段名称的字符串数组*/
char** /*代表字段名称的字符串数组*/
)
说明:
- sqlite3_callback回调函数的返回值,会影响sqlite3_exec()的执行。若返回非零值,sqlite3_exec()将会终止。
3、获取表查询
函数声明如下:
int sqlite3_get_table(
sqlite3*, /*打开的数据库*/
const char *sql, /*要执行的SQL语句*/
char ***resultp, /*结果写入该指针指向的char*[]*/
int *nrow, /*结果集中行的数目*/
int *ncolumn, /*结果集中字段的数目*/
char **errmsg /*错误信息*/
)
说明:
- resultp:堆上声明的内存,将返回的记录都存储在resultp中,必须使用sqlite3_free_table()释放内存。
- resultp的前几个元素实际上不是真的记录,而是结果集中的列名称。
二、查询准备
相比于sqlite3_exec()和sqlite3_get_table(),准备查询提供了更多的功能,更好的控制和更多的信息。
实际上,sqlite3_exec()更适合运行修改数据库的命令(create、drop、insert、update、delete)。而准备查询更适合select语句,因为它可以提供更多的信息,并且可以通过游标来遍历结果集。
下面就准备查询的整个过程及三个步骤:编译、执行、完成来进行详细解释。
1、编译
编译或者准备一个SQL语句,就是把它编译为虚拟数据库引擎(VDBE)可读的字节码。
对应的函数声明为:
int sqlite3_prepare_v2(
sqlite3 *db, /*数据库句柄*/
const char *zSql, /*SQL文本,UTF-8编码的*/
int nBytes, /*zSql的字节长度*/
sqlite3_stmt **ppStmt, /*输出:语句句柄*/
const char **pzTail /*输出:指向zSql未使用部分的指针*/
)
说明:
- sqlite3_prepare_v2() 只编译zSql字符串中的第一个SQL语句(zSql字符串中可能包含多个SQL语句)。
- 然后分配这个语句执行时所需的所有资源,并将其字节码关联到这个语句的句柄(也就是ppStmt参数指定的语句句柄)。
- ppStmt:语句的句柄ppStmt 依赖于所编译的数据库模式。如果在准备或执行语句期间,模式改变,sqlite3_prepare_v2() 会自动重新编译语句。若重新编译失败,就会在sqlite3_step()调用时返回SQLITE_SCHEMA错误。
- pzTail:在调用sqlite3_prepare()后,pzTail会指向zSql字符串中的下一条语句的起始位置。使用pzTail,会使执行一批SQL命令变得更容易。
2、执行
准备就绪后,下一步就是执行sqlite3_step(),
声明如下:
int sqlite3_step(sqlite3_stmt *pStmt);
说明:
- sqlite3_step()接收的参数是sqlite3_prepare_v2()输出的参数ppStmt。
- sqlite3_step()直接与VDBE通信,执行一个又一个字节码指令来执行SQL语句。
- 在第一次调用sqlite3_step()时,VDBE会获取执行命令所需的数据库锁。
- 对于不返回数据的SQL语句,第一次sqlite3_step()后就执行完SQL语句了,并返回一个指示结果的代码。
- 对于返回数据的SQL语句,如select语句,第一次调用sqlite3_step()后,将语句定位在第一个记录的B-tree游标上,后续调用sqlite3_step()会一次将光标定位在结果集内的后续记录上,并返回SQLITE_ROW,直到返回SQLITE_DONE,表示游标已到达结果集末尾。
3、完成与重置
语句执行结束后,必须终止。可使用下面函数之一:
int sqlite3_finalize(sqlite3_stmt *pStmt);
int sqlite3_reset(sqlite3_stmt *pStmt);
说明:
- sqlite3_finalize():关闭语句,释放资源,提交或回滚任何隐式事务,清除日志文件并释放相关联的锁。
- 若要重复使用语句,可使用sqlite3_reset()。与sqlite3_finalize的差别在于,sqlite3_reset会保留与语句关联的资源,以便重新执行,而不用再次调用sqlite3_prepare()来编译SQL命令。
sqlite_complete():寻找字符串中的终止符:分号。
三、获取记录
准备查询提供了获取记录信息的更多选择。
获取结果集中的字段数,函数声明如下:
int sqlite3_column_count(sqlite_stmt *pStmt);
int sqlite3_data_count(sqlite3_stmt *pStmt);
说明:
- sqlite3_column_count():返回与语句句柄关联的字段数量;若语句不是select语句,则返回0。
- 在sqlite3_step()返回SQLITE_ROW时,返回当前记录的列数。只有语句句柄有有效的游标时,才可以正常工作。
1、获取列(字段)信息
获取当前记录每一列的列名称,函数声明如下:
cont char *sqlite3_column_name(
sqlite3_stmt*, /*语句句柄*/
int iCol /*列的顺序*/
)
获取每个列的存储类,函数声明如下:
int sqlite3_column_type(
sqlite3_stmt*, /*语句句柄*/
int iCol /*列的顺序*/
)
说明:该函数返回五个存储类对应的整数值:
- #define SQLITE_INTEGER 1
- #define SQLITE_FLOAT 2
- #define SQLITE_TEXT 3
- #define SQLITE_BLOB 4
- #define SQLITE_NULL 5
获取每个列声明的数据类型,函数声明如下:
const char *sqlite3_column_decltype(
sqlite3_stmt*, /*语句句柄*/
int iCol /*列的顺序*/
)
说明:
- 如果结果集中的列与实际表中的列不对应(不对应的例子如,结果集中的列是要返回一个文本值、表达式、函数、聚合结果等,而不是实际表中的列),那么这个函数就会返回其声明类型为NULL。
获得某一列的其他信息
const char *sqlite3_column_database_name(sqlite3_stmt *pStmt, int iCol);
const char *sqlite3_column_table_name(sqlite3_stmt *pStmt, int iCol);
const char *sqlite3_column_origin_name(sqlite3_stmt *pStmt, int iCol);
说明:
- sqlite3_column_database_name:返回与这个列相关的数据库
- sqlite3_column_table_name:返回与这个列相关的表
- sqlite3_column_origin_name:返回在schema中定义的实际名称(别名等)
- 这些函数只有在编译SQLITE时,启用了SQLITE_ENABLE_COLUMN_METADATA预处理命令时才能用。
2、获取列(字段)值
获取当前记录每列的值:
xxx sqlite3_column_xxx(
sqlite3_stmt*, /*语句句柄*/
int iCol /*列的顺序*/
)
说明:
- 该函数会按按照期望的数据类型返回列的值:
int sqlite3_column_int(sqlite3_stmt*, int iCol);
double sqlite3_column_double(sqlite3_stmt*, int iCol);
long long int sqlite3_column_int64(sqlite3_stmt*, int iCol);
const void *sqlite3_column_blob(sqlite3_stmt*, int iCol);
const unsigned char *sqlite3_column_text(sqlite3_stmt*, int iCol);
const void *sqlite3_column_text16(sqlite3_stmt*, int iCol);
SQLite会将内部数据类型表示形式转换为所请求的类型:
| 内部类型 | 请求类型 | 转换 |
|---|---|---|
| NULL | INTEGER | 0 |
| NULL | FLOAT | 0.0 |
| NULL | TEXT | NULL |
| NULL | BLOB | NULL |
| INTEGER | FLOAT | 整型转浮点型 |
| INTEGER | TEXT | 整数的ASCII描述 |
| INTEGER | BLOB | 整数的ASCII描述 |
| FLOAT | INTEGER | 浮点型转整型 |
| FLOAT | TEXT | 浮点数的ASCII描述 |
| FLOAT | BLOB | 浮点数的ASCII描述 |
| TEXT | INTEGER | 使用atoi() |
| TEXT | FLOAT | 使用atoi() |
| TEXT | BLOB | 无变化 |
| BLOB | INTEGER | 先转成文本,再使用atoi() |
| BLOB | FLOAT | 先转成文本,再使用atoi() |
| BLOB | TEXT | 需要时加上\0000终结符 |
获取实际数据的长度,声明如下
int sqlite3_column_bytes(
sqlite3_stmt*, /*语句句柄*/
int iCol /*列的顺序*/
)
说明:
- 获取到长度以后就可以使用sqlite3_column_blob()复制二进制数据。
获取连接句柄
int sqlite3_db_handle(sqlite3_stmt*);
说明:
- sqlite3_errmsg()需要用到连接句柄
四、参数化查询
1、默认的参数顺序
API支持在SQL语句中指定参数,允许在后面为参数提供或绑定值。
参数化语句如下:
insert into episodes (id, name) values (?, ?)
说明:
-
sqlite3_prepare()识别到SQL语句中有参数。内部,为每个参数分配一个编号来唯一标识参数。 - 然后期望在执行前,对给定的参数绑定特定的值。
- 若没有绑定值给参数,
sqlite3_step()会使用null来代替。
绑定参数值的函数声明如下:
sqlite3_bind_xxx(
sqlite3_stmt*, /*语句句柄*/
int i, /*参数编号*/
xxx value /*要绑定的值*/
)
常用绑定函数如下:
int sqlite3_bind_int(sqlite3_stmt*, int, int);
int sqlite3_bind_double(sqlite3_stmt*, int, double);
int sqlite3_bind_int64(sqlite3_stmt*, int, long long int);
int sqlite3_bind_null(sqlite3_stmt*, int);
int sqlite3_bind_blob(sqlite3_stmt*, int, const void*, int n, void(*)(void*));
int sqlite3_bind_zeroblob(sqlite3_stmt*, int, int n);
int sqlite3_bind_text(sqlite3_stmt*, int, const char*, int n, void(*)(void*));
int sqlite3_bind_text16(sqlite3_stmt*, int, const void*, int n, void(*)(void*));
说明:
- 绑定函数分为两类,一类是标量值(int, double, int64, 和 NULL),一类是数组(blob, text, 和 text16)
- 标量值绑定和数组绑定的区别在于,后者需要一个长度参数和一个指向清理函数的指针。
-
sqlite3_bind_text()会自动转义引号字符
使用BLOB数组绑定函数,声明如下:
int sqlite3_bind_blob(
sqlite3_stmt*, /* 语句句柄 */
int, /* 顺序 */
const void*, /* 指向blob数据的指针 */
int n, /* 数据的字节长度 */
void(*)(void*) /* 清理处理程序 */
);
说明:
最后一个参数,也就是清理句柄
(1)有两个预定义的值,定义如下:
#define SQLITE_STATIC ((void(*)(void *))0)
#define SQLITE_TRANSIENT ((void(*)(void *))-1)
- SQLITE_STATIC:告诉数组绑定函数,数组内存驻留在非托管的控件,SQLite不会试图清理该控件
- SQLITE_TRANSIENT告诉绑定数组,数组内存常有变化,SQLite需要使用自己的数据副本,该副本在语句终止时会自动清除。
(2)还有一个指向自己的清理函数的指针,函数形式如下:
void cleanup_fn(void*)
语句结束时,SQLite会调用该清理函数,并将数组内存传入。
2、参数编号
给参数编号,而不是使用内部序列编号。参数编号的语法是问号后紧跟一个数字。
参考例子:
insert into episodes (id, cid, name) values (?100,?100,?101)";
说明:
- 参数编号100使用两次,表示需要将值绑定到多个地方,这样可以节省时间。
- 参数编号的范围是整数值1~999。尽量选择较小的数字
3、参数命名
给参数命名,在指定参数编号的地方指定一个名称。
区别在于,参数编号的语法是个问号?前缀,而参数命名的前缀是一个冒号或者@符号。
示例如下:
insert into episodes (id, cid, name) values (:cosmo,:cosmo,@newman)
4、Tcl参数
基本与参数命名完全相同,只是Tcl参数使用一些变量作为参数名称。
Tcl参数语法,与命名参数的区别在于,不是前面的参数加上冒号(:)或@符号,而是使用美元符号($)。
五、错误与异常
一定要在代码中关注的情况:
- 错误
- 繁忙情况
- 模式更改
1、错误处理
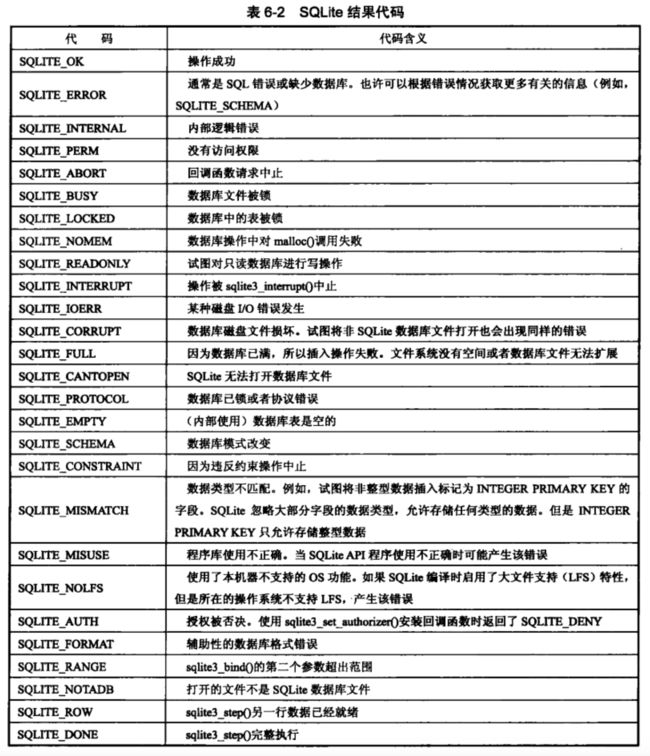
API函数,会返回整数结果码,这些结果码表示返回某种类型的错误代码。编程时,必须确保处理了各种可能的错误情况。
可以返回结果码的函数有:
- sqlite3_bind_xxx()
- sqlite3_close()
- sqlite3_create_collation()
- sqlite3_collation_needed()
- sqlite3_create_function()
- sqlite3_prepare_v2() *
- sqlite3_exec() *
- sqlite3_finalize()
- sqlite3_get_table()
- sqlite3_open_v2() *
- sqlite3_reset()
- sqlite3_step()
说明:标*的是常见的需要关注返回结果码的函数
可以使用sqlite3_errmsg()获取给定的错误的详细信息,声明如下:
const char *sqlite3_errmsg(sqlite3*);
说明:
- 参数为连接句柄。
- 返回连接上API调用产生的最近的错误。
-
没有错误,返回“not an error”.
 1.png
1.png
2、繁忙情况处理
当调用需要获取锁的API,但是SQLite无法得到锁时,会返回SQLITE_BUSY。
处理这种情况的方法有三种:
- 通过重新运行该语句,或者采取一些其他操作来自己处理SQLITE_BUSY;
- 让SQLite调用繁忙处理程序;
- 让SQLite等待(阻塞或睡眠)一段时间来等待锁解除。
2.1、用户自定义的繁忙处理
函数声明如下:
int sqlite3_busy_handler(
sqlite3*,
int(*)(void*,int),
void*
);
说明:
- 第二个参数:指向繁忙处理函数的函数指针。而繁忙处理函数的第二个参数是事先想同一个锁事件的处理程序的调用次数。
- 第三个参数:指向应用程序特定数据的指针,会作为繁忙处理函数的第一个参数。
- 繁忙处理函数并不一定保证被调用,如果sqlite检测到可能产生死锁,就会放弃调用繁忙处理程序。
- 唯一局限:繁忙处理程序可能不会关闭数据库。因为如果关闭数据库,会删除外面的执行查询的关键数据结构,并导致程序崩溃。
3、模式改变处理
在sqlite3_prepare()和sqlite3_step()之间,发生模式更改发生了。
这种情况发生时,唯一应对的方法是处理改变,并重新开始。因为已编译的VDBE可能会指向一个已经不存在的或者位置发生改变的数据库对象。
可能会导致SQLITE_SCHEMA错误:
- 分离数据库;
- 修改或安装用户自定义的函数或聚合;
- 修改或安装用户自定义的排序规则;
- 修改或安装授权函数;
- 清理数据库空间;
跟踪SQL语句执行的操作:
void *sqlite3_trace(
sqlite3*,
void(*xTrace)(void*,const char*),
void*
);
六、操作控制
API提供一些函数,在编译或运行时监视或管理SQL命令。
1、提交钩子
监视给定连接上的事务提交事件,声明如下:
void *sqlite3_commit_hook(
sqlite3 *cnx, /* 数据库句柄 */
int(*xCallback)(void *data), /* 回调函数 */
void *data /* 应用程序数据 */
);
说明:
- 当连接cnx上发生提交事务时,触发xCallback回调函数;
- data为回调函数xCallback的参数
- 如果xCallback返回非零值,提交将转为回滚
- xCallback中传入NULL,会禁用当前注册函数;
- 一个连接只能注册一个回调函数,如果没有注册过,sqlite3_commit_hook会返回NULL。如果以前注册过,会返回以前参数data值。
2、回滚钩子
监视给定连接上的回滚事件,声明如下:
void *sqlite3_rollback_hook(
sqlite3 *cnx,
void(*xCallback)(void *data),
void *data
);
3、更新钩子
监视给定连接上的所有更新、插入、删除操作,声明如下:
void *sqlite3_update_hook(
sqlite3 *cnx,
void(*)(void *, int, char const*, char const*, sqlite_int64),
void *data
);
其中第二个参数,也就是回调函数的声明如下:
void callback (
void * data,
int operation_code,
char const *db_name,
char const *table_name,
sqlite_int64 rowid
),
说明:
- data为sqlite3_update_hook的第三个参数;
- operation_code:代表插入、更新、删除操作;
- db_name和table_name分别代表数据库名和表名;
- rowid为受影响的行;
- 系统表上的操作不会调用回调函数。
4、授权函数
监控或控制查询语句的编译,提供了一种限制某种SQL操作或否决对数据库中特定表或字段访问的方法:
int sqlite3_set_authorizer(
sqlite3*,
int (*xAuth)( void*,int,
const char*, const char*,
const char*,const char*),
void *pUserData
);
授权函数的形式如下:
int auth(
void*, /* user data */
int, /* event code */
const char*, /* event specific */
const char*, /* event specific */
const char*, /* database name */
const char* /* trigger or view name */
);
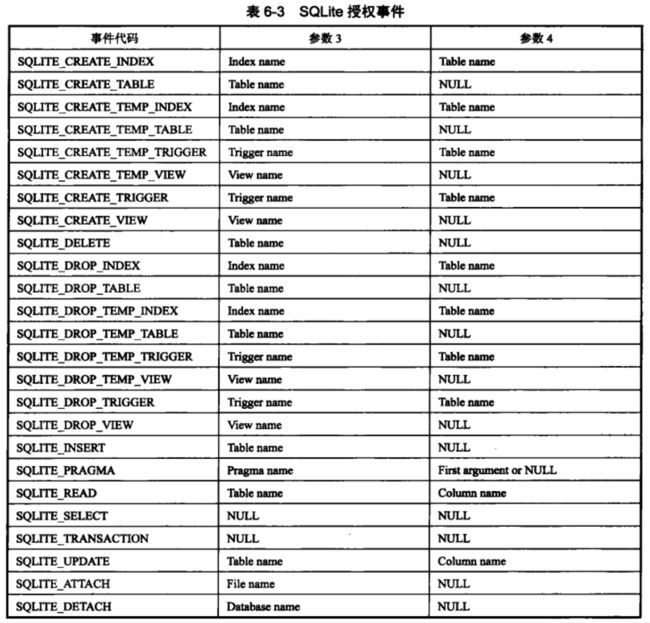
auth各参数的说明:
- 第一个参数,是sqlite3_set_authorizer的第一个参数传来的
- 第二个参数,是表6-3中的某个常量,代表授予的操作权限的类型
- 第三、四个参数,是具体的事件代码,在表6-2中
- 第五个参数,是数据库名称
- 第六个参数,是负责访问尝试的最内层的触发器或视图。为null,代表访问直接来自顶级的SQL语句。
-
返回值为SQLITE_OK、SQLITE_DENY,、 SQLITE_IGNORE中的一个。
 2.png
2.png
终止给定连接上的悬挂数据库操作:
void sqlite3_interrupt(
sqlite3* /* 连接句柄 */
);
按组合键Ctrl+C时会调用这个函数
让应用程序在长时间运行的查询过程中为用户提供反馈信息:
void sqlite3_progress_handler(
sqlite3*, /* 连接句柄 */
int frq, /* 调用频率 */
int(*)(void*), /* 回调函数 */
void* /* 应用程序数据 */
);
七、线程
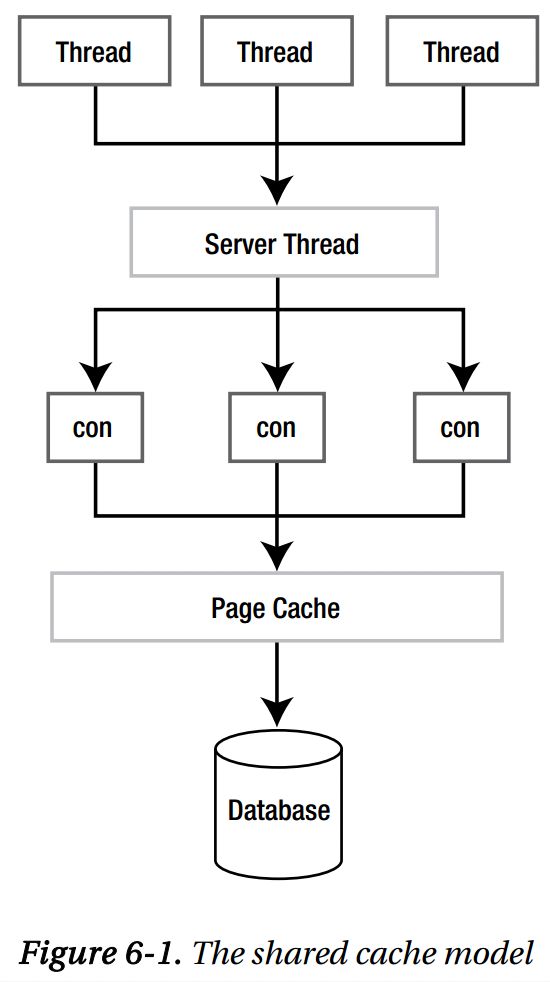
1、共享缓存模型
- 允许一个进程中的多个连接使用共同的缓存和不同的并发模型。
- 这个图是为嵌入式服务器设计的,这个服务器中的单线程可以代表其他多个线程有效的管理多个数据库连接。
- 线程向服务器中发送SQL语句,服务器使用分配给该线程的连接来执行,并把结果回传给线程。
- 线程可以发起命令,控制自己的事务,只是其实际的连接,存在于另一个线程(服务器线程)中,被服务器线程管理着。
-
共享缓存模式使用表锁,分别保持读连接和写连接。表锁只存在于共享缓存下的连接。
 3.png
3.png
共享缓存模式中的连接使用的不同并发模型和隔离级别:
- 读提交隔离级别:连接不可以想已有读锁连接的表中写入。
- 读未提交隔离级别:连接不会在读取的表上加读锁,因此写操作可以在连接读取时修改表。
- 解锁通知:
2、线程和内存管理
与线程和内存管理相关联的函数:
void sqlite3_soft_heap_limit(int N);
int sqlite3_release_memory(int N);
说明:
- sqlite3_soft_heap_limit:将调用线程的当前软堆设置为N字节
- sqlite3_release_memory:当使用中线程的堆超过N字节时,会调用sqlite3_release_memory。返回值为实际释放的字节数。