前言:自己一股脑在学习机器学习,Python等知识点时,有种身在迷宫的感觉,出于以始为终的思维,开始从行业,应用场景来了解AI,机器学习等。本文节选《36kr-人工智能行业研究报告》
1,人工智能(AI)概述
它是使用机器代替人类实现认知,分析,决策等功能的综合学科。作为一种基础技术,理论上人工智能能够被用在各个基础行业。(如AI+金融,AI+医疗,AI+传统制造业等)。
2,AI产业链
AI产业链主要包括技术支撑层,基础应用层和方案集成层(或者说是应用场景层)。
技术支承层主要由AI芯片,传感器等硬件和算法模型(软件)两部分组成。其中传感器与IoT的感知层相似,包括GPU,FPGA,NPU等在内的AI芯片负责运算,算法模型则负责训练数据。
基础应用层的技术则是为了让机器完成对外部世界的探测,主要由计算机视觉,语音识别等感知层和语义识别等认知层构成,这些技术是机器能够做出分析判断的基础。此外,在感知与认知技术之下还有数据标注作为其底层支撑。

方案集成层是集成了某种或多种基础应用技术的,面向如工业,自动驾驶,家居,仓储物流,金融,医疗等不同应用场景的产品或方案。

3,数据标注介绍
数据是人工智能行业的燃料,虽然互联网积攒了海量数据,但是非结构化和难以融合两大特点一直是数据应用过程中的行业痛点。由此出现了专门负责数据标注的公司来完成数据结构化的初步工作。目前专注该领域的国内有海天瑞声,国外有Appen.。
数据标注的过程与作用:以海天瑞声为例,其资源库覆盖语音,文本,图像,视频等多个领域,其中语音库,利用手机,座机,车载以及其他特殊麦克风和嵌入式设备等语音终端获取语料,结合人工,隐马算法,拼接算法等对语音数据进行语义,语法,音素等多层次的标识,让机器从中学习规律,以便于实现人机语音交互技术的实现。另外还可根据特别情况,提供定制开发语音转写,标注辅助工具和软件。

当大量的非结构化被数据标注为结构化数据之后,就能够为其他AI公司所用了,这些结构化的数据主要被用来训练算法模型,然后应用到语音,语义,图像识别等技术,以及安防,自动驾驶等应用共场景。
4,语音识别
语音识别是将语音转换为文本的技术,是自然语言处理的一个分支。
前台的主要步骤分为信号搜集,降噪和特征提取三步,提取的特征在后台由经过语音大数据训练得到的语音模型对其进行解码,最终把语音转化为文本,实现达到让机器识别和理解语音的目的。

科大讯飞的语音识别技术:科大讯飞拥有六项核心技术,分别是语音识别,语音合成,自然语言处理,语音评测,声纹识别和手写识别。
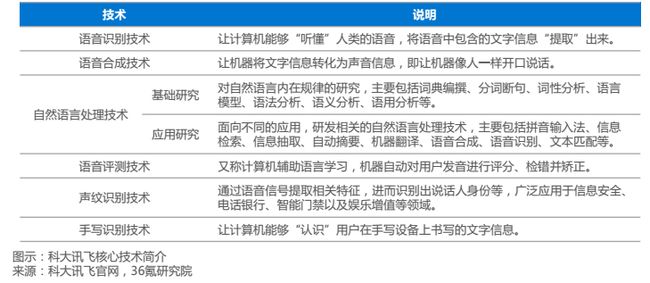
语义识别解决的是听得懂的问题,其最大的作用是改变人机交互的模式,将人机交互由最原始的鼠标,键盘转变为语音对话的方式。

关于语义识别领域的创业公司,国内代表为:出门智能360,出门问问,三角兽,蓦然认知等。
5,计算机视觉
计算机视觉(computer vision,简称CV)是指用计算机来模拟人的视觉系统,实现人的视觉功能,以适应,理解外界环境和控制自身运动。
主要解决物体识别,物体形状和方位确认以及物体运动判断这三个问题。
计算机识别系统通常需要三个过程:目标检测,目标识别,行为识别,分别解决“去背景”,“是什么”,“干什么”。

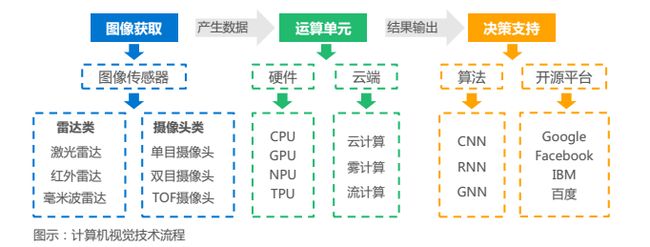
计算机视觉在技术流程上,首先要获得实时数据,此步骤可通过一系列传感器获得,少部分数据可直接在具备MESE功能的传感器端完成,大部分数据会继续传输至大脑平台,大脑运算单元和算法构成,在此处进行运算并给出决策支持。
计算机视觉应用场景可以分为两大类:图像识别和人脸识别,每类又可以继续划分动静四个类别,基本覆盖了目前计算机视觉的各项应用场景,其中动态人脸识别技术是目前创业热度最高的细分领域,尤其是金融和安防场景。

其代表性创业公司如下:
对于计算机视觉而言,其主要的瓶颈在于图片质量,光照环境的影响,现有的图片识别技术难以解决图像残缺,光线过曝,过暗的图像。此外受制于标记数据的体量和数量,若无大量,优质的细分应用共场景数据,该特定的应用场景的算法迭代很难实现突破。
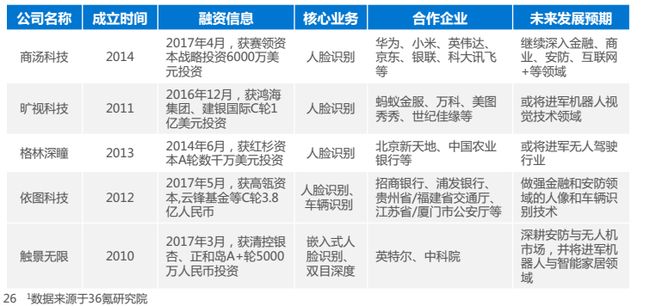
以商汤为例,介绍计算机视觉的应用场景:
