岭回归和LASSO
排除多重共线性和变量选择,是回归中重要的两个问题,排除共线性归根到底是变量选择的问题。筛选出重要的变量,是一个数据挖掘问题。
回归问题的数学解释:

得到β的前提是矩阵X‘X可逆(此时为无偏估计),但在实际应用中,可能会导致自变量个数多于样本量(p>n即列数比行数多)或者自变量间存在多重共线性(例如第三列是第二列的两倍)时,计算出来的 |X’X| =0,不可逆,导致偏回归系数无解,此时需要引入扩展的回归模型:岭回归和LASSO。
一、岭回归
通过在线性回归模型的目标函数上添加一个l2的正则项,即惩罚项为回归系数β的平方和,求解目标函数的最小值可得:


虽然最小二乘估计量在所有线性无偏估计量中是方差最小的,但是这个方差却不一定小。而实际上可以找一个有偏估计量,这个估计量虽然有微小的偏差,但它的精度却能够大大高于无偏的估计量。岭回归分析就是依据这个原理,通过在正规方程中引入有偏常数而求得回归估计量的。
随着λ的增大,模型方差减少,回归系数被压缩,偏差(残差平方和)增大。通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际。




岭迹图此时为喇叭形,存在多重共线性
二、岭回归应用
以糖尿病数据为例,自变量为患者的信息,因变量为糖尿病指数,越小说明治疗效果最好。
关键点是找一个合理的λ,来衡量模型的偏差和方差,进而得到更加符合实际的领回归系数。
# 导入第三方模块
import pandas as pd
import numpy as np
from sklearn import model_selection
from sklearn.linear_model import Ridge,RidgeCV
import matplotlib.pyplot as plt
# 读取糖尿病数据集
diabetes = pd.read_excel(r'F:\diabetes.xlsx', sep = '')
diabetes.head()
因为性别和年龄对于治疗效果无显著影响,去除
# 构造自变量(剔除患者性别、年龄和因变量)
predictors = diabetes.columns[2:-1]
predictors
依次为体质指数,平均血压,以及6个血清测量值
拆分数据
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = model_selection.train_test_split(diabetes[predictors], diabetes['Y'],
test_size = 0.2, random_state = 1234 )
CASE1:通过可视化方法确定λ,当回归系数随着λ的增加趋于稳定
# 构造不同的Lambda值
Lambdas = np.logspace(-5, 2, 200)
Lambdas

。。。
上面的logspace函数:
np.logspace(0,3,10)
生成100—-103为断点元素个数为10的等比数列
# 构造空列表,用于存储模型的偏回归系数
ridge_cofficients = []
# 循环迭代不同的Lambda值
for Lambda in Lambdas:
ridge = Ridge(alpha = Lambda, normalize=True)
ridge.fit(X_train, y_train)
ridge_cofficients.append(ridge.coef_)
# 绘制Lambda与回归系数的关系
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置绘图风格
plt.style.use('ggplot')
plt.plot(Lambdas, ridge_cofficients)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Lambda')
plt.ylabel('Cofficients')
# 图形显示
plt.show()
normalize=True即建模时是否需要对数据集进行标准化处理

对于比较突出的喇叭形折线,代表该变量存在多重共线性。
λ增大,各回归系数迅速缩减至0,当λ=0.01时,回归系数趋于稳定。
CASE2:通过交叉验证法确定λ,当回归系数随着λ的增加趋于稳定
# 岭回归模型的交叉验证
# 设置交叉验证的参数,对于每一个Lambda值,都执行10重交叉验证
ridge_cv = RidgeCV(alphas = Lambdas, normalize=True, scoring='neg_mean_squared_error', cv = 10)
# 模型拟合
ridge_cv.fit(X_train, y_train)
# 返回最佳的lambda值
ridge_best_Lambda = ridge_cv.alpha_
ridge_best_Lambda
为0.0135,对应最小的平均均方误差 。
预测
预测之后对比差异,评估模型的拟合能力
# 基于最佳的Lambda值建模
ridge = Ridge(alpha = ridge_best_Lambda, normalize=True)
ridge.fit(X_train, y_train)
# 返回岭回归系数
pd.Series(index = ['Intercept'] + X_train.columns.tolist(),data = [ridge.intercept_] + ridge.coef_.tolist())

对岭回归系数的解释同多元线性回归一样
对测试集的数据进行预测
# 导入第三方包中的函数
from sklearn.metrics import mean_squared_error
# 预测
ridge_predict = ridge.predict(X_test)
# 预测效果验证
RMSE = np.sqrt(mean_squared_error(y_test,ridge_predict))
RMSE
值越小,模型对数据的拟合效果越好。
三、LASSO回归
岭回归存在的问题:
计算方法太多,差异太大;
根据岭迹图进行变量筛选,随意性太大;
岭回归返回的模型(如果没有经过变量筛选)会包含所有的变量,无法降低模型的复杂度
通过在线性回归模型的目标函数上添加一个l1的正则项,即惩罚项为回归系数β的绝对值之和,求解目标函数的最小值可得,在缩减过程中,可以将一些不重要的回归系数直接缩减至0
与岭回归一样,是有偏估计
因为惩罚项是绝对值之和,在零点处不可导,无法使用岭回归上的最小二乘法求解拟合系数,梯度下降法、牛顿法、拟牛顿法也无法使用,这里使用坐标轴下降法,是沿着坐标轴的方向去下降,这和梯度下降不同。梯度下降是沿着梯度的负方向下降。不过梯度下降和坐标轴下降的共性就都是迭代法,通过启发式的方式一步步迭代求解函数的最小值。
坐标轴下降法的数学依据主要是这个结论:一个可微的凸函数J(θ), 其中θ是nx1的向量,即有n个维度。如果在某一点θ~,使得J(θ)在每一个坐标轴θ¯i(i = 1,2,...n)上都是最小值,那么J(θ~)就是一个全局的最小值。即每个分量最优则全局最优。
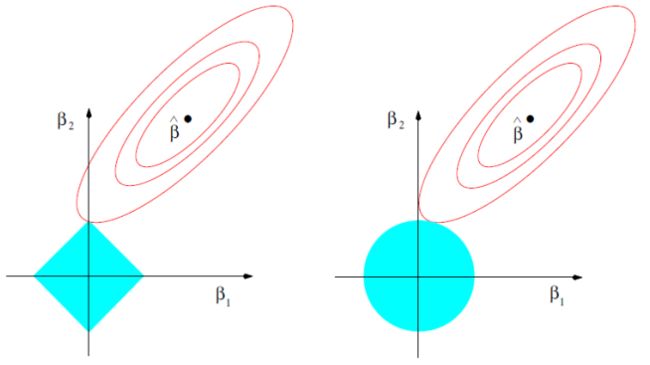
左边为l1的示意图,方框顶点更容易与抛物面相交,会导致β为0,进而实现变量的删除,起到变量筛选的效果。
四、LASSO回归应用
CASE1:通过可视化方法确定λ,当回归系数随着λ的增加趋于稳定
# 导入第三方模块中的函数
from sklearn.linear_model import Lasso,LassoCV
# 构造空列表,用于存储模型的偏回归系数
lasso_cofficients = []
for Lambda in Lambdas:
lasso = Lasso(alpha = Lambda, normalize=True, max_iter=10000)
lasso.fit(X_train, y_train)
lasso_cofficients.append(lasso.coef_)
# 绘制Lambda与回归系数的关系
plt.plot(Lambdas, lasso_cofficients)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Lambda')
plt.ylabel('Cofficients')
# 显示图形
plt.show()
max_iter=10000为最大迭代次数

λ在0.05附近,趋于稳定
CASE2:通过交叉验证法确定λ,当回归系数随着λ的增加趋于稳定
# LASSO回归模型的交叉验证
lasso_cv = LassoCV(alphas = Lambdas, normalize=True, cv = 10, max_iter=10000)
lasso_cv.fit(X_train, y_train)
# 输出最佳的lambda值
lasso_best_alpha = lasso_cv.alpha_
lasso_best_alpha
λ=0.0629
预测
# 基于最佳的lambda值建模
lasso = Lasso(alpha = lasso_best_alpha, normalize=True, max_iter=10000)
lasso.fit(X_train, y_train)
# 返回LASSO回归的系数
pd.Series(index = ['Intercept'] + X_train.columns.tolist(),data = [lasso.intercept_] + lasso.coef_.tolist())

系数中S2和S4系数为0,说明对Y没有显著意义
# 预测
lasso_predict = lasso.predict(X_test)
# 预测效果验证
RMSE = np.sqrt(mean_squared_error(y_test,lasso_predict))
RMSE
RMSE相比于岭回归,下降了0.8,即在降低模型复杂度的情况下(删除了S2和S4),进一步提高了模型的拟合效果
五、多元线性回归应用
为了进一步说明LASSO回归的拟合效果,运用多元线性回归模型
# 导入第三方模块
from statsmodels import api as sms
# 为自变量X添加常数列1,用于拟合截距项
X_train2 = sms.add_constant(X_train)
X_test2 = sms.add_constant(X_test)
# 构建多元线性回归模型
linear = sms.formula.OLS(y_train, X_train2).fit()
# 返回线性回归模型的系数
linear.params

# 模型的预测
linear_predict = linear.predict(X_test2)
# 预测效果验证
RMSE = np.sqrt(mean_squared_error(y_test,linear_predict))
RMSE
多元线性回归的拟合效果最差
批注:弹性网
ElasticNet 是一种使用L1和L2先验作为正则化矩阵的线性回归模型.这种组合用于只有很少的权重非零的稀疏模型,比如:class:Lasso, 但是又能保持:class:Ridge 的正则化属性.我们可以使用 l1_ratio 参数来调节L1和L2的凸组合(一类特殊的线性组合)。
