本文为本专题第3篇,如果你基础不错的话只看这一篇的讲解及源代码应该就能轻松实现批量下载所有文章了,基础稍差的可以先看一下前两篇,只要你有点基础,有点耐心,八成朋友都至少能照葫芦画瓢实现批量下载文章的功能。
一步步教你打造微信公众号文章爬虫(1)-综述
一步步教你打造微信公众号文章爬虫(2)-下载网页
有朋友反馈前两篇写得有点啰嗦,那这次就换个风格,只讲重点。有不懂的群里交流吧。
前面文章中我们搞定了下载一篇文章,接下来研究批量下载。
有的朋友可能会说:这个还不简单,一个for循环搞定。但批量下载,是之前研究这个项目的朋友们卡住最多的地方。因为for不难,难的是你要循环啥东西:所有文章列表在哪里?
打开电脑版微信,找到一个公众号的历史文章列表页。

在文章列表中下滑鼠标,会看到有文章列表不停加载出来。我们要想办法把这些列表提取出来。
直接看下图,正常状态下,电脑版微信发送请求给微信服务器,微信服务器返回数据给电脑,再显示出来。
我们可以在两者之前插入一个代理,即图中所示的Fiddler软件,这样它可以抓取到微信服务器返回的信息。

需要的工具叫 Fiddler ,它的官网有时会打不开,可以去pc.qq.com搜索Fiddler4(或者去文末QQ群的共享里下)、下载、安装。然后,想让Fiddler正常工作需要进行些配置,可以先照我说的做。建议先把本文全看完了再实际操作。
提醒一下,Fiddler其实是一个系统代理软件,所以如果你的电脑上正在使用其他类型的代理软件请先关掉,否则可能无法正常工作。
打开Fiddler,按下图操作。

会弹出几个窗口,都点 Yes

最后是这样的,打了3个钩。点OK保存即可。

配置完成了,然后点软件左下角的方块,会显示 Capturing ,表示它此时处在可以抓取数据的状态,再点一下,恢复空白,表示暂停抓取。

然后,在微信公众号的历史文章列表页往下划动,会看到Fiddler的左侧窗口有一堆数据在滚动,跟第一节中讲到的chrome开发者工具很像,其实这两个的功能基本一致,只不过开发者工具只能检测到在chrome中打开的网页,而Fiddler可以检测到整个电脑中所有的Http和Https请求(这两种方式主要是抓网页类型数据,其实电脑中还有其他类型的网络请求方式,比如微信聊天数据用这种方式就抓取不到,另外网页版的支付宝、网银支付都用了更高级的加密技术,不用担心。)
点击某一行,右边会出现这一条请求的详细情况,与chrome开发者工具风格很像,Fiddler的功能更多更强大。
多下拉几次,多加载一些文章,你就会发现规律:
每次当出现新文章,都会出现一条下图红框所示url的请求。

选中这一条,在右侧选择 JSON ,会看到一条格式化的 JSON 数据,仔细看general_msg_list,貌似就是返回的文章列表,为了确定一下,可以再点 JSON 左边的 Raw 标签,看最后一行,是一串很长的json字符串,就是它了。
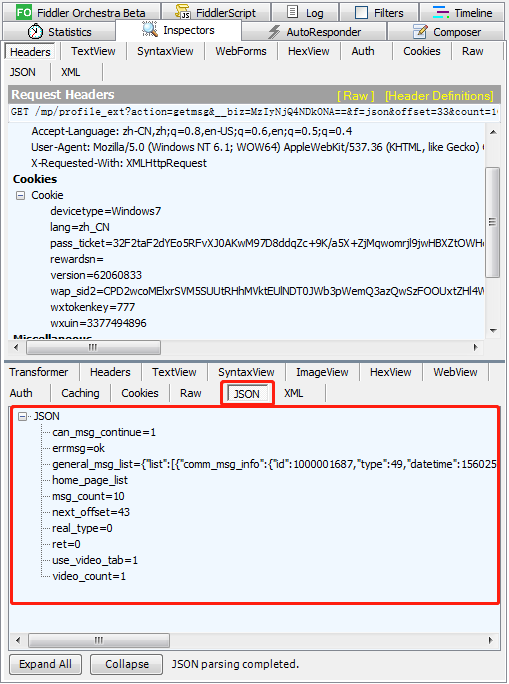
如果把每一条请求的返回字符串全都搜集起来,便得到了所有文章的列表。而Fiddler的给力之处正在于它可以帮我们把所抓到的消息都以文本的形式保存下来。
那么,如果一个公众号有1000篇文章,要发多少次请求,下拉多少次才能把所有文章都列出来呢?只要你别太笨,应该至少能想到一个笨方法:不停往下拉文章列表,Fiddler便会抓取到所有的返回数据。本着先求有再求好,从简单到抽象的原则,我们就先这么抓,其实,在我刚开始批量采集的最初一段时间就是这么采集文章列表的,当然除了简单易上手还有些其他方面的考虑。
在正式开始抓取之前,我们要先做点准备工作:Fiddler默认会把所有的经过本电脑的请求全都抓出来了,没必要全保存,最好能筛选一下。那我们需要的数据有什么特征呢?仔细看一下,我们所关注的数据的网址的前半部分都是
开头的,那我们就让Fiddler只保留这样的网址。
讲到这里,可能许多有点经验的朋友觉得我该介绍在Fiddler中写代码了,但是,我们不需要!让对python还似懂非懂的朋友再去学JScript语言有点压力山大,我们可以巧妙得利用Fiddler自身强大的筛选功能来搞定此事:
看下图,在Fiddler的右侧,开启过滤功能,只显示url中带有指定关键字的请求,注意前面不要带https,填写完之后会自动保存。

再去下滑微信文章列表,Fiddler中就只显示我们想要的网址了。

接下来,看看怎么把上面列出来的这些内容全都保存到电脑上。
先在本地新建一个C:\vWeChatFiles\rawlist文件夹。
依次点Fiddler左上角的 File - Export Sessions - All Sessions,弹出一个对话框,选择 Raw Files , 点Next,又是一个对话框,保存目录设为我们刚才新建的文件夹。


最后点Export ,软件会自动帮我们新建一个类似于C:\vWeChatFiles\rawlist\Dump-0805-15-00-45这样的文件夹,其中有几个json文件,如果你用记事本或者notepad++(强烈建议用后者)打开这些文件,就会看到这是标准的json格式,而Python中有现成的解析json的库。
写代码之前先看看这些json格式的内容中都有什么,限于篇幅原因在此只提示大家利用好fiddler的json查看工具 + bejson.com 这个网站,或者直接参照下面的2张图。

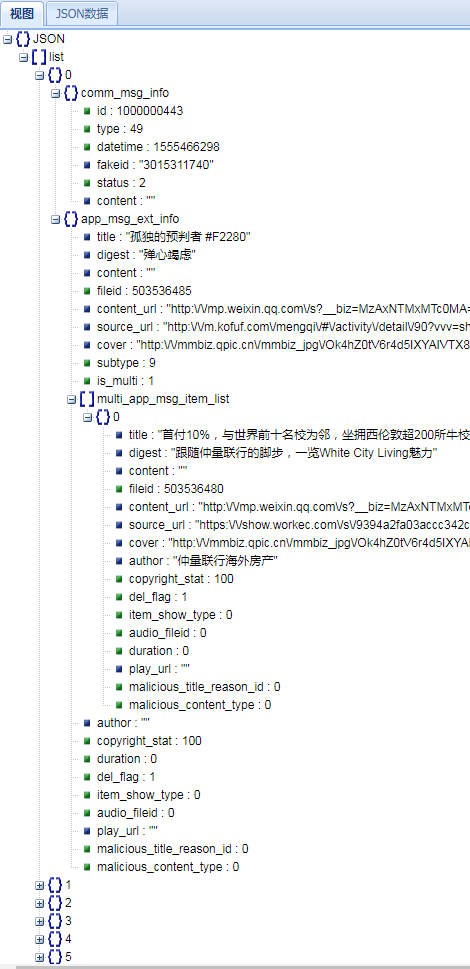
解析出了文章列表,再结合第2篇中讲到的下载单篇文章的源代码稍加改造便可搞定,整个项目的源代码160行,难度不大。
最后,你可能还在想,究竟要怎么拿到微信文章列表?要怎么自动下滑?你可能需要一个按键精灵,或者自己用python写段小代码,但这2个方案貌似都有点上手难度,不妨把这个作为考验大家智慧的小作业。因为,至少,您可以手动多点几下搞定,还因为,这种方式只是一个过渡方式。
以上,就完成了整个批量下载文章的主流程。但这样做有至少3个明显的缺点:
需要手工翻文章列表页,且不能翻页太快,否则容易被微信限制。
列表中不包含最近的文章,因为最近文章不是以上文所述的网址形式出现的。
每下载一个新号,都要手动修改py文件中的保存目录。
当然这些缺点都有解决办法,想把html转成pdf和word也不是啥难事,至于要不要在后面的文章写出来取决于本文是否达到了我的预期热度。
但至少,看到这里的你,完全可以自主去保存想要的东西了,行动起来吧!
本文会同步在多个平台,由于公众号等平台发文后不可修改,所以勘误和难点解释请注意查看文后留言,也可以点击"阅读原文"查看我的个人博客版。
本文的源代码可通过公众号 不止技术流 后台回复“源码”自动获得(不是在本文下方留言)。
源码亦放在github上 https://github.com/LeLe86/vWeChatCrawl
说明:技术交流的乐趣在于各有付出各有收获共同进步。请不要私信要求我把之前做好的成品软件的所有源代码都公开出来,我不会便宜那些贼坏的伸手党们。有额外商用定制化需求的私聊 kakaLongcn