最近遇到两个故障,比较有趣。
某个业务程序是周期性的遍历某个目录,如果目录中出现了文件,就读取这个文件,处理数据,再把文件删除。在测试中出现,遍历动作花费很长时间,导致整个业务的性能下降。
另一个问题简单描述是 inode空间用尽,但有磁盘还有大量的空间。
这两个问题都与文件系统的理解有关。
Linux 文件系统的层次关系
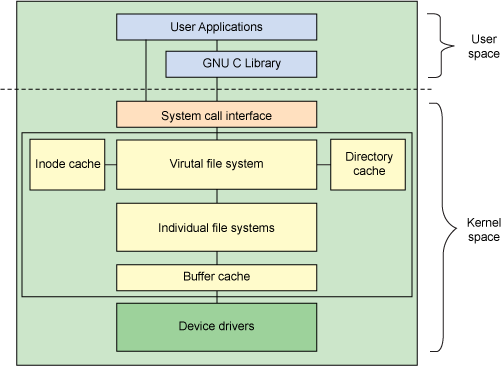
上图是 Linux 文件系统的一个层次图。
User Applications
我们的程序通常是通过 fopen, fwrite, fread, fclose函数去访问文件。这些函数都是在GNU C Library 中实现的。这些库函数对 system call 进行了封装,提供给上层应用使用。
不过,我们也可以直接通过 system call 去访问文件。通常,并不会鼓励大家这样做。
GNU C Library
正如上面所讲, 库封装了 system call ,为上层应用提供方便使用的文件函数。
System call interface
OS 向用户层提供了用于文件操作的 system call 。

上图是 File system call 的分类,非常丰富。这也是为什么上层应用通常不会直接使用 system call 的原因。直接使用,太过于复杂。
Virtual File System
为了可以使用不同的文件系统设计,OS通常都会设计一个中间层。在这个层之下,是实际的某种文件系统。VFS隐藏了不同文件系统之间的不同,向上暴露标准的接口。我们知道, Linux支持 ext2, ext3/4, xfs 等多种文件系统。这些不同的文件系统在启用后,用户并不需要为不同的文件系统使用不同的操作方法,或是编程模型。做到这一点,都是依赖于VFS的存在。
inode cache / directory cache
图中, VFS 的左右两侧各有一个 cache。Linux会在内核的内存空间中开辟缓存空间,用于保存被使用的 inode 信息。当用户访问某个文件时,这个文件的 inode 会被装入内存中。 在文件被关闭后,这个 inode 信息并不会立刻从内存中清除,而是暂时保存,必要时再被释放。这一点,与 Linux 系统的其它 cache 系统一样。
释放的机率由 /proc/sys/vm/vfs_cache_pressure 控制。缺省为100. 这个控制参数的说明如下:
vfs_cache_pressure
This percentage value controls the tendency of the kernel to reclaim the memory which is used for caching of directory and inode objects.
At the default value of vfs_cache_pressure=100 the kernel will attempt to reclaim dentries and inodes at a "fair" rate with respect to pagecache and swapcache reclaim. Decreasing vfs_cache_pressure causes the kernel to prefer to retain dentry and inode caches. When vfs_cache_pressure=0, the kernel will never reclaim dentries and inodes due to memory pressure and this can easily lead to out-of-memory conditions. Increasing vfs_cache_pressure beyond 100 causes the kernel to prefer to reclaim dentries and inodes.
Increasing vfs_cache_pressure significantly beyond 100 may have negative performance impact. Reclaim code needs to take various locks to find freeable directory and inode objects. With vfs_cache_pressure=1000, it will look for ten times more freeable objects than there are.
Individual File Systems
这一层就是实际的文件系统的实现。我们熟知的ext2, 3, 4, xfs就是在这一层。
以上是 Linux 系统中,文件系统实现的层次结构。那么,对于目录和文件,其相关的数据结构是什么样的呢? 这里介绍两个概念: Directory entry和 inode。
Directory entry and inode
所有的文件和子目录都是通过查找其父目录项来定位的,目录项中通过匹配文件名可以找到对应的索引节点号(inode),通过查找索引节点表(inode table)就可以找到文件在磁盘上的位置,整个过程下图所示。

对于 ext2 类型的文件系统来说,目录项是使用一个名为 ext2_dir_entry_2 的结构来表示的,该结构定义如下所示:
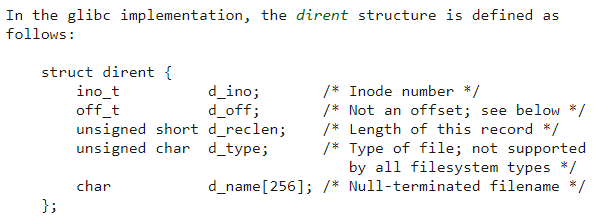
在 Unix/Linux 系统中,目录只是一种特殊的文件。目录和文件是通过 file_type 域来区分的,该值为 1 则表示是普通文件,该值为 2 则表示是目录。所以,目录本质是一个文件。它与普通文件一样是通过 inode 数据结构来表示的。inode 结构与问题关系不大,不再详述。
可以想到,目录这个文件中的目录项的数量是等于这个目录中的文件数量的。如果目录中的文件数量多,那么,这个目录项所占的空间也就相应较大。
我们换成一个生活中的例子来帮助理解:
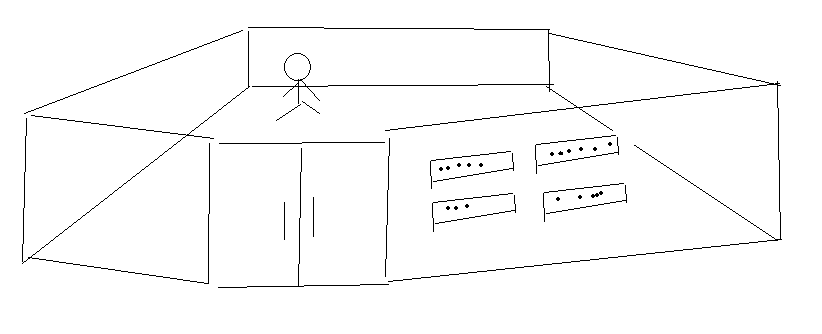
假设我们有一个房间,里面有人在工作,房间里每增加一个人,就在门口的墙上增加一个“铭牌”。房间里的人越多,铭牌的数量越多。人的名字越长,铭牌就越大。当我们需要找人时,在铭牌墙上花费的时间就会越多。
这个铭牌就是目录项。房间里的人就是文件。文件越多,目录项越多,占用的有磁盘空间就越大。遍历起来就越慢。
inode 的空间分配
文件系统中用来保存 inode 的数据块是有限的,不是动态分配的。它是在 make file system 时创建的。我们以 系统 的 root 分区为例,
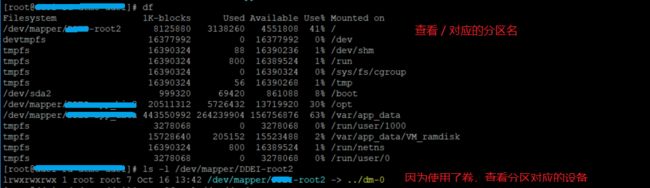
现在可以检查 dm-0 的文件系统信息:
tune2fs -l /dev/dm-0
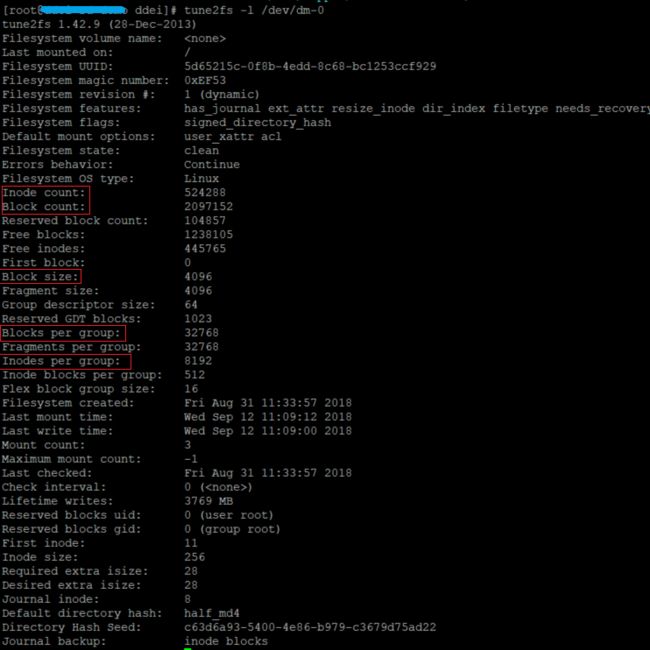
Block size * Block count = 4096 * 2097152 = 8GB 。 这是一块8GB的分区。
Block count / Blocks per group = 2097152 / 32768 = 64 。有64个块组。
每个块组有 32768 block 和 8192 inode, 所以, one inode <===> 32768/8192 = 4 blocks。 这意味着,一个 inode 结点 对应于 4个块。 每个块是 4KB。所以,一个 inode 结点对应于16KB。
对于一个分区,它预先分配的 inode 结点数量就可以计算出来了:
8GB / 16KB = 8MB / 16 = 1MB /2 = 0.5 * 1024 * 1024 =524288 = Inode count 这个数据,也可以在上图中找到。
BTW: inode 结点不是无限的,而是有限的。如果分区中保存了大量的文件,而小于16KB,那么,就会出现,磁盘还有空间,但 inode 已经耗尽的问题。程序无法再创建新的文件。
问题的验证和发现
有了以上的背景知识,我们进行了下面的实验。
新建一个目录
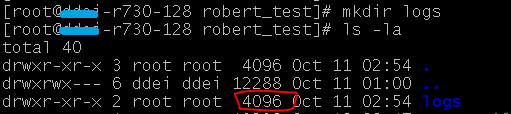
可以看到这个目录本身占用了 4096 字节的空间。
产生10000个文件,查看目录占用的空间
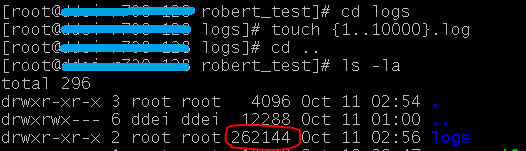
平均每个文件占用了26个字节。我们生成的文件名是 10000.log , 最长是9个字节。 参考上一节附上的 directory entry 数据结构, 8 + 4 + 4 + 1 + 8 (文件名平均长度) = 25。 这是一个粗略的计算,可以看到两者可以对应上。
再产生10000个文件,然后删除10000个文件,再查看目录占用的空间
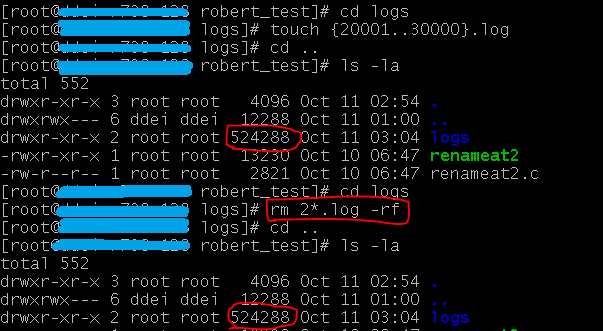
在增加了10000个文件后,目录占用的空间增长到了 524288 字节。然后,删除10000个文件,再次查看,目录仍是占用了524288 字节。
通过上面的实验,我们可以知道,目录本身也是代价。当目录下的文件数量不断增长,目录自身也会占用相当数量的空间。 以上面为例,如果该目录下存放了一百万个文件,相应的,目录自身将占用 26MB。而且,就算我们删除了这一百万个文件,这个空间不会被 释放。出现这个现象原因是,文件系统在文件被删除后,只是在块组的索引位图上标识一个文件相关的 inode 被释放。但并不 reclaim 相应的结点,并重整整个数据结构。与数据库中删除某个记录一样,都只是做个标记。因为,回收和重整是昂贵的。只有在有必要时,才进行。
让我们使用 stat 命令 得到 logs 目录的详细信息:

回到 遇到的问题,有了上面的实验,我们就能明白,这个问题的本质是, 存放海量文件的目录在长期运行过程中,目录自身占用的空间越来越大。我把这种情况称为“老化”。 当我们遍布一个目录时,本质就是在读取 “目录文件” , 如果这个目录文件很大,相应的读取就需要花费更多的时间,表现起来,就是遍历文件非常的慢。
glibc 的 opendir 函数使用了一个 32KB 的缓存区来读取 “目录文件”。 当我们申请一个 5MB 的缓存区,并直接调用 getdents system call 去读取 "目录文件",就会比 opendir 快数倍。
但是,提升性能不是无限的。如果 “目录文件” 越来越大,遍历目录就会越来越慢。最终,提升性能也无法得到满意的结果。
解决方案
我们得到了下面的几种解决方案
提升遍历性能
当前,我们已经通过使用大的缓存区,直接调用 getdents system call ,使遍历性能提高了4倍。Linux 还提供了两个不同的 kernel patch ,进一步提高了遍历性能。但这两个 patch 都并不在 发行版中,所以,使用这两个 patch 的风险较高。
truncate directory entry (回收或重整理目录项)
ext2/3/4是支持对目录项进行整理和回收。但进入这个工作,需要文件系统离线。相应的命令是:
e2fsck -D
e4fsck -D
使文件系统离线代价是相应大的,相当于系统暂停工作。一个稍合理的时机是在 重新启动时,进行这个工作。那么,何时进行整理?整理花费的时间是否可以预估?这些问题需要进一步的明确。
swap directory ( 适时更换目录 )
目录中的文件在移动时,是无代价的。因为,仅仅是把文件的 inode 填到其它的目录的目录项里。当一个目录“老化”了,我们可以新建一个目录,把这个目录里的文件移动到新的目录中,再把这个“老化”的目录删除掉,再把新目录重命名为之前“老化”的目录。这样,老化目录的目录项就释放了。
Linux 为移动文件提供了新的 system call 以保证原子化操作。
renameat2() withRENAME_WHITEOUT flag
一个开源程序提供了对这个新的 system call 的封装,并可以独立做为命令执行。https://gist.github.com/eatnumber1/f97ac7dad7b1f5a9721f
Directory layout design ( 目录结构设计 )
上层业务设计时,可以使用 uuid or timestamp 做为目录名,定期建立新的目录,把旧目录中没有处理完的文件再移动到新的的目录中,这样也可以避免老化问题。