Apache Ignite提供了一个强大的查询API,支持基于谓词的扫描查询、符合ANSI-99的SQL查询、文本搜索查询和持续查询。
假设缓存包含以下Company对象:
public class Company {
private Long id;
private String companyName;
private String email;
private String address;
private String city;
private String state;
private String zipCode;
private String phoneNumber;
private String faxNumber;
private String webAddress;
}
缓存的company数据记录将被分区并分布在Ignite数据网格中。你可以查询遍历缓存记录,并查找感兴趣的特定记录。但是遍历整个缓存并是低效的,因为必须获取整个数据集并在本地迭代。如果数据集非常大,将会增加网络传输负担。Apache Ignite提供了一个编程接口,允许对缓存数据集执行不同类型的查询。你可以根据应用程序需求选择API,例如,如果你想执行文本搜索,Ignite文本查询是最佳选择。
Apache Ignite提供了查询API的两个主要抽象:Query和QueryCursor接口:
| Name | Description |
|---|---|
| Query | 所有Ignite缓存查询的基类。必须使用SqlQuery和TextQuery进行SQL和文本查询。这个抽象类还提供了setLocal()和setPageSize()等方法来在本地节点中执行查询,并为返回的游标设置页面大小。 |
| QueryCursor | 接口,用翻页迭代表示查询结果。当不需要分页时,可以使用QueryCursor.getAll()方法,它将获取整个查询结果并将其存储在集合中。注意,无论何时在for循环中迭代游标或显式地获取迭代器,都必须显式地关闭游标。 |
Scan queries
Ignite Scan queries允许在缓存数据集上运行分布式查询。如果没有指定谓词,查询返回缓存的所有数据记录。你可以根据存储在缓存中的对象定义任何谓词。
查询将对所有数据记录应用谓词以查找匹配。为了演示扫描查询的功能,我们将使用以下数据集。

where
- ID: Serial Number
- CAT: CAT (公司名称首写字母)
- COMPANY_NAME:公司名称
- EMAIL: 公司或个人使用的email
- ADDRESS:街道地址或地区
- CITY:城市名称
- STATE:州名
- ZIPCODE:邮编
- PHONE_NUMBER:公司或个人联系电话
- FAX_NUMBER:传真
该数据集包含位于纽约州的所有公司联系信息。我们将把CSV文件中的数据记录加载到缓存中,并应用一些谓词扫描查询缓存中的数据记录。
Step 1
使用以下依赖项创建一个新的Maven项目。
4.0.0
com.mycookcode.bigData.ignite
ignite-textquery
jar
1.0-SNAPSHOT
ignite-textquery
http://maven.apache.org
UTF-8
2.6.0
junit
junit
3.8.1
test
org.apache.ignite
ignite-core
${ignite.version}
org.apache.ignite
ignite-indexing
${ignite.version}
org.apache.ignite
ignite-spring
${ignite.version}
org.apache.ignite
ignite-slf4j
${ignite.version}
org.apache.ignite
ignite-log4j
${ignite.version}
org.slf4j
slf4j-api
1.7.25
org.apache.maven.plugins
maven-compiler-plugin
3.3
1.8
1.8
com.jolira
onejar-maven-plugin
1.4.4
build-query
com.mycookcode.bigData.ignite.App
true
onejar
textquery-runnable.jar
one-jar
Step 2
首先,创建一个新的Java类com.mycookcode.bigData.ignite.model.Company在src\main\java\com\mycookcode\bigData\ignite\model目录,它将代表数据集。
package com.mycookcode.bigData.ignite.model;
import org.apache.ignite.cache.query.annotations.QueryTextField;
import java.io.Serializable;
public class Company implements Serializable {
private Long id;
@QueryTextField
private String cat;
@QueryTextField
private String companyName;
@QueryTextField
private String email;
@QueryTextField
private String address;
@QueryTextField
private String city;
@QueryTextField
private String state;
@QueryTextField
private String zipCode;
@QueryTextField
private String phoneNumber;
@QueryTextField
private String faxNumber;
@QueryTextField
private String sicCode;
@QueryTextField
private String sicDescription;
@QueryTextField
private String webAddress;
public Company(Long id, String cat, String companyName, String email, String address, String city, String state, String zipCode, String phoneNumber, String faxNumber, String sicCode, String sicDescription, String webAddress) {
this.id = id;
this.cat = cat;
this.companyName = companyName;
this.email = email;
this.address = address;
this.city = city;
this.state = state;
this.zipCode = zipCode;
this.phoneNumber = phoneNumber;
this.faxNumber = faxNumber;
this.sicCode = sicCode;
this.sicDescription = sicDescription;
this.webAddress = webAddress;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getCat() {
return cat;
}
public void setCat(String cat) {
this.cat = cat;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
}
public String getZipCode() {
return zipCode;
}
public void setZipCode(String zipCode) {
this.zipCode = zipCode;
}
public String getPhoneNumber() {
return phoneNumber;
}
public void setPhoneNumber(String phoneNumber) {
this.phoneNumber = phoneNumber;
}
public String getFaxNumber() {
return faxNumber;
}
public void setFaxNumber(String faxNumber) {
this.faxNumber = faxNumber;
}
public String getSicCode() {
return sicCode;
}
public void setSicCode(String sicCode) {
this.sicCode = sicCode;
}
public String getSicDescription() {
return sicDescription;
}
public void setSicDescription(String sicDescription) {
this.sicDescription = sicDescription;
}
public String getWebAddress() {
return webAddress;
}
public void setWebAddress(String webAddress) {
this.webAddress = webAddress;
}
@Override
public String toString() {
return "Company{" +
"id=" + id +
", cat='" + cat + '\'' +
", companyName='" + companyName + '\'' +
", email='" + email + '\'' +
", address='" + address + '\'' +
", city='" + city + '\'' +
", state='" + state + '\'' +
", zipCode='" + zipCode + '\'' +
", phoneNumber='" + phoneNumber + '\'' +
", faxNumber='" + faxNumber + '\'' +
", sicCode='" + sicCode + '\'' +
", sicDescription='" + sicDescription + '\'' +
", webAddress='" + webAddress + '\'' +
'}';
}
}
Step 3
现在,可以创建另一个Java类并添加一个方法来将数据从CSV文件加载到Ignite缓存中(样例数据下载地址:https://pan.baidu.com/s/1IkAG0BXbn68na0wAHmC0Q)。在文件夹src/main/java/com/mycookcode/bigData/ignite目录中创建一个新的Java类com.mycookcode.bigData.ignite.App。添加一个名为initialize()的方法,代码如下:
private static void initialize()throws InterruptedException,IOException
{
IgniteCache companyCache = Ignition.ignite().cache(COMPANY_CACHE_NAME);
//启动之前清空缓存
companyCache.clear();
try(Stream lines = Files.lines(Paths.get("/data/USA_NY_email_addresses.csv"))
//Stream lines = Files.lines(Paths.get(App.class.getClassLoader().getResources("USA_NY_email_addresses.csv").toString()))
)
{
lines.skip(1).map(s1 -> s1.split("\",\"")).map(s2 -> new Company(Long.valueOf(s2[0].replaceAll("\"", "")), s2[1], s2[2], s2[3], s2[4], s2[5], s2[6], s2[7], s2[8], s2[9], s2[10], s2[11], s2[12].replaceAll("\"", "")))
.forEach(r -> companyCache.put(r.getId(),r));
}catch (IOException e)
{
System.out.println(e.getMessage());
}
Thread.sleep(1000);
}
首先,我们用companyCache创建一个Ignite缓存,它将存储公司的所有数据记录。然后usa_ny_email_address.csv文件做为数据流被Java 8 Stream API读取。接下来,我们跳过第一行CSV文件,按' '分割每一行,并创建新的公司对象存储到Ignite缓存中。上面代码的最后一行强制应用程序等待一秒钟,以确保集群的所有节点都处理put请求。
Step 4
将Ignite Scan查询应用到缓存。在App类中添加一个新的Java方法scanQuery(),如下所示:
{
IgniteCache companyCache = Ignition.ignite().cache(COMPANY_CACHE_NAME);
//查询所有城市“纽约”-纽约的公司
QueryCursor queryCursor = companyCache.query(new ScanQuery((k,p) -> p.getCity().equalsIgnoreCase("NEW YORK")));
for (Iterator ite = queryCursor.iterator();ite.hasNext();)
{
IgniteBiTuple company = (IgniteBiTuple) ite.next();
System.out.println(company.getValue().getCompanyName());
}
queryCursor.close();
}
在上面的伪代码中,我们首先获取公司的Ignite缓存,并使用Java 8 lambda表达式创建一个新的scan查询。我们还传递了以下谓词表达式:
p.getCity().equalsIgnoreCase("NEW YORK")
查询公司对象的城市名称等于纽约的数据。Ignite将对所有缓存数据记录应用上述谓词,并返回该缓存数据记录的QueryCursor,其城市名称等于纽约。然后,我们简单地遍历查询游标并在控制台上打印公司名称。
Step 5
编译和执行应用程序,运行以下命令:
mvn clean install && java –jar target/textquery-runnable.jar scanquery
上图显示了Ignite scan查询找到所有城市名称为New York的公司。
Text queries
Apache Ignite中的文本查询允许对基于字符的缓存项运行全文本查询。为什么需要全文搜索查询,以及它与扫描查询的区别?例如,我们想找到纽约美容院的名单。通过扫描查询,我可以运行以下查询:
TextQuery primavera = new TextQuery<>(Company.class, "beauty saloon");
以上查询将返回公司名称中包含美容院的公司名单。但这种方法也有一些缺点:
- 它将扫描整个缓存,如果缓存包含大量数据集,这将非常低效。
- 如果运行查询,我们不得不需要知道公司对象的属性。在这个例子中,使用的是公司名称。
- 当使用基于不同属性的复杂谓词时,扫描查询将变得复杂。
在日常生活中,我们在网上进行大量的文本搜索:谷歌或Bing。大多数搜索引擎的工作原理是全文搜索。我们在谷歌的搜索框中输入搜索项;谷歌搜索引擎返回包含搜索项的网站或资源的列表。
Apache Ignite支持基于Lucene索引的基于文本的检索查询。Lucene是Java中的开源全文本搜索库,可以很容易地为任何应用程序添加搜索功能。Lucene通过向全文索引添加内容来实现。然后它允许对这个索引执行查询。这种类型的索引称为反向索引,因为它将以page-centric为数据结构(page->words)转换为以keyword-centric为数据结构(word->pages)。你可以把它想象成书后面的索引。
在Lucene中,文档是索引和搜索的单位。索引可以包含一个或多个文档。Lucene文档不一定非得是Microsoft word中的文档。例如,如果您正在创建一个公司的Lucene索引,那么每个公司都将在Lucene索引中表示一个文档。Lucene search可以通过Lucene IndexSearcher从索引中检索文档。

在Apache Ignite中,每个节点都包含一个本地Lucene引擎,它将索引存储在本地缓存中的数据记录。当执行任何分布式全文查询时,每个节点通过IndexSearcher在本地索引中执行搜索,并将结果发送回客户机节点,在那里聚合结果。
我们将使用前面的相同数据集,并扩展应用程序以在Ignite cache中执行文本搜索。先稍微修改一下maven项目,添加全文搜索功能:
Step 1
添加以下maven依赖项如下:
org.apache.ignite
ignite-indexing
2.6.0
Step 2
向com.mycookcode.bigData.ignite.model的每个字段添加@QueryTextField注释。要使用Lucene对Company类进行索引以进行全文搜索。
package com.mycookcode.bigData.ignite.model;
import org.apache.ignite.cache.query.annotations.QueryTextField;
import java.io.Serializable;
public class Company implements Serializable {
private Long id;
@QueryTextField
private String cat;
@QueryTextField
private String companyName;
@QueryTextField
private String email;
@QueryTextField
private String address;
@QueryTextField
private String city;
@QueryTextField
private String state;
@QueryTextField
private String zipCode;
@QueryTextField
private String phoneNumber;
@QueryTextField
private String faxNumber;
@QueryTextField
private String sicCode;
@QueryTextField
private String sicDescription;
@QueryTextField
private String webAddress;
public Company(Long id, String cat, String companyName, String email, String address, String city, String state, String zipCode, String phoneNumber, String faxNumber, String sicCode, String sicDescription, String webAddress) {
this.id = id;
this.cat = cat;
this.companyName = companyName;
this.email = email;
this.address = address;
this.city = city;
this.state = state;
this.zipCode = zipCode;
this.phoneNumber = phoneNumber;
this.faxNumber = faxNumber;
this.sicCode = sicCode;
this.sicDescription = sicDescription;
this.webAddress = webAddress;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getCat() {
return cat;
}
public void setCat(String cat) {
this.cat = cat;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
}
public String getZipCode() {
return zipCode;
}
public void setZipCode(String zipCode) {
this.zipCode = zipCode;
}
public String getPhoneNumber() {
return phoneNumber;
}
public void setPhoneNumber(String phoneNumber) {
this.phoneNumber = phoneNumber;
}
public String getFaxNumber() {
return faxNumber;
}
public void setFaxNumber(String faxNumber) {
this.faxNumber = faxNumber;
}
public String getSicCode() {
return sicCode;
}
public void setSicCode(String sicCode) {
this.sicCode = sicCode;
}
public String getSicDescription() {
return sicDescription;
}
public void setSicDescription(String sicDescription) {
this.sicDescription = sicDescription;
}
public String getWebAddress() {
return webAddress;
}
public void setWebAddress(String webAddress) {
this.webAddress = webAddress;
}
@Override
public String toString() {
return "Company{" +
"id=" + id +
", cat='" + cat + '\'' +
", companyName='" + companyName + '\'' +
", email='" + email + '\'' +
", address='" + address + '\'' +
", city='" + city + '\'' +
", state='" + state + '\'' +
", zipCode='" + zipCode + '\'' +
", phoneNumber='" + phoneNumber + '\'' +
", faxNumber='" + faxNumber + '\'' +
", sicCode='" + sicCode + '\'' +
", sicDescription='" + sicDescription + '\'' +
", webAddress='" + webAddress + '\'' +
'}';
}
}
Step 3
创建一个新的静态方法叫textQuery与以下内容:
private static void textQuery()
{
IgniteCache companyCache = Ignition.ignite().cache(COMPANY_CACHE_NAME);
TextQuery john = new TextQuery<>(Company.class,"John");
TextQuery primavera = new TextQuery<>(Company.class, "beauty saloon");
System.out.println("==So many companies with information about 'John'=="+companyCache.query(john).getAll());
System.out.println("==A company which name with ' beauty salon'=="+companyCache.query(primavera).getAll());
}
上面的代码与scanQuery方法非常相似。首先,我们检索Company缓存,并创建两个文本查询john和beauty saloon。然后使用返回Company列表并将结果打印到控制台的文本执行查询。
Step 4
使用以下命令编译并运行应用程序:
mvn clean install && java –jar target/textquery-runnable.jar textquery
你可以使用不同的搜索条件编辑文本查询应用程序。在正常的用例中,Ignite内置文本查询应该足以执行全文本搜索。
以下是Scan query和Text query完整的代码例子:
Ignite配置文件:/resources/example-ignite.xml
127.0.0.1:47500
Ignite服务启动类com.mycookcode.bigData.ignite.App来完成缓存的查询:
package com.mycookcode.bigData.ignite;
import com.mycookcode.bigData.ignite.model.Company;
import org.apache.ignite.Ignite;
import org.apache.ignite.IgniteCache;
import org.apache.ignite.Ignition;
import org.apache.ignite.cache.CacheMode;
import org.apache.ignite.cache.query.QueryCursor;
import org.apache.ignite.cache.query.ScanQuery;
import org.apache.ignite.cache.query.TextQuery;
import org.apache.ignite.configuration.CacheConfiguration;
import org.apache.ignite.lang.IgniteBiTuple;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Iterator;
import java.util.stream.Stream;
public class App
{
private static final String SCAN_QUERY = "scanquery";
private static final String TEXT_QUERY = "textquery";
//定义用来存储公司对象的分区缓存名称
private static final String COMPANY_CACHE_NAME = App.class.getSimpleName() + "-company";
public static void main( String[] args )throws Exception
{
try (Ignite ignite = Ignition.start("example-ignite.xml"))
{
CacheConfiguration employeeCacheCfg = new CacheConfiguration<>(COMPANY_CACHE_NAME);
employeeCacheCfg.setCacheMode(CacheMode.PARTITIONED);
employeeCacheCfg.setIndexedTypes(Long.class, Company.class);
try(IgniteCache employeeCache = ignite.createCache(employeeCacheCfg))
{
if(args.length <= 0)
{
System.out.println("Usages! java -jar .\\\\target\\\\cache-store-runnable.jar scanquery|textquery");
System.exit(0);
}
initialize();
if(args[0].equalsIgnoreCase(SCAN_QUERY))
{
scanQuery();
System.out.println("Scan query example finished.");
}else if (args[0].equalsIgnoreCase(TEXT_QUERY)) {
textQuery();
System.out.println("Text query example finished.");
}
}
}
}
private static void initialize()throws InterruptedException,IOException
{
IgniteCache companyCache = Ignition.ignite().cache(COMPANY_CACHE_NAME);
//启动之前清空缓存
companyCache.clear();
try(Stream lines = Files.lines(Paths.get("/data/USA_NY_email_addresses.csv"))
//Stream lines = Files.lines(Paths.get(App.class.getClassLoader().getResources("USA_NY_email_addresses.csv").toString()))
)
{
lines.skip(1).map(s1 -> s1.split("\",\"")).map(s2 -> new Company(Long.valueOf(s2[0].replaceAll("\"", "")), s2[1], s2[2], s2[3], s2[4], s2[5], s2[6], s2[7], s2[8], s2[9], s2[10], s2[11], s2[12].replaceAll("\"", "")))
.forEach(r -> companyCache.put(r.getId(),r));
}catch (IOException e)
{
System.out.println(e.getMessage());
}
Thread.sleep(1000);
}
private static void textQuery()
{
IgniteCache companyCache = Ignition.ignite().cache(COMPANY_CACHE_NAME);
TextQuery john = new TextQuery<>(Company.class,"John");
TextQuery primavera = new TextQuery<>(Company.class, "beauty saloon");
System.out.println("==So many companies with information about 'John'=="+companyCache.query(john).getAll());
System.out.println("==A company which name with ' beauty salon'=="+companyCache.query(primavera).getAll());
}
private static void scanQuery()
{
IgniteCache companyCache = Ignition.ignite().cache(COMPANY_CACHE_NAME);
//查询所有城市“纽约”-纽约的公司
QueryCursor queryCursor = companyCache.query(new ScanQuery((k,p) -> p.getCity().equalsIgnoreCase("NEW YORK")));
for (Iterator ite = queryCursor.iterator();ite.hasNext();)
{
IgniteBiTuple company = (IgniteBiTuple) ite.next();
System.out.println(company.getValue().getCompanyName());
}
queryCursor.close();
}
}
SQL queries
Apache Ignite提供了SqlQuery和SqlFieldsQuery API来支持针对缓存的SQL查询。SQL语法是完全支持ANSI-99,可以执行一个聚合函数,比如AVG()、COUNT()、分组或排序。当数据驻留在不同的缓存中时,Apache Ignite还包括用于查询内存数据的分布式SQL连接查询(并置和非并置)。与Hazelcast或Infinispan等内存厂商相比,支持ANSI-99 SQL查询是Apache Ignite的独特特性之一。
过去,针对大型数据集的分布式连接非常具有挑战性,因为在不同表或缓存中查找单个键的开销相对较大。因此,大多数NoSQL或内存缓存供应商不支持查询连接。在这种情况下,用户通过组合多个查询结果手动执行连接查询。然而,Apache Ignite以一种不同的方式解决了连接查询问题。在Ignite 1.7之前版本为了获得可靠的查询结果,只在本地数据上执行查询,数据应该放在同一个节点上。
然而,1.7或更高版本的Apache Ignite版本提供了一种分布式连接查询的新方法,名为非并置分布式连接查询,其中SQL连接查询不再需要数据并置。在交叉连接查询中,数据应该驻留在同一个节点上。否则,可能会得到不准确的查询结果。
缓存以两种方式分布:复制和分区。在复制模式下,所有节点都包含其主数据集和备份副本。在分区模式下,通过Ignite集群复制数据集。当使用Ignite集群的分区拓扑时,所有分布式连接的复杂性都会随之而来。在分区模式中,如果正在执行任何交叉连接查询,Apache Ignite就无法保证获得可靠的查询结果。
Apache Ignite还提供了Java注释,使SQL查询可以访问字段。此外,还可以使用相同的注释对字段进行索引,以便更快地查询。对于复杂的查询,Apache Ignite还提供了一个多字段索引以加速复杂条件下的查询。Apache Ignite还提供了用于SQL投影的Java API。使用SqlFieldsQuery,只能选择指定的字段,而不能选择整个对象。
有了Ignite SQL核心概念,就可以解决大多数SQL问题了。在本小节中主要讨论以下几点:
- 带有注释的投影和索引。
- 查询API。
- 并置,非并置分布式连接查询。
- 性能调优SQL查询。
Dataset
我们将要使用的数据集是来自Postsql数据库的Employee和Department实体。部门(dept)和员工(emp)实体的结构非常简单,它们之间是一对多的关系(见下图)。

Projection and indexing with annotations
首先,为了对缓存数据记录使用SQL查询,必须使实体字段对SQL查询可访问。可以通过以下两种方式实现:
- org.apache.ignite.cache.query.annotations.QuerySqlField
- org.apache.ignite.cache.QueryEntity
接下来的伪代码将显示@QuerySqlField注释的使用。
public class Employee implements Serializable {
private static final AtomicInteger GENERATED_ID = new AtomicInteger(); @QuerySqlField
private Integer empno;
@QuerySqlField
private String ename;
@QueryTextField
private LocalDate hiredate;
private Integer sal;
@QuerySqlField
private Integer deptno;
// rest of the code is omitted
}
让我们详细看看上面的代码。通过使用@QuerySqlField注释,我们已经允许SQL查询使用empno、ename、hiredate和sal属性。注意,SQL查询不启用属性或字段sal。每个实体都有两个预定义的字段:_key和_val,它们表示到整个键的链接和缓存数据记录的值。当数据记录很简单并且想过滤它的数值时,这样做是很有用的。例如执行一条查询语句:
SELECT * FROM Employee WHERE _key = 100
假设在Ignite中有以下缓存。
IgniteCache myCache = Ignition.ignite().cache(CACHE_NAME);
还可以执行Select * from myCache _key=101这样的查询。
现在,通过我们的Employee实体,我们可以执行以下任何一个SQL查询。
select e.ename ,e.sal, m.ename, m.sal from Employee e, (select ename, empno, sal from Empl\
oyee) m where e.mgr = m.empno and e.sal > m.sal
如果希望执行一些查询,在控制台中运行以下命令。
mvn clean install && java –jar ./target/sql-query-employees-runnable.jar
还可以使用@QuerySqlField注释对字段值进行索引,以加速查询执行速度。要创建单个列索引,可以使用@QuerySqlField(index = true)注释字段。将为实体字段创建索引值。让我们看一个例子,如下:
public class Employee implements Serializable {
private static final AtomicInteger GENERATED_ID = new AtomicInteger(); @QuerySqlField(index = true)
private Integer empno;
@QuerySqlField
private String ename;
@QueryTextField
private String job;
@QuerySqlField
private Integer mgr;
@QuerySqlField
private LocalDate hiredate;
@QuerySqlField
private Integer sal;
@QuerySqlField(index = true)
private Integer deptno;
// rest of the code is ommitted
}
在上述代码片段中,我们为字段empno和deptno创建了索引。
还可以将一组中的一个或多个索引组合在一起,以使用复杂条件加速查询执行速度。在这种情况下,必须使用@QuerySqlField.Group注释 。可以放置多个@QuerySqlField。如果希望字段参与多个组索引,可以将注释分组到orderedGroups。
public class Employee implements Serializable {
@QuerySqlField(orderedGroups={@QuerySqlField.Group(
name = "hiredate_salary_idx", order = 0, descending = true)})
private LocalDate hireDate;
@QuerySqlField(index = true, orderedGroups={@QuerySqlField.Group(
name = " hiredate _salary_idx", order = 3)})
private Integer sal;
}
使用上述配置,可以像这样执行SQL查询
select e.ename ,e.sal, m.ename, m.sal from Employee e, (select ename, empno, sal from Empl\
oyee) m where e.mgr = m.empno and (e.sal > m.sal and e.hiredate >=’DATE_TIME’);
Query API
Apache Ignite提供了两个不同的查询API来对缓存数据记录执行SQL查询。
- org.apache.ignite.cache.query.SqlQuery:该类总是返回整个键和对象的值。它与Hibernate HQL非常相似。例如,可以运行下面的查询来获得所有雇员的工资在1000到2000之间的数据。
SqlQuery qry = new SqlQuery<>(Employee.class, "sal > 1000 and sal <= 2000");
- org.apache.ignite.cache.query.SqlFieldsQuery:该查询可以基于SQL select子句返回特定的数据字段。可以选择只选择特定的字段,以最小化网络和序列化开销。对于要执行一些聚合查询时,也是非常有用的。例如:
SqlFieldsQuery qry = new SqlFieldsQuery(,"select avg(e.sal), d.dname " +,"from Employee e, \"" + DEPARTMENT_CACHE_NAME + "\".Department d " +,"where e.deptno = d.deptno " +,"group by d.dname " +,"having avg(e.sal) > ?");
Collocated distributed Joins(并置分布式连接查询)
到目前为止,我们讨论了Apache Ignite的缓存拓扑。让我们深入探讨另一个重要的主题:数据并置。在分区模式下,数据集将被分区并位于不同的Ignite节点中。这意味着与指定Department相关的Employee可以位于不同的节点,反之亦然。在运行时,如果我们想要执行任何业务逻辑,我们需要找出与他们Department相关的Employee将非常耗时。为了解决这个问题,Apache Ignite提供了affinity key概念,其中相关数据集可以位于同一个节点上。例如,通过Employee id和Department id的affinity键AffinityKey(int empNo, int deptNo), Ignite将确保所有Employee的数据与他们的Department数据驻留在同一个节点上。在一个下面的示例中解释所有细节。
Step 1
将Department Java类添加到项目中,如下所示:
public class Department implements Serializable {
private static final AtomicInteger GENERATED_ID = new AtomicInteger();
@QuerySqlField(index = true)
private Integer deptno;
@QuerySqlField
private String dname;
@QuerySqlField
private String loc;
public Department(String dname, String loc) {
this.deptno = GENERATED_ID.incrementAndGet();
this.dname = dname;
this.loc = loc;
}
// setter and getter are omitted here
}
在上面的Java类中,deptno是Department ID,该值将用作缓存中的缓存键。我们还将为Department entity提供一个单独的缓存。我们可以初始化一个Department的缓存,并将Department实体存储如下:
IgniteCache deptCache = Ignition.ignite().cache(DEPARTMENT_CACHE_NAME);
// 创建Department实例
Department dept1 = new Department("Accounting", "New York");
deptCache.put(dept1.getDeptno(), dept1);
还要注意,键值将在SQL执行时用作主键。
接下来,为Employee实体添加另一个Java类,如下所示:
public class Employee implements Serializable {
private static final AtomicInteger GENERATED_ID = new AtomicInteger();
@QuerySqlField(index = true)
private Integer empno;
@QuerySqlField
private String ename;
@QueryTextField
private String job;
@QuerySqlField
private Integer mgr;
@QuerySqlField
private LocalDate hiredate;
@QuerySqlField
private Integer sal;
@QuerySqlField(index = true)
private Integer deptno;
private transient EmployeeKey key; //Affinity employee key
public EmployeeKey getKey()
{
if (key == null)
{
key = new EmployeeKey(empno, deptno);
}
return key;
}
}
除了字段deptno和key之外,大部分都与Department类非常相似。字段deptno识别Employee所在的部门,带有EmployeeKey类型的字段键为AffinityKey。让我们仔细看看它的定义。
public class EmployeeKey implements Serializable {
private final int empNo;
@AffinityKeyMapped
private final int deptNo;
public EmployeeKey(int empNo, int deptNo)
{
this.empNo = empNo;
this.deptNo = deptNo;
}
}
与empno不同,key(类型EmployeeKey)将是缓存键。EmployeeKey类是映射到Employee id和Department id的键,Department id (deptno)将是Employee的关联键。下面的代码将用于在缓存中添加Employee。
IgniteCache employeeCache = Ignition.ignite().cache(EMPLOYEE_CACHE_NAME);
// Employees
Employee emp1 = new Employee("King", dept1, "President", null, localDateOf("17-11-1981"), 5000);
// 注意,我们为Employee对象使用自定义关联键
// 确保所有Employee都与所在的Department分配到相同的节点上。
employeeCache.put(emp1.getKey(), emp1);
因此,Employee King将与Department Accounting位于同一个节点上。现在,如果我们从SqlQueryEmployees类执行sqlFieldsQueryWithJoin方法,应该运行以下SQL查询:
select e.ename, d.dname from Employee e, departments.Department d where e.deptno = d.deptno;
还可以从命令行运行SqlQueryEmployees类,如下所示:
java –jar ./target/sql-query-employees-runnable.jar
该方法的输出如下:

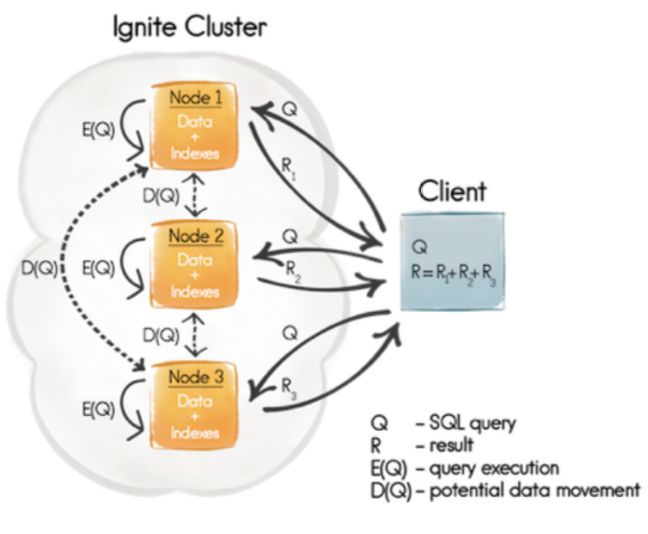
以上SQL查询返回属于其Department的所有Employee。下面的流程图将解释在执行SQL时的工作过程。

根据上图详细的执行流程如下:
- PhaseQ:Ignite客户端节点初始化SQL查询并将SQL查询发送到所有节点。
- Phase E(Q):接收SQL查询的所有Ignite节点都对本地数据运行查询。到目前为止,我们使用的是关联键,本地数据将包含Employee及其所在Department。
- Phase R1-3:所有节点都将它们的执行结果集发送到Ignite客户端节点。
- PhaseR:Ignite客户端节点将以reducer的形式出现,并将所有结果集中在一个结果集中。在我们的示例中,它将把结果打印到控制台。
注意,在常规SQL中,缓存的名称充当模式名称。这意味着所有缓存都可以通过引号中的缓存名称引用。在上面的SQL查询中,Employee是默认的schema名,我们显式地为Department定义缓存名。
Non-collocated distributed joins(非并置分布式连接查询)
在现实中,不可能总是将所有数据放在同一个节点中。大多数情况下,当您通过一个特别的查询对热门数据进行分析时。在这种情况下,从版本1.7.0或更高版本开始,您可以在非配置缓存上使用非并置的分布式连接。通过设置sqlquery.setDistributedJoins (true)参数,可以为指定的查询启用非并置SQL连接。当启用此参数时,查询映射到的节点将通过发送广播请求或单播请求,从远程节点请求本地没有缓存的数据。执行流程如下图所示。
使用这种方法,我们可以使用Employee的empno字段作为缓存键,而不是use - eeKey(empno, deptno)关联键。因此,我们应该对代码进行如下修改:
// Employees
Employee emp1 = new Employee("King", dept1, "President", null, localDateOf("17-11-1981"), 5000);
employeeCache.put(emp1.getEmpno(), emp1);
现在我们可以执行以下查询:
select e.ename, d.dname from Employee e, departments.Department d where e.deptno = d.deptno
即使经过以上的修改,我们仍然会得到一个完整的结果,不管Employee已经不再与其Department数据进行并置。在这种情况下,广播请求将从节点发送到所有其他节点。如果你想使用单播请求,我们必须稍微改变我们的SQL查询如下:
select e.ename, d.dname from Employee e, departments.Department d where e.deptno = d._key
注意,我们在SQL连接中使用_key预定义索引而不是d.deptno字段。让我们详细信息看下上图中的执行流程。
Phase Q:Ignite客户端节点初始化SQL查询并将SQL查询发送到所有节点。
Phase E(Q): 接收SQL查询的所有Ignite节点都对本地数据运行查询。
Phase D(Q):如果任何数据在本地缺失,它将通过以下方式从远程节点请求多播或单播请求。
Phase R1-3:所有节点都将它们的执行结果集发送到Ignite客户端节点。
Phase R: Ignite客户端节点将以reducer的形式出现,并将所有结果集中在一个结果集中。在我们的示例中,它将把结果打印到控制台。
以下是Sql query完整的代码样例:
Ignite配置文件:/resources/example-ignite.xml
127.0.0.1:47500
Ignite 日志配置文件:/resources/logback.xml
%d{HH:mm:ss.SSS} [%thread] %-5level %logger{5} - %msg%n
项目的pom.xml依赖配置文件:
4.0.0
com.mycookcode.bigData.ignite
ignite-sqlquery
jar
1.0-SNAPSHOT
ignite-sqlquery
http://maven.apache.org
UTF-8
2.6.0
junit
junit
3.8.1
test
org.apache.ignite
ignite-core
${ignite.version}
org.apache.ignite
ignite-indexing
${ignite.version}
org.apache.ignite
ignite-spring
${ignite.version}
org.apache.ignite
ignite-slf4j
${ignite.version}
org.slf4j
slf4j-api
1.7.25
ch.qos.logback
logback-classic
1.2.3
ch.qos.logback
logback-core
1.2.3
org.apache.maven.plugins
maven-compiler-plugin
3.3
1.8
1.8
com.jolira
onejar-maven-plugin
1.4.4
build-query
com.mycookcode.bigData.ignite.App
true
onejar
sql-query-employees-runnable.jar
one-jar
缓存的实体类文件:
com.mycookcode.bigData.ignite.model.Department:
package com.mycookcode.bigData.ignite.model;
import org.apache.ignite.cache.query.annotations.QuerySqlField;
import java.io.Serializable;
import java.util.Objects;
import java.util.concurrent.atomic.AtomicInteger;
public class Department implements Serializable {
private static final AtomicInteger GENERATED_ID = new AtomicInteger();
@QuerySqlField(index = true)
private Integer deptno;
@QuerySqlField
private String dname;
@QuerySqlField
private String loc;
public Department(String dname,String loc)
{
this.deptno = GENERATED_ID.incrementAndGet();
this.dname = dname;
this.loc = loc;
}
public Integer getDeptno() {
return deptno;
}
public void setDeptno(Integer deptno) {
this.deptno = deptno;
}
public String getDname() {
return dname;
}
public void setDname(String dname) {
this.dname = dname;
}
public String getLoc() {
return loc;
}
public void setLoc(String loc) {
this.loc = loc;
}
@Override public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Department that = (Department)o;
return Objects.equals(deptno, that.deptno) &&
Objects.equals(dname, that.dname) &&
Objects.equals(loc, that.loc);
}
@Override
public int hashCode() {
return Objects.hash(deptno, dname, loc);
}
@Override public String toString() {
return "Department[" +
"deptno=" + deptno +
", dname='" + dname + '\'' +
", loc='" + loc + '\'' +
']';
}
}
com.mycookcode.bigData.ignite.model.EmployeeKey:
package com.mycookcode.bigData.ignite.model;
import org.apache.ignite.cache.affinity.AffinityKeyMapped;
import java.io.Serializable;
import java.util.Objects;
public class EmployeeKey implements Serializable{
private final int empNo;
@AffinityKeyMapped
private final int deptNo;
public EmployeeKey(int empNo, int deptNo) {
this.empNo = empNo;
this.deptNo = deptNo;
}
public int getEmpNo() {
return empNo;
}
public int getDeptNo() {
return deptNo;
}
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
EmployeeKey key = (EmployeeKey)o;
return empNo == key.empNo &&
deptNo == key.deptNo;
}
@Override
public int hashCode() {
return Objects.hash(empNo, deptNo);
}
@Override
public String toString() {
return "EmployeeKey[" +
"empNo=" + empNo +
", deptNo=" + deptNo +
']';
}
}
com.mycookcode.bigData.ignite.model.Employee:
package com.mycookcode.bigData.ignite.model;
import org.apache.ignite.cache.query.annotations.QuerySqlField;
import org.apache.ignite.cache.query.annotations.QueryTextField;
import java.io.Serializable;
import java.time.LocalDate;
import java.util.concurrent.atomic.AtomicInteger;
public class Employee implements Serializable{
private static final AtomicInteger GENERATED_ID = new AtomicInteger();
@QuerySqlField(index = true)
private Integer empno;
@QuerySqlField
private String ename;
@QueryTextField
private String job;
@QuerySqlField
private Integer mgr;
@QuerySqlField
private LocalDate hiredate;
@QuerySqlField
private Integer sal;
@QuerySqlField(index = true)
private Integer deptno;
private transient EmployeeKey key;
public Employee(String ename, Department dept, String job, Integer mgr, LocalDate hiredate, Integer sal) {
this.empno = GENERATED_ID.incrementAndGet();
this.ename = ename;
this.job = job;
this.mgr = mgr;
this.hiredate = hiredate;
this.sal = sal;
this.deptno = dept.getDeptno();
}
public Integer getEmpno() {
return empno;
}
public void setEmpno(Integer empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public Integer getMgr() {
return mgr;
}
public void setMgr(Integer mgr) {
this.mgr = mgr;
}
public LocalDate getHiredate() {
return hiredate;
}
public void setHiredate(LocalDate hiredate) {
this.hiredate = hiredate;
}
public Integer getSal() {
return sal;
}
public void setSal(Integer sal) {
this.sal = sal;
}
public Integer getDeptno() {
return deptno;
}
public void setDeptno(Integer deptno) {
this.deptno = deptno;
}
//Affinity employee key
public EmployeeKey getKey() {
if (key == null) {
key = new EmployeeKey(empno, deptno);
}
return key;
}
@Override public String toString() {
return "Employee[" +
" ename='" + ename + '\'' +
", job='" + job + '\'' +
", mgr=" + mgr +
", hiredate=" + hiredate +
", sal=" + sal +
']';
}
}
Ignite服务启动类com.mycookcode.bigData.ignite.App,实现Sql query查询服务:
package com.mycookcode.bigData.ignite;
import com.mycookcode.bigData.ignite.model.Department;
import com.mycookcode.bigData.ignite.model.Employee;
import com.mycookcode.bigData.ignite.model.EmployeeKey;
import org.apache.ignite.Ignite;
import org.apache.ignite.IgniteCache;
import org.apache.ignite.Ignition;
import org.apache.ignite.cache.CacheMode;
import org.apache.ignite.cache.query.SqlFieldsQuery;
import org.apache.ignite.cache.query.SqlQuery;
import org.apache.ignite.configuration.CacheConfiguration;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.math.BigDecimal;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.Collection;
import java.util.List;
/**
* Hello world!
*
*/
public class App {
private static DateTimeFormatter formatter = DateTimeFormatter.ofPattern("dd-MM-yyyy");
private static Logger logger = LoggerFactory.getLogger(App.class);
private static final String DEPARTMENT_CACHE_NAME = App.class.getSimpleName() + "-departments";
private static final String EMPLOYEE_CACHE_NAME = App.class.getSimpleName() + "-employees";
public static void main(String[] args) throws Exception {
Ignite ignite = Ignition.start("example-ignite.xml");
logger.info("Start. Sql query example.");
CacheConfiguration deptCacheCfg = new CacheConfiguration<>(DEPARTMENT_CACHE_NAME);
deptCacheCfg.setCacheMode(CacheMode.REPLICATED);
deptCacheCfg.setIndexedTypes(Integer.class, Department.class);
CacheConfiguration employeeCacheCfg = new CacheConfiguration<>(EMPLOYEE_CACHE_NAME);
employeeCacheCfg.setCacheMode(CacheMode.PARTITIONED);
employeeCacheCfg.setIndexedTypes(EmployeeKey.class, Employee.class);
try (
IgniteCache deptCache = ignite.createCache(deptCacheCfg);
IgniteCache employeeCache = ignite.createCache(employeeCacheCfg)
) {
initialize();
sqlQuery();
sqlQueryWithJoin();
sqlQueryEmployeesWithSalHigherManager();
sqlFieldsQuery();
sqlFieldsQueryWithJoin();
aggregateQuery();
groupByQuery();
}
}
private static void initialize() throws InterruptedException {
IgniteCache deptCache = Ignition.ignite().cache(DEPARTMENT_CACHE_NAME);
IgniteCache employeeCache = Ignition.ignite().cache(EMPLOYEE_CACHE_NAME);
//启动之前清除缓存
deptCache.clear();
employeeCache.clear();
//Departments数据初始化
Department dept1 = new Department("Accounting", "New York");
Department dept2 = new Department("Research", "Dallas");
Department dept3 = new Department("Sales", "Chicago");
Department dept4 = new Department("Operations", "Boston");
//Employees数据初始化
Employee emp1 = new Employee("King", dept1, "President", null, localDateOf("17-11-1981"), 5000);
Employee emp2 = new Employee("Blake", dept3, "Manager", emp1.getEmpno(), localDateOf("01-05-1981"), 2850);
Employee emp3 = new Employee("Clark", dept1, "Manager", emp1.getEmpno(), localDateOf("09-06-1981"), 2450);
Employee emp4 = new Employee("Jones", dept2, "Manager", emp1.getEmpno(), localDateOf("02-04-1981"), 2975);
Employee emp5 = new Employee("Scott", dept2, "Analyst", emp4.getEmpno(), localDateOf("13-07-1987").minusDays(85), 3000);
Employee emp6 = new Employee("Ford", dept2, "Analyst", emp4.getEmpno(), localDateOf("03-12-1981"), 3000);
Employee emp7 = new Employee("Smith", dept2, "Clerk", emp6.getEmpno(), localDateOf("17-12-1980"), 800);
Employee emp8 = new Employee("Allen", dept3, "Salesman", emp2.getEmpno(), localDateOf("20-02-1981"), 1600);
Employee emp9 = new Employee("Ward", dept3, "Salesman", emp2.getEmpno(), localDateOf("22-02-1981"), 1250);
Employee emp10 = new Employee("Martin", dept3, "Salesman", emp2.getEmpno(), localDateOf("28-09-1981"), 1250);
Employee emp11 = new Employee("Turner", dept3, "Salesman", emp2.getEmpno(), localDateOf("08-09-1981"), 1500);
Employee emp12 = new Employee("Adams", dept2, "Clerk", emp5.getEmpno(), localDateOf("13-07-1987").minusDays(51), 1100);
Employee emp13 = new Employee("James", dept3, "Clerk", emp2.getEmpno(), localDateOf("03-12-1981"), 950);
Employee emp14 = new Employee("Miller", dept1, "Clerk", emp3.getEmpno(), localDateOf("23-01-1982"), 1300);
deptCache.put(dept1.getDeptno(), dept1);
deptCache.put(dept2.getDeptno(), dept2);
deptCache.put(dept3.getDeptno(), dept3);
deptCache.put(dept4.getDeptno(), dept4);
employeeCache.put(emp1.getKey(), emp1);
employeeCache.put(emp2.getKey(), emp2);
employeeCache.put(emp3.getKey(), emp3);
employeeCache.put(emp4.getKey(), emp4);
employeeCache.put(emp5.getKey(), emp5);
employeeCache.put(emp6.getKey(), emp6);
employeeCache.put(emp7.getKey(), emp7);
employeeCache.put(emp8.getKey(), emp8);
employeeCache.put(emp9.getKey(), emp9);
employeeCache.put(emp10.getKey(), emp10);
employeeCache.put(emp11.getKey(), emp11);
employeeCache.put(emp12.getKey(), emp12);
employeeCache.put(emp13.getKey(), emp13);
employeeCache.put(emp14.getKey(), emp14);
Thread.sleep(1000);
}
/**
* @param
* @return
*/
private static LocalDate localDateOf(String parseDateText) {
return LocalDate.parse(parseDateText, formatter);
}
/**
* 以薪水范围为查询条件检索数据
*/
private static void sqlQuery() {
IgniteCache cache = Ignition.ignite().cache(EMPLOYEE_CACHE_NAME);
SqlQuery qry = new SqlQuery(Employee.class, "sal > ? and sal <= ?");
logDecorated("==Employee with salaries between 0 and 1000==", cache.query(qry.setArgs(0, 1000)).getAll());
logDecorated("==Employee with salaries between 1000 and 2000==", cache.query(qry.setArgs(1000, 2000)).getAll());
logDecorated("==Employee with salaries greater than 2000==", cache.query(qry.setArgs(2000, Integer.MAX_VALUE)).getAll());
}
/**
* 基于为特定部门工作的所有员工的SQL查询示例。
*/
private static void sqlQueryWithJoin() {
IgniteCache cache = Ignition.ignite().cache(EMPLOYEE_CACHE_NAME);
SqlQuery qry = new SqlQuery<>(Employee.class,
"from Employee, \"" + DEPARTMENT_CACHE_NAME + "\".Department " +
"where Employee.deptno = Department.deptno " +
"and lower(Department.dname) = lower(?)");
logDecorated("==Following department 'Accounting' have employees (SQL join)==", cache.query(qry.setArgs("Accounting")).getAll());
logDecorated("==Following department 'Sales' have employees (SQL join)==", cache.query(qry.setArgs("Sales")).getAll());
}
/**
* 输出所有工资高于直属上级管理人员的员工
*/
private static void sqlQueryEmployeesWithSalHigherManager() {
IgniteCache cache = Ignition.ignite().cache(EMPLOYEE_CACHE_NAME);
SqlFieldsQuery qry = new SqlFieldsQuery("select e.ename ,e.sal,m.ename,m.sal from Employee e, " +
"(select ename,empno,sal from Employee) m " +
"where e.mgr = m.empno and e.sal > m.sal");
log("==All employees those salary bigger than their direct manager==");
logDecorated("||Employee||Emp.Salary||Manager||Mgr.Salary||", cache.query(qry).getAll());
}
/**
* 基于sql的字段查询的示例,该查询只返回必需字段,而不是整个键-值对
*/
private static void sqlFieldsQuery() {
IgniteCache cache = Ignition.ignite().cache(EMPLOYEE_CACHE_NAME);
SqlFieldsQuery qry = new SqlFieldsQuery("select ename from Employee");
Collection> res = cache.query(qry).getAll();
log("==Names of all employees==", res);
}
/**
* 基于sql的字段查询的示例,该查询只返回必需字段,而不是整个键-值对。
*/
private static void sqlFieldsQueryWithJoin(){
IgniteCache cache = Ignition.ignite().cache(EMPLOYEE_CACHE_NAME);
SqlFieldsQuery qry = new SqlFieldsQuery(
"select e.ename, d.dname " +
"from Employee e, \"" + DEPARTMENT_CACHE_NAME + "\".Department d " +
"where e.deptno = d.deptno");
Collection> res = cache.query(qry).getAll();
logDecorated("==Names of all employees and departments they belong to (SQL join)==", res);
}
/**
* 基于sql的字段查询的示例,该查询只返回必需字段,而不是整个键-值对。
*/
private static void aggregateQuery()
{
IgniteCache cache = Ignition.ignite().cache(EMPLOYEE_CACHE_NAME);
SqlFieldsQuery qry = new SqlFieldsQuery("select sum(sal), count(sal) from Employee");
Collection> res = cache.query(qry).getAll();
double sum = 0;
long cnt = 0;
for (List row : res)
{
if (row.get(0) != null) {
sum += ((BigDecimal)row.get(0)).doubleValue();
cnt += (Long)row.get(1);
}
}
log("==Average employee salary (aggregation query)==");
log("\t" + (cnt > 0 ? (sum / cnt) : "n/a"));
}
/**
* 基于sql的字段查询的示例,该查询只返回必需字段,而不是整个键-值对。
*/
private static void groupByQuery()
{
IgniteCache cache = Ignition.ignite().cache(EMPLOYEE_CACHE_NAME);
SqlFieldsQuery qry = new SqlFieldsQuery(
"select avg(e.sal), d.dname " +
"from Employee e, \"" + DEPARTMENT_CACHE_NAME + "\".Department d " +
"where e.deptno = d.deptno " +
"group by d.dname " +
"having avg(e.sal) > ?");
logDecorated("==Average salaries per Department (group-by query)==", cache.query(qry.setArgs(500)).getAll());
}
/**
* Prints message to logger.
*
* @param msg String.
*/
private static void log(String msg) {
logger.info("\t" + msg);
}
/**
* Prints message to logger.
*
* @param msg String.
*/
private static void log(String msg, Iterable col) {
logger.info("\t" + msg);
col.forEach(c -> logger.info("\t\t" + c));
}
/**
* Prints message and resultset to logger.
*
* @param msg String.
* @param col Iterable
*/
private static void logDecorated(String msg, Iterable col) {
logger.info("\t" + msg);
col.forEach(c -> logger.info("\t\t" + c));
}
}