每秒解析千兆字节的 JSON 解析器开源了

本文转自我们的网站 InfoQ,译者无明。除了推荐simdjson 之外,还想测试一下微信平台编辑器的代码样式功能。
事实证明,微信文章的代码展示能力很强了。非常棒。
近日,GitHub 开源了一 JSON 解析器 simdjson,通过与其他常用解析器的对比实验,结果显示,simdjson 的解析速度达到 2.2GB/s,远远秒杀其他解析器,在下文中,我们将为大家详细介绍 simdjson。以下全文为 simdjson 在 GitHub 上的文档。
JSON 文档在互联网上无处不在,服务器花费大量时间来解析这些文档。我们希望在进行完全验证(包括字符编码)的同时尽可能使用常用的 SIMD 指令来加速 JSON 的解析。
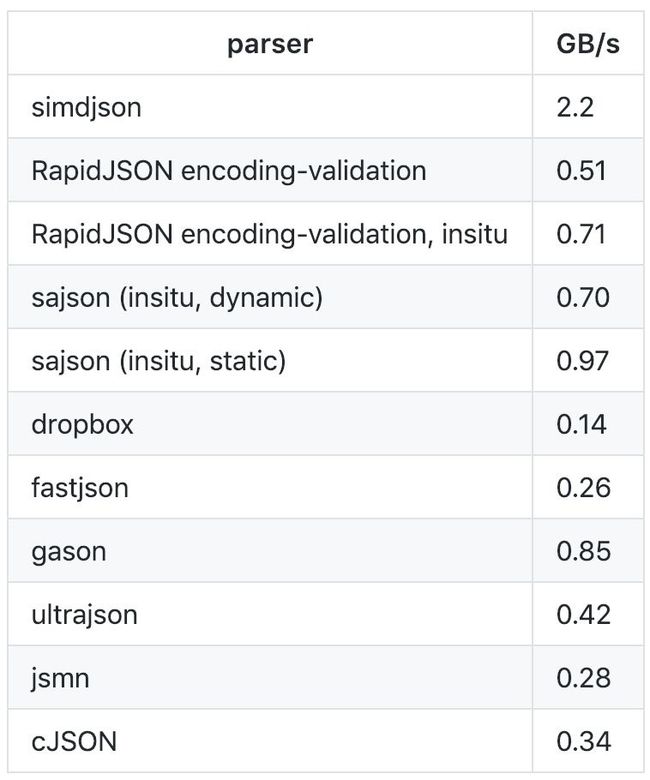
一些性能结果
相比最先进的解析器(如 RapidJSON),我们可能使用四分之一或更少的指令,也只有 sajson 的一半。据我们所知,simdjson 是第一个在商用处理器上以每秒千兆字节速度运行的完全验证 JSON 解析器。

在 Skylake 处理器上,各种解析器解析 twitter.json 文件的速度(以 GB/s 为单位)如下所示。
基本要求
通过 Visual Studio 2017 或更高版本支持 Linux、macOS 以及 Windows 等平台;
带有 AVX2 的处理器;
支持最近的 C++ 编译器(例如,GNU GCC 或 LLVM CLANG 或 Visual Studio 2017),我们假设是 C++ 17,GNU GCC 7 或更高版本,或者 LLVM 的 clang 6 或更高版本;
提供一些基准测试脚本,可以是 bash 和其他常用的实用命令程序,但是是可选的。
许可
代码采用 Apache License 2.0 许可。
在 Windows 下,我们使用 windows/dirent_portable.h 文件(在我们的库代码之外)构建了一些工具:基于自由的 MIT 许可。
代码示例
/...const char * filename = ... //// use whatever means you want to get a string of your JSON documentstd::string_view p = get_corpus(filename);ParsedJson pj;pj.allocateCapacity(p.size()); // allocate memory for parsing up to p.size() bytesbool is_ok = json_parse(p, pj); // do the parsing, return false on error// parsing is done!// You can safely delete the string contentfree((void*)p.data());// the ParsedJson document can be used here// js can be reused with other json_parse calls.
如果你不介意为每个新的 JSON 文档分配内存,也可以使用更简单的 API:
/...const char * filename = ... //std::string_view p = get_corpus(filename);ParsedJson pj = build_parsed_json(p); // do the parsing// you no longer need p at this point, can do aligned_free((void*)p.data())if( ! pj.isValid() ) {// something went wrong}
用法
简单的头文件
头文件可以看一下代码库的“singleheader”,用法可以看一下“amalgamation_demo.cpp”文件。这里不要求使用特定的构建系统:只需要将文件复制到项目中的路径中即可。然后,你就可以包含它们:
int main(int argc, char *argv[]) {const char * filename = argv[1];std::string_view p = get_corpus(filename);ParsedJson pj = build_parsed_json(p); // do the parsingif( ! pj.isValid() ) {std::cout << "not valid" << std::endl;} else {std::cout << "valid" << std::endl;}return EXIT_SUCCESS;}
注意:在某些环境中,可能需要预编译 simdjson.cpp,而不是包含它。
在 Linux 或 macOS 等平台上使用旧版 Makefile
要求:最近的 clang(或 gcc)和 make。我们建议至少使用 GNU GCC/G ++ 7 或 LLVM clang 6,Linux 或 macOS 系统。
测试:
makemake test
运行基准测试:
make parse./parse jsonexamples/twitter.json
在 Linux 上,parse 命令提供了性能计数器的详细分析。
运行其他作为比较的基准测试(使用其他解析器):
make benchmark使用 Linux 或 macOS 等平台上的 CMake
要求:需要最新版本的 cmake,在 macOS 上,安装 cmake 的最简单方法可能是使用 brew。
brew install cmake你需要一个像 clang 或 gcc 这样的新版编译器。我们建议至少使用 GNU GCC/G ++ 7 或 LLVM clang 6。例如,你可以使用 brew 安装最新的编译器:
brew install gcc@8可选:你需要通过设置 CC 和 CXX 变量告诉 cmake 你希望使用哪个编译器。在 bash 中,你可以使用 export CC = gcc-7 和 export CXX = g+±7 等命令。
构建:在项目代码库中执行以下命令:
mkdir buildcd buildcmake ..makemake test
CMake 将会构建出一个库。默认情况下,它构建的是一个共享库(例如,Linux 上的 libsimdjson.so)。
你可以构建一个静态库:
mkdir buildstaticcd buildstaticcmake -DSIMDJSON_BUILD_STATIC=ON ..makemake test
在某些情况下,你可能希望指定编译器,尤其是当系统默认编译器太旧的情况下。你可以按以下步骤操作:
brew install gcc@8mkdir buildcd buildexport CXX=g++-8 CC=gcc-8cmake ..makemake test
通过 Visual Studio 在 Windows 上使用 CMake
我们假设你拥有一台至少装有 Visual Studio 2017 的普通 Windows PC,并支持 AVX2 的 x64 处理器(2013 Haswell 或更高版本)。
从 GitHub 获取 simdjson 代码,例如,使用 GitHub Desktop 克隆它。
安装 CMake。在安装时,请确保可以从命令行使用 cmake。请选择最新版本的 cmake。
在 simdjson 中创建一个子目录,例如 VisualStudio。
在 shell 中转到这个新创建的目录。
在 shell 中键入 cmake -DCMAKE_GENERATOR_PLATFORM=x64 …(或者,如果要构建 DLL,可以使用命令行 cmake -DCMAKE_GENERATOR_PLATFORM=x64 -DSIMDJSON_BUILD_STATIC=OFF …)。
最后一个命令在新创建的目录(例如 simdjson.sln)中创建了一个 Visual Studio 解决方案文件。在 Visual Studio 中打开这个文件。你现在应该能够构建项目并运行测试。例如,在“Solution Explorer”窗口中,右键单击“ALL_BUILD”,并选择“Build”。要测试代码,仍然在 Solution Explorer 窗口中,选择 RUN_TESTS,再选择 Build。
工具
json2json mydoc.json 解析文档,构造模型,然后将结果输出到标准输出。
json2json -d mydoc.json 解析文档,构造模型,然后将模型输出到标准输出。格式在随附的文件 tape.md 中有描述。
minify mydoc.json 缩小 JSON 文档,将结果输出到标准输出。缩小意味着删除不必要的空格。
范围
我们提供了一个非常快的解析器。它根据各种规格对输入进行完全的验证。解析器会构建一个不可变(只读)的 DOM(文档对象模型),供后续访问。
为了简化工程,我们做了一些假设。
支持 UTF-8(以及 ASCII),没有别的(没有 Latin,没有 UTF-16)。我们不认为这是一个真正的限制,因为我们不认为会有哪个严肃的应用程序需要在没有 ASCII 或 UTF-8 编码的情况下处理 JSON 数据。
我们将字符串存储为以 NULL 作为终止符的 C 字符串。因此,我们假设字符串中不包含 NULL 字符。
我们假设支持 AVX2,这在 AMD 和英特尔生产的所有最新主流 x86 处理器中都可用。不支持非 x86 处理器,尽管我们可以支持。我们计划支持 ARM 处理器。
如果发生故障,我们只会报告故障,而不会指出问题的性质。
在规范允许的情况下,我们允许对象内存在重复的 key。
性能针对跨越几千字节到几兆字节的 JSON 文档进行了优化:解析很多小型 JSON 文档和一个大 JSON 文档的性能问题是不一样的。
我们的目标不是要提供通用的 JSON 库。像 RapidJSON 这样的库不仅提供了解析功能,它还可以用来生成 JSON,并提供了各种其他方便的功能。我们只解析文档。
特性
不需改输入的字符串。(像 sajson 和 RapidJSON 这样的解析器使用输入字符串作为缓冲区。)
将整数和浮点数解析为单独的类型,这样可以支持 [-9223372036854775808,9223372036854775808] 区间的 64 位整数,就像 Java 的 long 或 C/C++ 的 long long。在区分整数和浮点数的解析器中,并非所有解析器都支持 64 位整数。(例如,sajson 不支持包含大于或等于 2147483648 整数的 JSON 文件。FreeJSON 将长整数解析为浮点数。)当我们无法将整数表示为带符号的 64 位值时,我们就拒绝解析 JSON 文档。
在解析过程中进行完整的 UTF-8 验证。(像 fastjson、gason 和 dropbox json11 这样的解析器不会进行 UTF-8 验证。)
完全验证数字。(像 gason 和 ultranjson 这样的解析器会接受 [0e+] 这样的数字。)
验证字符串内容中的未转义字符。(像 fastjson 和 ultrajson 这样的解析器接受字符串中未转义的换行符和制表符。)
架构
解析器分三个阶段:
阶段 1,(查找标记)快速标识结构元素、字符串等。我们在这个阶段验证 UTF-8 编码。
阶段 2,(结构构建)构建排序的“树”(物化为磁带),以方便访问数据。我们在这个阶段解析字符串和数字。
访问已解析的文档
以下是将解析后的 JSON 转储回字符串的代码示例:
ParsedJson::iterator pjh(pj);if (!pjh.isOk()) {std::cerr << " Could not iterate parsed result. " << std::endl;return EXIT_FAILURE;}compute_dump(pj);//// where compute_dump is :void compute_dump(ParsedJson::iterator &pjh) {if (pjh.is_object()) {std::cout << "{";if (pjh.down()) {pjh.print(std::cout); // must be a stringstd::cout << ":";pjh.next();compute_dump(pjh); // let us recursewhile (pjh.next()) {std::cout << ",";pjh.print(std::cout);std::cout << ":";pjh.next();compute_dump(pjh); // let us recurse}pjh.up();}std::cout << "}";} else if (pjh.is_array()) {std::cout << "[";if (pjh.down()) {compute_dump(pjh); // let us recursewhile (pjh.next()) {std::cout << ",";compute_dump(pjh); // let us recurse}pjh.up();}std::cout << "]";} else {pjh.print(std::cout); // just print the lone value}}
下面的函数将找出所有的 user.id 整数:
void simdjson_traverse(std::vector<int64_t> &answer, ParsedJson::iterator &i) {switch (i.get_type()) {case '{':if (i.down()) {do {bool founduser = equals(i.get_string(), "user");i.next(); // move to valueif (i.is_object()) {if (founduser && i.move_to_key("id")) {if (i.is_integer()) {answer.push_back(i.get_integer());}i.up();}simdjson_traverse(answer, i);} else if (i.is_array()) {simdjson_traverse(answer, i);}} while (i.next());i.up();}break;case '[':if (i.down()) {do {if (i.is_object_or_array()) {simdjson_traverse(answer, i);}} while (i.next());i.up();}break;case 'l':case 'd':case 'n':case 't':case 'f':default:break;}}
深度比较
如果你想了解各种解析器如何验证给定的 JSON 文件:
make allparserscheckfile./allparserscheckfilemyfile.json
性能比较:
make parsingcompetition./parsingcompetition myfile.json
更广泛的比较:
make allparsingcompetition./allparsingcompetition myfile.json
英文原文:https://github.com/lemire/simdjson