在机器学习中,模型的欠拟合和过拟合是需要格外注意的问题,同时也是经常发生的问题,其中过拟合最为常见.
欠拟合,即训练出的算法模型不足以表达数据间的关系.
过拟合,即训练出的算法模型过多地表达了数据间的关系,学习到的关系可能是一些噪声.
关于欠拟合和过拟合还结合 偏差 方差问题.可以参考另一篇笔记:
https://www.jianshu.com/p/6b32a46cd0fc
模型训练的目的在于对未知情况的预测,训练者关注的应该是模型的泛化能力,而非模型对于训练数据的拟合效果(当然了,两者是有密切的联系的,不能割裂来看待).
那么如何测试模型的泛化能力?
针对这一问题,常用的trick就是将数据集拆分为训练数据集和测试数据集.在训练数据集上训练模型,然后将模型运用到测试数据集上进行预测测试.同时,根据选定的性能指标对模型的性能进行评估.
根据模型在训练 和 测试数据集上的表现可以绘制出模型的复杂度曲线 :模型复杂度曲线能够表达模型的在训练集和测试集上的准确度和泛化能力的关系.

学习曲线
需要注意的是,往往并不是所有模型都能准确地绘制出模型复杂度曲线.幸运的是,所有模型都能绘制出学习曲线, 学习曲线能够清晰地描述模型的性能评价 泛化 和 过拟合情况.
以下两张图片中的学习曲线分别描述线性回归模型最佳拟合和过拟合的情况:
在最佳拟合的情况下,模型在test_data和train_data上的曲线最终都收敛到1.0附近,test_data和train_data都有着良好的表现,并且test_data上的收敛值值略大于train_data曲线上的收敛值,两者十分贴近这说明泛化能力也是较好的.
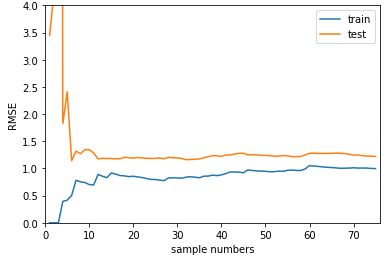
在过拟合的情况下,模型在test_data和train_data上的曲线都最终收敛,但是两条曲线的最终收敛值差值(曲线间隙)较大且test_data集合上收敛值偏大,这说明模型的泛化能力不够好.同时,train_data上曲线的收敛速度与收敛效果比最佳拟合图中的曲线更快更好,这说明模型本身是过拟合的.

关于学习曲线的绘制,这里给出实现代码:
需要说明的几点:
- 模型的性能评估,选用的标准是均方根误差RMSE
- algo 处传入不同的模型对象
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
def learn_curve_plot(algo,X_train,X_test,y_train,y_test):
train_score = []
test_score = []
for i in range(1,len(X_train)+1):
algo.fit(X_train[:i],y_train[:i])
y_train_predict = algo.predict(X_train[:i])
train_score.append(np.sqrt(mean_squared_error(y_train[:i],y_train_predict)))
y_test_predict = algo.predict(X_test)
test_score.append(np.sqrt(mean_squared_error(y_test,y_test_predict)))
plt.plot([i for i in range(1,len(X_train)+1)], np.array(train_score),label = 'train')
plt.plot([i for i in range(1,len(X_train)+1)], np.array(test_score),label = 'test')
plt.legend()
plt.axis([0,len(X_train)+1,0,4])
plt.show()