背景
鉴于上次一篇文章——“云HBase小组成功抢救某公司自建HBase集群,挽救30+T数据”的读者反馈,对HBase的逆向工程比较感兴趣,并咨询如何使用相应工具进行运维等等。总的来说,就是想更深层理解HBase运维原理,提高运维HBase生产环境的能力,应对各种常见异常现象。不同的读者对hbase的了解程度不同,本文不打算着重编写一个工具怎么使用,而是从HBase的运维基础知识介绍开始讲解。为了能帮助大部分读者提高HBase运维能力,后续会写个“HBase运维系列” 专题系列文章。

介绍
相信很多自建HBase的企业会经常碰到各种各样的hbase运维问题。比如使用HBase的时候,HBase写入一段时间后开始RegionServer节点开始挂掉,重启RegionServer发现启动很慢,很多region出现RTI问题,导致读写某个region的业务hang住了 。还有一些人的HBase集群多次运维尝试后,直接HBase启动不了了,meta表上线就开始报错,导致最终业务不能正常上线运行等等系列问题。本文就HBase运维的原理基础开始入手,重点讲解数据完整性,以及元数据“逆向工程”恢复数据完整性的原理方法。开启后续一系列的HBase运维知识讲解。
HBase目录结构
本文就1.x版本进行讲解,不同版本大致相通。HBase在HDFS上会单独使用一个目录为HBase文件目录的根目录,通常为 “/hbase”。基于这个目录下,会有以下目录组织结构:
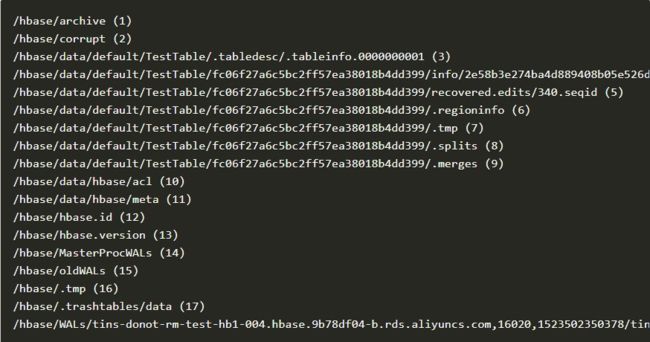
(1) 进行snapshot或者升级的时候使用到的归档目录。compaction删除hfile的时候,也会把就的hfile归档到这里等。
(2) splitlog的corrupt目录,以及corrupt hfile的目录。
(3) 表的基本属性信息元文件tableinfo。
(4) 对应表下的hfile数据文件。
(5) 当splitlog发生时,一个RS的wal会按照region级别split WALs写到对应目录下的的recovered.edits目录上,使得此region再次被open的时候,回放这些recovered.edits 日志。
(6) regioninfo文件。
(7) compaction等的临时tmp目录。
(8) split时临时目录,如果上次region的split没有完成被中断了,这个region再open的时候会自动清理这个目录,一般不需要人工干预。
(9) merges时的临时目录,和split一样,如果没有正常完成的时候被中断了,那么他会在下次被open的时候自动清理。一般也不需要人工干预。
(10) acl 开启HBase权限控制时的权限记录系统表
(11) meta 元数据表,记录region相关信息
(12) hbase.id 集群启动初始化的时候,创建的集群唯一id。可以重新fix生成
(13) hbase.version hbase 软件版本文件,代码静态版本,现在都是8
(14) master执行过程程序的状态保存,用于中断恢复执行使用。
(15) oldWALs 历史wal,即wal记录的数据已经确认持久化了,那么这些wal就会被移到这里。splitlog完成的那些就日志,也会被放到这里。
(16) tmp 临时辅助目录,比如写一个hbase.id文件,在这里写成功后,rename到 /hbase/hbase.id
(17) /hbase/.trashtables/data 当truncate table或者delete table的时候,这些数据会临时放在这里,默认1小时内被清
(18) 记录着一台RegionServer上的WAL日志文件。可以看到它是regionserver名字是有时间的,即下一次启动时RS的wal目录就会使用新的目录结构存放wal,这个旧的RS wal 目录就会被splitlog过程拆分回放
HBase涉及的主要文件及用途
HDFS静态文件,HDFS上的HBase 数据完整性
1. hfile文件:数据文件,目前最高版本也是默认常用版本为 3。 hfile文件结构细节可以参考官网http://hbase.apache.org/book.html#_hfile_format_2。我们这里逆向生成元数据主要使用到了HFile fileinfo的firstkey、lastkey信息。
2. hfilelink文件: 在hbase snapshot时用到, migration upgrade 也会使用到。很少碰到这类文件的运维问题,这里不作过多介绍。
3. reference文件:用来指定half hfile,一个region有reference时,这个region不能split。split/merge会创建这个。进行compaction后生成新的hfile后,会把这个reference删除。hfile的reference文件名格式一般是 hfile.parentEncRegion。如:/hbase/data/default/table/region-one/family/hfilename。其region-two有reference hfile文件名格式为:/hbase/data/default/table/region-two/family/hfile.region-one 通常无效引用就是 region-one的hfile不存在了,那么这个引用就会失效。他的修复方法一般是把reference无效的引用移除。
4. ".regioninfo" 文件,保存着 endkey/offline标志/regionid/regionName/split标志/startkey/tablename等
5. tableinfo文件这类文件保存着 tableName/table属性信息/table级别config信息/family信息。其中family信息保存着 famliyName/famiy属性/famliy级别config信息等。
通常,table属性有:REGION_MEMSTORE_REPLICATION,PRIORITY,IS_ROOT_KEY等,一般这些属性默认也是根据配置的一样。family属性有:BLOCKSIZE,TTL,REPLICATION_SCOPE等,一般属性是根据配置使用默认的。
6. hbase:meta表数据内容格式
regionname, info:regioninfo, regioninfo的encodeValue值
regionname, info:seqnumDuringOpen, 序列号
regionname, info:server, region所在的server名
regionname, info:serverstartcode, regionserver 启动的timestamp
元数据逆向生成原理
上述介绍的数据文件中,HBase的主要的元数据主要由meta表、tableinfo、regioninfo构成。这里的逆向生成元数据指的是,根据数据hfile数据文件,反向生成regioninfo/tableinfo/meta表的过程。
1. 逆向生成tableinfo文件
case1. 通过从master进程内存中的tabledescritor cache 完整恢复tableinfo文件,此时恢复的tableinfo是完整的,和之前的完全一样。
case2. 当cache中没有加载过此表的tableinfo时,修复过程只能从表的目录结构list所有familyNames 来恢复tableinfo,这个时候只能得到的是列簇的名字,恢复tableinfo文件内容中,除了表名、列簇名一致,其他的属性均采用默认值。这个时候如果运维人员知道有什么属性是自定义进去的,那么就需要要手动再次添加进去。
2. 逆向生成regioninfo文件
hfile 中的fileinfo读取firstkey/lastkey 排好序,得到region下所有hfile的最大rowkey和最小rowkey,并根据tableinfo中的表名 完整恢复 regioninfo文件。主要这里只能恢复 表明/startkey/endkey, 其他属性如:offline标志,regionName,split标志,hashcode等均使用代码生成或者配置的默认值。
3. 逆向填充meta表行
regioninfo文件序列化,填入meta表 info:regioninfo 列,并同时写入默认的server,等它被再次open的时候,重新分配region到实际的regionserver上,并更新这里的数据行。
逆向工程除了上面的直接文件、数据内容修复外,还涉及到数据的完整性其他方面修复。一个表示由无穷小的rowkey到无穷大的rowkey范围组成,还可能会发生的问题如:region空洞、region重叠现象,如:
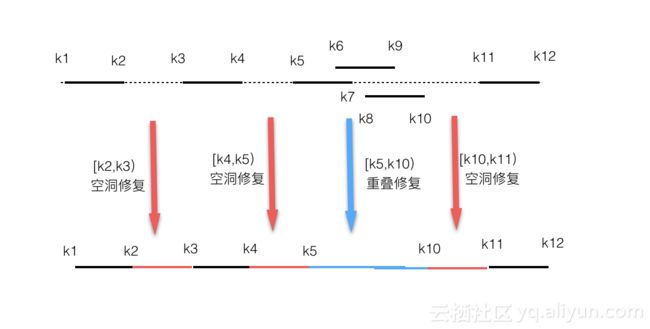
如果有region空洞的时候,就会使用他们的空洞边界作为startkey/endkey,再修复创建一个region目录及目录下的regioninfo文件。如果是region重叠,则会把重叠的region进行合并,取所有region的最大最小rowkey作为merge后新region的最大最小rowkey。
元数据工具修复
元数据的缺少或者完整性有问题,会影响系统运行,甚至集群直接不可用。最常见的如 meta表上线失败,region 上线open失败等。这里介绍两个工具,工具一: hbase hbck 在线修复完整性修复元数据信息,工具二:OfflineMetaRepair 离线重建 hbase:meta 元数据表。
在线hbck修复:
前提:HDFS fsck 确保 hbase跟目录下文件没有损坏丢失,如果有,则先进行corrupt block 移除。
步骤1. hbase hbck 检查输出所以ERROR信息,每个ERROR都会说明错误信息。
步骤2. hbase hbck -fixTableOrphones 先修复tableinfo缺失问题,根据内存cache或者hdfs table 目录结构,重新生成tableinfo文件。
步骤3. hbase hbck -fixHdfsOrphones 修复regioninfo缺失问题,根据region目录下的hfile重新生成regioninfo文件
步骤4. hbase hbck -fixHdfsOverlaps 修复region重叠问题,merge重叠的region为一个region目录,并从新生成一个regioninfo
步骤5. hbase hbck -fixHdfsHoles 修复region缺失,利用缺失的rowkey范围边界,生成新的region目录以及regioninfo填补这个空洞。
步骤6. hbase hbck -fixMeta 修复meta表信息,利用regioninfo信息,重新生成对应meta row填写到meta表中,并为其填写默认的分配regionserver
步骤7. hbase hbck -fixAssignment 把这些offline的region触发上线,当region开始重新open 上线的时候,会被重新分配到真实的RegionServer上 , 并更新meta表上对应的行信息。
离线OfflineMetaRepair重建:
前提:HDFS fsck 确保 hbase跟目录下文件没有损坏丢失,如果有,则先进行corrupt block 移除
步骤1: 执行 hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair -fix
最后,两个工具使用说明都比较详细,经过上面的基础介绍,相信都会看的懂的。这里不对工具再细致说明,工具的说明可以参考官网或者工具提示。题外话,有些开源组件设计的时候,向hbase元数据文件写入一些特有的信息,但是并没有修改到hbase工具的修复工具,或者它自己没有维护修复工具,如果这类文件损坏、丢失了,那么相应的组件就会运行不正常。使用这类组件的用户,应该不仅记录好你的表的基本结构,还要记录表的属性配置等,当发生修复运维行为的时候,主要再次核对确认。
小结
本文介绍了运维hbase基础原理中的数据完整性以及逆向元数据修复原理,并举例介绍两个逆向修复元数据的工具和实用执行步骤。后续会出系列文章,说明更多hbase运维基础、运作原理等,希望对大家的运维和使用HBase有所帮助。
详情请阅读原文