注:文章来源转载自书伴网站,如有侵权请告知。
在之前修复 Kindle 字典释义显示不完整的那篇文章里,曾提到 KindleUnpack 这款小软件,在文章中,主要是用它来“拆解” mobi 格式的字典文件,提取里面的相关源文件,以便进行分析、修改。最近 Kindle 伴侣 QQ 群中有小伙伴说网站还没有关于 KindleUnpack 的相关信息,所以专门撰写一篇文章来介绍一下,并同时将其放到“相关工具”中提供下载。
目录
一、什么是 KindleUnpack?有什么用?
二、KindleUnpack 软件或插件下载
三、KindleUnpack 插件版本的安装
方式 1:“从文件加载插件”安装
方式 2:“获取新的插件”安装
四、KindleUnpack 各版本的使用方法
1、Windows 系统下的独立版
2、Mac OS X 系统下的独立版
3、依附 Calibre 运行的插件版
五、KindleUnpack 提取出的文件结构
一、什么是 KindleUnpack?有什么用?
KindleUnpack (原 mobiunpack)是一款用 Python 写成的小程序,始发于电子书专业论坛 mobileread。它可以用来提取 Kindle 电子书如 mobi、azw3 等格式文件中的 HTML 内容、图像以及元数据文件,并能把这些文件按照 KindleGen 生成电子书的标准和形式放置。
对于 KF8 文件以及 Mobi 和 KF8 的混合文件[注1],它可以产生分离的 Mobi 和 KF8 文件[注2],以及包含在电子书中的原始源文件。此外,对于 KF8 文件,它还会生成一份 ePub 文件,不过,如果生成的 HTML 文件不符合 EPUB 标准,那生成的这个 ePub 文件也不会符合 EPUB 标准。对于亚马逊 .azw4 格式电子书,它可以提取出包含在该格式文件中的 PDF 文档。
KindleUnpack 对于一般人来说没有什么用途,但是对于喜欢自制电子书的小伙伴用途可就大了。比如看到一本电子书的版式或样式很漂亮,可以利用它对这本电子书进行拆解,然后分析其源文件,然后把自己喜欢的特性移植到自己的电子书项目中。是一个相当实用学习工具。
二、KindleUnpack 软件或插件下载
KindleUnpack 有两种形态,一种可以独立运行,另一种依附于 Calibre 的插件。独立运行的软件又提供了两个版本,分别为带界面的 pyw 格式 Python 脚本和支持拖放操作的 AppleScript 版本。另外,作者还提供了一个名为 mobiunpack 的单文件脚本[注3],该脚本需要在命令行中使用,且仅支持提取 mobi 格式电子书中的源文件,无法用于 KF8 标准的电子书,以供对 KF8 和 KindleGen 不感兴趣的小伙伴使用。需要注意的是,独立版本的 KindleUnpack 需要你的系统预先安装 Python 环境,否则可能无法正常运行。下面是各个版本的下载链接:
带界面的 pyw 格式 Python 脚本: KindleUnpack-080.zip | 百度网盘 (102.7KB)
支持拖放操作的 AppleScript 版本:KindleUnpack v0.80.app.zip | 百度网盘 (436.6KB)
仅支持 mobi 文件的单文件脚本:mobiunpack 32.py.zip | 百度网盘 (18.4KB)
依附于 Calibre 运行的插件版本:kindle_unpack_v0812_plugin.zip | 百度网盘 (104.0KB)
三、KindleUnpack 插件版本的安装
如果你习惯喜用 Calibre 管理电子书,可以直接把 KindleUnpack 集成到 Calibre 中,这样就不需要每次都运行它的独立程序了。在 Calibre 中安装 KindleUnpack 插件有两种方式:一种是直接加载下载到的插件文件,另一种就是直接在插件设置中获取该插件直接安装。下面分别作说明:
方式 1:“从文件加载插件”安装
打开 Calibre,点击“首选项”的“高级选项”下的【插件】,然后点击【从文件加载插件】按钮,在弹出的窗口中选择下载到的压缩包,点击【是】、【确定】,重启 Calibre 完成安装。
方式 2:“获取新的插件”安装
打开 Calibre,点击“首选项”的“高级选项”下的【插件】,然后点击【获取新的插件】,在弹出的窗口中的“Filter by name(按名称过滤)”一栏输入“KindleUnpack”,选中它,点击右下角的【安装】按钮安装。安装完毕后点击【现在重启 Calibre】按钮,重启后即可成功安装。
四、KindleUnpack 各版本的使用方法
KindleUnpack 的使用方法十分简单,下面对独立版和插件版分别简要说明一下步骤,以供参考。
1、Windows 系统下的独立版:
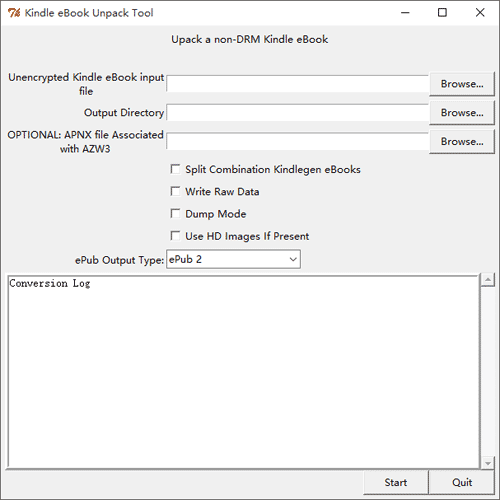
运行文件名为 KindleUnpack.pyw 的 Python 脚本,打开工作界面;
点击“Unencrypted Kindle eBook input file”后的【browse…】按钮选择一本电子书;
点击“Output Directory”后的【browse…】按钮选择生成文件的输出目录;
其他选项一般可保持默认,点击【start】按钮,稍等片刻即可完成拆解。
2、Mac OS X 系统下的独立版:
解压缩下载到的 zip 压缩包,可以看到一个 APP 文件,直接把电子书拖放到此 APP 图标上即可。
3、依附 Calibre 运行的插件版:
把电子书文件拖放到 Calibre 中;
选中电子书,点击软件右上方操控区域的那个 KindleUnpack(黄色的三角按钮图标),在弹出的菜单中将鼠标悬浮到带有绿色小锁的菜单,然后点击弹出的菜单“Unpack MOBI”(如果是 AZW3 文件会显示“Unpack AZW3”);
在弹出的窗口中选择指定输出的文件夹,点击【Open】按钮,稍等片刻即可完成拆解。
注意,KindleUnpack 只能用于无 DRM 保护的 Kindle 电子书。生成的时间根据电子书文件大小不同,处理时间长短也不同。
五、KindleUnpack 提取出的文件结构
对于 KF8 标准的如 azw3 格式的电子书,提取出来的原始文件结构一般如下所示:
├──── HDImages
├──── 高清图片文件(如果有的话)
├──── mobi7
├──── 所有图片(包括封面)
├──── mobi8
├──── META-INF
├──── container.xml
├──── OEBPS
├──── Fonts
├──── 字体文件(如果有的话)
├──── Images
├──── 所有图片(包括封面)
├──── Styles
├──── 所有 CSS 样式表文件
├──── Text
├──── 所有 HTML 格式的电子书内容
├──── content.opf
├──── toc.ncx
├──── XXXXXX.epub
├──── mimetype
对于 mobi 格式的电子书,提取出来的原始文件结构如下所示:
├──── HDImages
├──── High definition images if exist ...
├──── mobi7
├──── Images
├──── 所有图片(包括封面)
├──── book.html
├──── content.opf
├──── toc.ncx
—————————-
[注1] KF8 是亚马逊官方制定的新电子书标准,能很好地支持 CSS3 的很多属性,以获得更好的排版样式。我们平常经常见到的 azw3 文件就是标准的 KF8 标准电子书。因为老的 Kindle 设备不支持新标准,所以亚马逊会将老式的 mobi 格式混合在 azw3 文件内,以便兼容老的 Kindle 设备。
[注2] 这里的 mobi 文件和 KF8 文件实际上说的是一个标准,实际上分离出来文件,mobi 对应的就是 mobi7,KF8 对应的就是 mobi8。
[注3] KindleUnpack 0.61 就是由 mobiunpack 0.32 变化而来的。
—————————-
参考资料:
KindleUnpack (MobiUnpack): Extracts text, images and metadata from Kindle/Mobi files
[GUI Plugin] KindleUnpack – The Plugin