1. 集群结构
在我们探究ES的分布式架构之前,我们使用一个简单的导图描述一下我们在设计分布式系统时会考虑的问题,如图1所示。
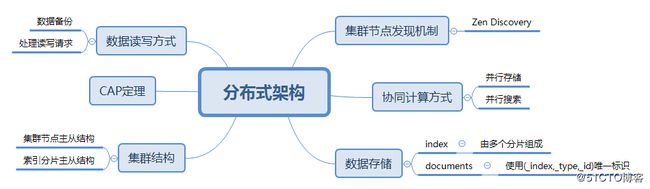
带着图1中的问题我们来探究一下ES集群,ES集群是一个典型的主从结构,从某种意义上来说,符合现今大多数主流分布式存储、分布式计算系统的审美要求。下面我们逐步来了解集群中的这些东东。
先用来自文献2的一张集群结构图开始我们的探究。

1.1 集群节点
在ES集群中,一个ES实例就是一个节点(node),图2中显示的是三个节点的一个集群。集群中有一个主节点(master)。
主节点负责整个集群范围的轻量级操作,如创建或删除索引、跟踪哪些节点是集群的一部分以及决定将哪些分片分配给哪些节点。对于集群健康而言,拥有一个稳定的主节点非常重要。
可以在集群的任何一个节点上使用如下命令获取集群中的节点信息:
curl -iXGET 'localhost:9200/_cat/nodes?v'
返回结果的示例如下:
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.127.100 40 94 0 0.01 0.07 0.06 mdi * node-es100
默认情况下,集群中的每个节点都可以处理HTTP和传输流量。传输层专门用于节点和外部客户端之间的通信HTTP层仅由外部REST客户端使用。所有节点都知道集群中的所有其他节点,并可以将客户机请求转发到适当的节点。
根据节点的用途可分为以下几类:
- Master-eligible node: 可成为主节点的候选节点,任何主节点的候选节点(默认情况下是所有节点)都可以通过主选择过程被选为主节点。
- Data node:数据节点保存包含已索引的文档的分片。数据节点处理与数据相关的操作,如CRUD、搜索和聚合。这些操作是I/O、内存和cpu密集型的。监视这些资源并在它们过载时添加更多的数据节点以扩展容量。拥有专用数据节点的主要好处是控制面和数据面的分离。
- Ingest node:Ingest节点可以执行由一个或多个Ingest处理器组成的预处理管道。根据ingest处理器执行的操作类型和所需的资源,设置专门执行特定任务的ingest节点是有意义的。
- Tribe node:使用tribe.*配置的tribe节点,是一种特殊类型的用于协调的节点,它可以连接到多个集群,并跨所有连接的集群执行搜索和其他操作。
默认情况下,每个节点都是是候选主节点和数据节点,并且它可以通过Ingest管道对文档进行预处理。但是随着集群的增长,可考虑将符合主控条件的专用节点与专用数据节点分离。
如果去掉处理主控、数据保存和文档预处理的能力,那么节点就只剩下一个协调功能,只能路由请求、处理请求。从本质上讲,只有协调节点才能充当智能负载平衡器。
不同类型的节点可用一组属性来确定,如下表所示:
| 节点类型 | 属性定义 |
|---|---|
| Master-eligible node | node.master: true,node.data: false,node.ingest: false,cluster.remote.connect: false |
| Data node | node.master: false,node.data: true,node.ingest: false,cluster.remote.connect: false |
| Ingest node | node.master: false,node.data: false,node.ingest: true,cluster.remote.connect: false |
| Coordinating only node | node.master: false,node.data: false,node.ingest: false,cluster.remote.connect: false |
1.2. 发现机制
ES集群中的发现模块负责发现集群中的节点,以及选择主节点。
Elasticsearch是一个基于点对点的网络系统,节点之间可以直接通信。所有的主要api(index, delete, search)都不与主节点通信。主节点的职责是维护全局集群状态,并在节点动态改变时重新分配分片。集群状态的变更会被通知到集群中的其他节点。
ES集群支持Azure Classic Discovery、EC2 Discovery、Google Compute Engine Discovery三种外部发现机制,通过对应的插件来实施。
ES内置的发现机制为Zen Discovery机制,提供了多播和单播两种发现方式。
Ping是一个ES节点使用发现机制发现其它节点的进程,一个集群中的节点应该配置相同的集群名称。使用ping进程,多播发现的方式通过向其他节点发送一个或多个多播请求来实现,单播方式下,需要提供一个主机列表(称为Seed nodes)作为路由列表。
一个elasticsearch.yml文件中配置集群的示例如下:
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: zkes_cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-es100
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: ["192.168.127.100", "192.168.127.101"]
单播发现依赖transport模块实现。注意port默认应该是9300,不是9200,因为使用的是tranposrt。
1.3. 选举机制
主节点通过同一集群中的候选主节点集合选举产生,每个候选主节点读取自己获得的候选主节点列表,并选举该列表按节点ID排序后的第一个节点作为主节点。
ES中需要定义参与选举的候选主节点的最小数目(quorum)。ES认为quorum应符合下面的要求:
quorum = (number of master-eligible nodes / 2) + 1
例如:集群中有10个节点,都是候选主节点,则quorum应设置为6,以保证在选举主节点时至少有6个候选主节点参与。这样设置的目的是防止集群中出现脑裂现象,即集群中出现两个或以上的主节点。
集群中的节点时可以动态变化,因此可在集群中通过discovery.zen.minimum_master_nodes参数即时更新quorum,示例如下:
PUT /_cluster/settings
{
"persistent" : {
"discovery.zen.minimum_master_nodes" : 2
}
}
当主节点停止或遇到问题时,集群节点将再次发出ping,并选择一个新的主节点。
2. 数据模型
2.1. Index与document
应用程序中的对象很少仅仅是键和值的简单列表。通常,它们是复杂的数据结构,可能包含日期、地理位置、其他对象或值数组。
ES可以存储整个对象(或称为文档(document),以下统称为文档,使用JSON进行对象的序列化,一类文档的集合被称为索引(index))。它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在ES中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
ES中,一个集群可以包含多个索引,一个索引可以包含多个文档。如果与RDBMS做比较,则ES中的集群就相当于一个关系数据库,而一个索引就相当于一张关系表(6.0版本后已经忽略了type的概念),而一个文档就相当于表中的一条记录。
一个文档不只有数据。它还包含了元数据(metadata)—关于文档的信息,一个查询处理的对象的示例如下,它包含了所属的索引,类型,以及文档ID:
{
"_index" : "blogs",
"_type" : "articles",
"_id" : "001",
"_score" : 1.0,
"_source" : {
"author" : "zhangkai",
"article_title" : "车梦想家1",
"create_date" : "20190104",
"star" : 6
}
}
2.2. 分片(shard)
一个索引中包含多个文档,在存储策略上,ES将索引分为多个分片(shard), 每个分片存储不同的文档。
一个索引的分片数目可以在创建索引时设置,在设置完毕后就不可更改了,因为索引的分片数据涉及到文档在分配到哪个分片上。
ES定义文档到分片的分配公式为:
shard = hash(routing) % number_of_primary_shards
这里的routing 值是一个任意字符串,它默认是 _id 但也可以自定义。这个 routing 字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是 0 到 number_of_primary_shards - 1 ,这个数字就是特定文档所在的分片。
分片也有主从之分,还记得图2的集群架构吗?这个集群中某个索引有3个分片,每个主分片有两个复制分片用于数据复制。
一个主分片带几个复制分片可通过在创建索引时设置,设置的命令格式示例如下:
{
"settings":{
"number_of_shards":3,
"number_of_replicas":2
}
}
3. 数据读写
3.1. 读写过程
集群中每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。这类接受请求并协调的节点称为协调节点(coordinating node)。如搜索请求分两个阶段执行,由接收客户机请求的节点协调: 在分散阶段,协调节点将请求转发给保存数据的数据节点。每个数据节点在本地执行请求,并将其结果返回给协调节点。在收集阶段,协调节点将每个数据节点的结果缩减为单个全局结果集。
因此在发送请求时,最好对集群中的所有节点进行轮询,以分散负载。
对于写数据操作,必须在主分片上成功完成才能复制到相关的复制分片上。
仍使用文献2中的图来介绍这一过程:
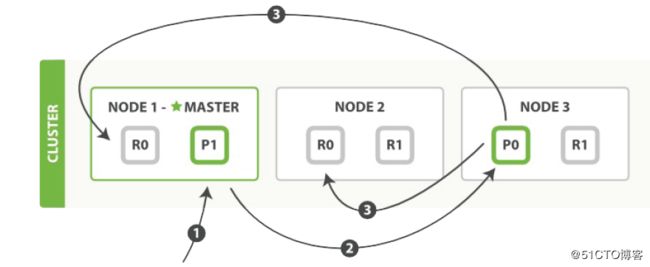
上图中的写过程描述如下:
1. 客户端向node1发送写操作请求(如CUD一个文档)。
2. Node1根据文档的路由标识(如_id)确定该文档应写到P0分片上,于是向node3发送请求。
3. node3上的P0处理请求,写完毕后,将写入数据复制到node1和node2上的RO,完成数据复制。
ES的写操作可分为同步(默认方式)与异步两种方式:在同步方式下,客户端要等到数据在所有分片上复制完成后才能收到请求回应;在异步方式下,客户端只要在主分片上完成写操作后就能够得到请求回应。
对于读数据操作,可从主分片和任一复制分片读取。
仍使用文献2中的图来介绍这一过程:
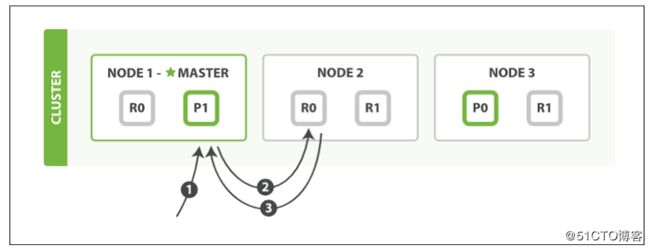
上图中的写过程描述如下:
1. 客户端向node1发送读操作请求(如R一个文档)。
2. Node1根据文档的路由标识(如_id)确定该文档存放在分片0上,这时node1,node2,node3上都有分片0,node1通过自己的负载均衡算法(一般使用循环轮转算法)确定本次由node2处理请求,并将读操作请求发送到node2。
3. Node2上的R0处理读请求完毕后,将结果返回给node1,node1再返回给客户端。
3.2. 如何将数据写到同一个分片
ES在某些应用场景下要求不同文档保存在同一分片中(如映射为父子关系的文档),而为了搜索效率将语义强相关的文档放到同一分片中也很有必要。
还记得前面我们讲过一个文档保存到哪个分片是由它的routing值提供的,那么在写入文档时ES允许设置routing值(读数据时也可设置,这样ES只在指定的分片上检索,可以提高效率),写入不同文档时设置为相同的routing值就可保证这些文档保存在同一分片上。
如下面的命令:
curl -iXPOST 'localhost:9200/bank/account/1000?routing=Dillard&pretty' -H 'Content-Type: application/json' -d'
{"firstname":"Dillard"}
'
这里的routing为字符串形式,可以取个好记的名字。
3.3. 数据访问中的临界区问题
数据访问中我们常常会遇到数据临界区问题。如一个电商应用中,对于销售量变量,一次交易首先会从数据库中读出当前销售量,然后将当前销售量加上交易中的交易数目,然后写到数据库中销售量变量中。如果多个客户端同时交易,交易时不锁定包含销售量变量的临界区,就发发生冲突,导致销售量没有正确统计。
ES中对于临界区问题的处理本身并没有提供所谓的锁定机制(悲观并发控制,Pessimistic concurrency control),需要由调用的客户端自行解决,解决方法的依据就是使用文档的版本号(_version)。
ES中每个文档都有一个 _version,这个_version在文档被改变时加1,创始创建时也为1。
查看如下修改后的操作结果:
{
"_index" : "bank",
"_type" : "account",
"_id" : "_doc",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 198,
"_primary_term" : 3
}
为避免出现临界区问题,在修改一个文档时,首先查询出该文档的_version,然后再修改请求中携带该_version,如下示例所示:
curl -iXPOST 'localhost:9200/bank/account/1000? version=1' -H 'Content-Type: application/json' -d'
{"firstname":"Dillard"}
ES如果发现当前该文档的_version已经大于1(其它客户端已经修改了该文档),则会回应该修改请求失败。客户端可再次读取当前文档的_version实施修改。
这种处理方式被称为乐观并发控制(Optimistic concurrency control)。
4. 关于CAP的思考
CAP定理指的是分布式系统中Consistency(一致性)。 Availability(可用性)。Partition tolerance(分区容错性)这三个特性最多只能实现两个。
三个特性的定义如下:
- 一致性(Consistency):每次读操作都能保证返回的是最新数据(all nodes see the same data at the same time);
- 可用性(Availablity):任何一个没有发生故障的节点,会在合理的时间内返回一个正常的结果(Reads and writes always succeed);
- 分区容忍性(Partition-torlerance):当节点间出现网络分区,照样可以提供服务(网络故障时,系统仍可用)。
考虑ES的集群,当出现网络分区(网络出现了故障,集群中的节点之间不可互相通讯了)时,只要某个分区中的候选主节点大于等于quorum(因为避免脑裂,其它分区不会满足quorum),则该分区可用,满足了P。
回忆3.1节中提到的同步写过程,如果因为网络故障使得更新数据没有复制到所有复制分片上,则请求节点会返回写失败,这种情况下为了满足C而不满足A。在异步写的方式(尽管不推荐)下,虽可以满足A,但牺牲了C。
从这里延伸开去,我们看一下BASE理论。BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的简写: - Basically Available:基本可用性,是指分布式系统在出现不可预知故障的时候,允许损失部分可用性(如损失响应时间和部分服务);
- Soft-state:软状态,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
- Eventual Consistency:最终一致性,允许数据最终一致性,而不是实时一致(强一致性)。
BASE是对CAP中一致性和可用性权衡的结果,基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
在ES中,数据复制使用consistency这个属性来定义需要复制的分片数目,consistency 允许的值为 one (只有一个主分片), all (所有主分片和复制分片)或者默认的 quorum 或过半分片。可以推算出,当读和写涉及的分片数目越多时,越接近强一致性。ES中,当网络分区恢复(网络故障解除)或新增节点,ES的节点间可实现数据间的同步,达到最终一致性。
5. 参考文献
- https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
- Clinton Gormley &Zachary Tong, Elasticsearch: The Definitive Guide,2015
- https://blog.csdn.net/lavorange/article/details/52489998
本系列文章:
编程随笔-ElasticSearch知识导图(1):全景
编程随笔-ElasticSearch知识导图(2):分布式架构
编程随笔-ElasticSearch知识导图(3):映射
编程随笔-ElasticSearch知识导图(4):搜索
编程随笔-ElasticSearch知识导图(5):聚合
编程随笔-ElasticSearch知识导图(6):管理