
什么是 sklean
sklean 是机器学习阶段最重要的库,sklean不仅能提供大量可用数据集,更是实现绝大多数著名的机器学习算法,sklean 的特点就是:装性好,几行代码就能使用,文档完善,容易上手,API 非常丰富
获取学习阶段可用数据集
机器学习是从统计发展而来的,永远也离不开数据,并且机器学习、深度学习的基础永远都是数据,也是为数据服务的
但是数据难得啊,公司级别的数据我们是拿不到的,那些都是要花大钱的,要不就是自己偷摸收集的。那我们在学习阶段从哪里获得数据资料呢,自然有地方:
-
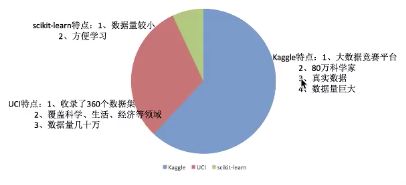
sklearn- sklearn 官网可以提供少量数据集,地址:https://scikit-learn.org/stable/datasets/index.html#datasets -
kaggle- kaggle 是数据挖掘,他的网站也能提供一些数据集,提一下啊 kaggle 已经是 google 的了,地址:https://www.kaggle.com/datasets -
UCI- UCI 是加州大学,是专业的学术机构,其提供不少专业数据集,地址:https://archive.ics.uci.edu/ml/index.php
这是他们之间的比较:
这里我们选用 sklean,sklean 这个库多好,把数据集和数据处理算法都提供了,业界就是需要像 sklean 这样的库啊,python 的特点就是库多,库的封装行都非常 Nice,几行代码可以完成很复杂的操作
安装 sklean
很简单,用 pip 安装即可,这里已经创建了独立的 python 环境了
pip3 install Scikit-learn
pip 的毕竟都是国外地址,所有有的朋友那里会很慢,这里大家可以使用清华的pip镜像
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple Scikit-learn
查看下 sklearn 装没装上,sklearn 需要 scipy、numpy 支持的,一般都会自动装上的,大家也去看看这俩有没有,没有也是用 pip 装一下就好了
pip3 list
加载 sklean 数据集
sklean下的datasets里面提供了大量可用数据集,数据集分2种:
-
本地数据集- 数据集不大,直接就集成在了datasets包里,使用:datasets.load_*()API 加载 -
远程数据集- 数据集非常大,很多数据集都是上G的,这就要求链接远程服务器下载了,使用:datasets.fetch_*(data_home=None)API 加载,参数是数据集下载到本地的地址,下载完成后,以后再用这个数据集就不用再去下载了,算是有个磁盘缓存吧。下载地址可以不写,默认是:根目录下的/scikit_learn_data/
* 号表示数据集的名字,比如我们要加载鸢尾花 iris 这个数据集,API 是:datasets.load_iris()
数据集对象类型
我们从 sklean 中加载得到的数据集,他的类型是:Bunch 继承自字典,我看着和 map 差不多,提供2种取值操作:
dist[key] = value-
dist.key = value- 还支持点属性的方式获取相应值
前文我们说过,机器学习中的一组数据统称数据集,而数据是由:特征值+目标值组成的,那么代码里我们拿到的数据集对象 Bunch 也应该由相应的属性,Bunch 里面有5个属性:
-
data- 特征值 -
targe- 目标值 -
DESCR- 描述 -
feature_names- 特征值名称 -
targe_names- 目标值名称
这是从代码的角度看,但是我们还是没看到数据集到底是个什么样子
经典的鸢尾花数据集
数据集 是 map + 二维数组,最外层采用 key/value 结构,value内部则是二维数组,每一行都是一个数据,也叫单元,每一列都是一个特征或是目标
为了更好的理解数据集,这里我们用鸢尾花这个 sklearn 上最经典的入门例子来看看:

学者们采集了鸢尾花的4种特性,然后把鸢尾花分成了3类。大家体会下,吧事物数据化就是这样的,就是分析你这类事物有什么明显的特点,抽象采集出来这就是特征了,然后你这类事物可以分种有代表性的类型,这就是目标了
导包
from sklearn.datasets import load_iris
加载代码:
from sklearn.datasets import load_iris
// 加载鸢尾花数据集
data = load_iris()
print(type(data))
print(data)
数据集本体: - 数据集本身是遵循 JSON 格式的
{
'data': array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[6.7, 3.3, 5.7, 2.5],
[6.7, 3. , 5.2, 2.3],
[6.3, 2.5, 5. , 1.9],
[6.5, 3. , 5.2, 2. ],
[6.2, 3.4, 5.4, 2.3],
[5.9, 3. , 5.1, 1.8]]),
'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]),
'target_names': array(['setosa', 'versicolor', 'virginica'], dtype='DESCR 描述里面其实有很多信息的,比如采集哪些特征,目标值分几类,里面的列表还统计出每个特征的最大值,最小值,平均值,标准差,相关系数,最后 References 里面还有相关参考,看着有点像短篇论文啦...
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%[email protected])
:Date: July, 1988
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
.. topic:: References
- Fisher, R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Mathematical Statistics" (John Wiley, NY, 1950).
- Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.
(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System
Structure and Classification Rule for Recognition in Partially Exposed
Environments". IEEE Transactions on Pattern Analysis and Machine
Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions
on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II
conceptual clustering system finds 3 classes in the data.
- Many, many more ...
.shape 我们还可以看数据,比如 data 由几行几列
print(data.data.shape)
(150, 4)
数据划分
数据划分 - 我们从 sklearn 上拿到的数据是为了做练习的,练习包括了训练模型和测试,这样我们就必须把拿到的数据做下划分才能在训练模型之后还能做下测试,检验模型做的好不好
一般我们都是遵循这个比例去划分训练和测试的数据比例的:
-
训练集:70% 75% 80% -
测试集:30% 25% 20%
API 在 sklearn.model_selection 包下面
// 导包
from sklearn.model_selection import train_test_split
train_test_split(x,y,test_size,random_state)
train_test_split 方法有4个参数,xy是必传,其他可以不写
-
x- 特征值 -
y- 目标值 -
test_size- 测试集的大小,默认是 0.25 -
random_state- 随机种子,在测试同一组数据集在多个算法下的效果时,为了保证公平性要使用相同的随机数种子
train_test_split 方法返回4个参数,一般我么你这样命名:
-
x_train- 训练集特征值 -
x_test- 测试集特征值 -
y_train- 训练集目标值 -
y_test- 测试集目标值
训练集和测试集一般我们使用这2个单词:
-
train训练集 -
test测试集
然后我们跑一下:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
data = load_iris()
x_train,x_test,y_train,y_test = train_test_split(data.data,data.target,test_size = 0.2)
print("训练集特征值:\n",x_train,x_train.shape)
取部分数据,要不太多了,可以看到训练集数据是 120 个
训练集特征值:
[[5. 3. 1.6 0.2]
[5.2 3.5 1.5 0.2]
[5.1 3.8 1.6 0.2]
[7.1 3. 5.9 2.1]
[5.9 3. 4.2 1.5]
[6.8 2.8 4.8 1.4]
[6.7 3.3 5.7 2.1]
[5.6 2.5 3.9 1.1]
[6. 2.2 5. 1.5]
[6.3 3.4 5.6 2.4]
[4.8 3. 1.4 0.1]] (120, 4)
最后
sklearn 是机器学习阶段最最最重要的库,在给我们提供了学习用数据的同时,也提供了大量的机器学习 API,包括大多数知名算法。本文这里只是给大家科普一下 sklearn 这个库,写的很啰嗦,后面特征工程那里就会使用到 sklearn 里面的算法了,大家拭目以待吧~