霍尊是当前满红的古风歌手,他的歌曲优美而引人遐思,几乎成了唯美古装剧的必配。在听了n首之后,数据分析的本性难耐,码了段程序,一起看看他的歌词,主要写了什么。
用的技巧不复杂,就是结巴分词和词云图。以前也有很多人用来分析其他歌手比如汪峰,周杰伦。所以在此之前还搜了一下,好像没人讲霍尊。开干。所用程序是R语言。
首先安装包,jiebaR和wordcloud2
library(jiebaR)
library(wordcloud2)
library(readr)
setwd("E:")
其次读取文件。霍尊出道不算很久,歌曲不多,我大约搜到了20首古风歌曲,包括卷珠帘,桃花雨,粉墨等等,现代歌没有录入(比如玫瑰堡垒,比如天气预报报一报(这歌名是什么鬼)),以免影响境界。
然后做成txt文本文件。
读取和分词有两个办法,我先试的是直接用read_table读取txt文件,然后用worker函数分词,但这样的结果会很怪,重复的词后面会有词频,比如“的_3”,好烦恼。看以前的文章不会有这样的现象,不知道是不是包的改动or版本的问题。
改为scan后用segment函数,就好了。
f <- scan('E:/hz.txt',sep='\n',what='',encoding="UTF-8")
wk<-worker()
lyric <- segment(f,wk)
lyric <- lyric[nchar(lyric)>1]
length(lyric)
然后把1个字的删掉,算下总数,一共有1550个词语。

运用count函数,统计词频,然后按照顺序排序。
这里要注意的:
- 按理说sort也可以,比如lyric_50<-sort(tableword$freq,decreasing=T)[1:50],但我怎样也不行,然后就转了order
- 要把count(lyric)转化为数据框结构,这样左列是词语,右列是词频。
tableword<-as.data.frame(count(lyric))
tableword[order(tableword[,2],decreasing=T),]
然后就可以画词云图了,记得data也要用有词频的数据,而不是只有分词的文件,不然又要报错。
wordcloud2(tableword2,size=0.5,shape='square')

先用所有词试一下,满满的占了整屏幕,词语还是很优美的。语文老师大概会打85分。
好吧还是要筛选一下。只把词频在3以上的挑出来,而且字号调小。这次只有141个了。最多的词也只有6个词频,重复率并不高。
tableword2<-subset(tableword,tableword[,2]>=3)
wordcloud2(tableword2,size=0.5,shape='star')
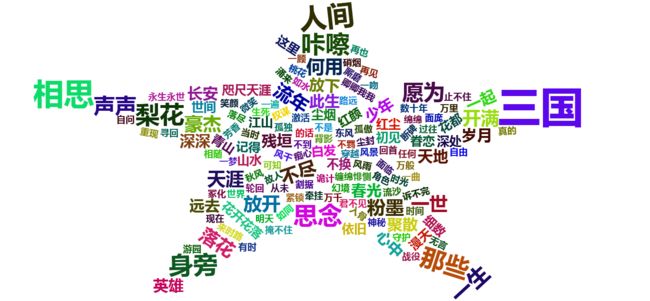
出来一个比较扁的星星。三国比较多是因为他唱了一首游戏主题曲《放开那三国》...
感想:霍尊歌词里重复的词语不多,比如风字开头的就有:风景,风骨,风雨,风月,风浪,风凉...这可能跟他歌曲的作词者比较不同有关,所以尽管题材趋同,但每一首还能给人较为清新的感觉。
潜力还很大嘛。看好你哦!
所选歌曲:1.惜春词 2.桃花雨 3.天行九歌 4.梦诛缘 5.粉墨 6.孤芳不自赏 7. 梨花落 8. 伊人如梦 9. 之子于归 10. 卷珠帘 11. 青云志 12.素颜 13. 不送贴 14.花雅禅 15.东风引 16.玉佛传灯 17.木棉 18. 放开那三国 19. 春宴 20.时光不忘
参考文章:
http://blog.csdn.net/sinat_26917383/article/details/51620019