
在上一篇文章《区块的持久化之BoltDB(一)》中我们分析了meta page的格式,为了便于理解后续内容,我们进一步来分析一下branch page和leaf page的格式。branch page中存的是B+Tree上内节点中的数据,即branchPageElements,而leaf page中存的是B+Tree上叶子节点中的数据,即leafPageElements,是存储实际K/V对的地方。B+Tree与B-Tree的一个显著区别便是如此,即B+Tree中只有叶子节点存储实际的K/V对,内节点实际上只用于索引,并且兄弟节点之间会形成有序链表,以加快查找过程;而B-Tree中的K/V是分布在所有节点上的。我们先来分别看看branchPageElement和leafPageElement的定义:
//boltdb/bolt/page.go
// branchPageElement represents a node on a branch page.
type branchPageElement struct {
pos uint32
ksize uint32
pgid pgid
}
......
// leafPageElement represents a node on a leaf page.
type leafPageElement struct {
flags uint32
pos uint32
ksize uint32
vsize uint32
}
branchPageElement定义中各字段的意义是:
- pos: element对应的K/V对存储位置相对于当前element的偏移,随后我们会更清楚地理解它;
- ksize:element对应的Key的长度,以字节为单位;
- pgid: element指向的子节点所在page的页号。
leafPageElement定义中的各字段的意义是:
- flags: 标明当前element是否代表一个Bucket,如果是Bucket则其值为1,如果不是则其值为0;
- pos: 与branchPageElement中的pos字段意义一样;
- ksize: element对应的Key的长度,以字节为单位;
- vsize: element对应的Vaule的长度,以字节为单位。
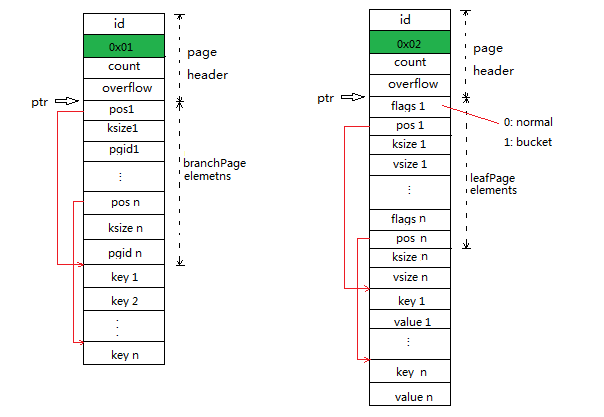
一个branchPage或leafPage由页头和若干branchPageElements或leafPageElements组成,那么这些元素是如何在磁盘上布局的呢?我们可以看看node的write(p *page)方法:
//boltdb/bolt/node.go
// write writes the items onto one or more pages.
func (n *node) write(p *page) {
// Initialize page.
if n.isLeaf {
p.flags |= leafPageFlag
} else {
p.flags |= branchPageFlag
}
......
// Loop over each item and write it to the page.
b := (*[maxAllocSize]byte)(unsafe.Pointer(&p.ptr))[n.pageElementSize()*len(n.inodes):] (1)
for i, item := range n.inodes {
_assert(len(item.key) > 0, "write: zero-length inode key")
// Write the page element.
if n.isLeaf {
elem := p.leafPageElement(uint16(i)) (2)
elem.pos = uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem))) (3)
elem.flags = item.flags
elem.ksize = uint32(len(item.key))
elem.vsize = uint32(len(item.value))
} else {
elem := p.branchPageElement(uint16(i)) (4)
elem.pos = uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem))) (5)
elem.ksize = uint32(len(item.key))
elem.pgid = item.pgid
_assert(elem.pgid != p.id, "write: circular dependency occurred")
}
......
// Write data for the element to the end of the page.
copy(b[0:], item.key) (6)
b = b[klen:] (7)
copy(b[0:], item.value) (8)
b = b[vlen:] (9)
}
......
}
为了便于理解,我们提前简要介绍下node的概念。node是一个page加载到内存中后的结构化表示,即它是page反序列化(或者实例化)的结果;相反地,page是node的序列化结果,上述的write()方法就是node的序列化过程。page中存的K/V对反序列化后会存在node.inodes中,page中的elements个数与node.inodes中的个数相同,而且一一对应。
在write(p *page)方法中:
- 根据node是否是叶子节点确定page是leafPage还是branchPage;
- 代码(1)处定义了byte数组指针b,它指向p.ptr指向的位置向后偏移n.pageElementSize()*len(n.inodes)的位置。上文中我们介绍过p.ptr实际上指向页头结尾处或者页正文开始处,所以b实际上是指向了页正文中elements的结尾处,而且elements是从页正文起始处开始存的,这一点我们在下面可以看到;
- 通过for循环将所有K/V记录顺序写入页框;
- 在代码(2)处,定义了一个leafPageElement指针elem,它指向page中第i个leafPageElement:
//boltdb/bolt/page.go
// leafPageElement retrieves the leaf node by index
func (p *page) leafPageElement(index uint16) *leafPageElement {
n := &((*[0x7FFFFFF]leafPageElement)(unsafe.Pointer(&p.ptr)))[index]
return n
}
从上面代码可以看到,当index=0时,第1个leafPageElement是从p.ptr指向的位置开始存的,而且所有leafPageElement是连续存储的,可以通过index进行数组索引。类似地,代码(5)处,定义了一个branchPageLement指针,它指向page中的第i个branchPageElement。在branchPage中,branchPageElement也是从页正文起始处顺序存储的:
//boltdb/bolt/page.go
// branchPageElement retrieves the branch node by index
func (p *page) branchPageElement(index uint16) *branchPageElement {
return &((*[0x7FFFFFF]branchPageElement)(unsafe.Pointer(&p.ptr)))[index]
}
- 代码(3)处给leafPageElement的pos字段赋值,它的值为b[0]到当前leafPageElement的偏移,而b[0]实际上位于第i个K/V对的起始位置。当i=0时,b[0]实际上就是页中最后一个element的结尾处。一次for循环,实际上就是写入一个element和一个K/V对。代码(4)处和代码(3)处类似,branchPageElement中的pos字段赋值为b[0]到当前branchPageElement的偏移;
- 代码(6)处将Key写入&b[0]处;
- 代码(7)处将b向前移klen字节,即移到Key的结尾处。习惯于C/C++中指针操作的读者可能对这里b的处理有些疑惑,实际上Go虽然保留了指针,但还是谨慎地禁止了指针的偏移操作,所以试图用指针偏移进行读写的地方均用slice来操作;
- 代码(8)将Value写入&b[0]处,即Value写入Key后的位置;
- 代码(9)将b向前移vlen字节,即移动到Value的结尾处,准备写入下一个Key。
从代码(6)、(7)、(8)和(9)处,我们可以知道,页中存储K/V是以Key、Value交替连续存储的;代码(1)、(3)和(5)可以看到所有的K/V对是在页中的elements结构结尾处存储,且每个element通过pos指向自己对应的K/V对,pos的值即是K/V对相对element起始位置的偏移;而代码(2)和(4)处可以看出,elements是从页正文开始处存储的。需要说明的是,B+Tree中的内结点并不存真正的K/V对,它只存Key用于查找,故branch page中实际上没有存Key的Value,所以branchPageElement中并没像leafPageElement那样定义了vsize,因为branchPageElement的vsize始终是0。
通过上面的分析,我们可以得到branch page和leaf page的磁盘布局如下:
到此,我们就知道了BoltDB数据库文件在磁盘上的详细布局情况了(freelist page请大家自行分析)。特别地,由于OS从磁盘读文件或者内核将页缓冲写入磁盘也是以页大小为单位操作的,BoltDB中每一页的大小与操作系统的页大小保持一致,且也以页为单位对数据库文件进行读写,可以降低磁盘I/O的次数,提高数据库的读写效率。
清楚了BoltDB在磁盘上的存储格式后,我们要进一步了解这些页是如何被组织起来,以便于进行查找、读写等。我们已经知道,BoltDB采用B+Tree来进行查找,page实例化成node,node便是B+Tree中的节点,若干node形成一颗B+Tree。在BoltDB中,一个Bucket对应一颗B+Tree。那么,对BoltDB的查找,实际上就是对B+Tree的查找;对BoltDB进行K/V读写,就是对B+Tree上的叶子节点读写及对B+Tree进行动态调整。为了深入了解这些过程,接下来,我们开始分析前文给出的典型应用示例中的db.Update()方法,并从它入手来分析BoltDB的Transaction、Bucket等机制。
//boltdb/bolt/db.go
// Update executes a function within the context of a read-write managed transaction.
// If no error is returned from the function then the transaction is committed.
// If an error is returned then the entire transaction is rolled back.
// Any error that is returned from the function or returned from the commit is
// returned from the Update() method.
//
// Attempting to manually commit or rollback within the function will cause a panic.
func (db *DB) Update(fn func(*Tx) error) error {
t, err := db.Begin(true)
if err != nil {
return err
}
// Make sure the transaction rolls back in the event of a panic.
defer func() {
if t.db != nil {
t.rollback()
}
}()
// Mark as a managed tx so that the inner function cannot manually commit.
t.managed = true
// If an error is returned from the function then rollback and return error.
err = fn(t)
t.managed = false
if err != nil {
_ = t.Rollback()
return err
}
return t.Commit()
}
db.Update(fn func(*Tx) error)的传入参数是一个函数值(function-value),且函数的传出参数为一个Tx指针。传入的函数值可以理解为回调函数的函数指针,可以通过函数名(fn)进行调用,通过回调函数传出的Tx指针指向内部创建的一个Transation,调用者通过指向的Transaction对象进行创建、查找、删除及遍历Bucket的操作。db.Update()方法主要执行:
- 通过db.Begin(writeable bool)创建一个Transaction;
- 回调传入的回调函数,将刚创建的Tx指针传出;
- 调用t.Commit()将对BoltDB的修改提交并写入磁盘;
- 如果回调函数返回error,或者transaction在Commit的时候发生异常或错误,当前transation进行的写操作将会回滚(Rollback),不会写入磁盘。
db.Begin(writeable bool)的代码比较简单,如果传入的writeable为true,则调用db.beginRWTx()创建一个可以读写的transaction;如果writeable为false,则调用db.beginTx()创建一个只读transaction。可以看到,db.Update()会创建可读写transaction,而db.View()将创建只读transaction。
//boltdb/bolt/db.go
func (db *DB) beginRWTx() (*Tx, error) {
....
// Obtain writer lock. This is released by the transaction when it closes.
// This enforces only one writer transaction at a time.
db.rwlock.Lock()
// Once we have the writer lock then we can lock the meta pages so that
// we can set up the transaction.
db.metalock.Lock()
defer db.metalock.Unlock()
......
// Create a transaction associated with the database.
t := &Tx{writable: true} (1)
t.init(db) (2)
db.rwtx = t (3)
......
return t, nil
}
在db.beginRWTx()中:
- 获取读写锁,db.rwlock只有在transaction 被Commit或者Rollback的时候释放,也即它将锁定读写transaction的整个生命周期,实现了一个进程内同时只有一个读写transaction。请注意,虽然它的名字叫rwlock,但它并不是读写锁,而是一个互斥锁(sync.Mutex)。结合我们在《区块的持久化之BoltDB(一)》中分析的,调用bolt.Open()方法打开数据库文件时,如果以读写的方式打开,文件锁将会被独占,防止同时有多个进程写文件。结合文件锁与db.rwlock,BoltDB可以保证同一时段只有一个进程的一个线程可以对数据库修改。如果在Go中调用,可以认为只有一个goroutine会修改数据库,尽管一个goroutine可能会被调度到不同的内核线程上。这里大家可能会对它的MVCC支持有疑问,这里先不讨论,待介绍完它的工作机制后我们再讨论。
- 获取db.metalock,需要注意的是,metalock实际上是对db对象的访问保护,特别是对db.txs的读写保护,而不是如名字或者注释中说的专门对meta page的读写保护。
- 代码(1)处新建了一个Tx对象,并通过t来引用,随后代码(2)处调用t.init()方法来对刚刚创建的读写Tx进行初始化;
- 代码(3)处将db.rwtx设为刚刚创建并初始化的transaction。db.txs字段用来记录所有的已打开的只读transaction,它是一个map,从这里也可以看出,BoltDB同时只能有一个可读写transaction,但可以有多个只读transactions;
作为比较,我们再来看看db.beginTx()的实现:
//boltdb/bolt/db.go
func (db *DB) beginTx() (*Tx, error) {
// Lock the meta pages while we initialize the transaction. We obtain
// the meta lock before the mmap lock because that's the order that the
// write transaction will obtain them.
db.metalock.Lock()
// Obtain a read-only lock on the mmap. When the mmap is remapped it will
// obtain a write lock so all transactions must finish before it can be
// remapped.
db.mmaplock.RLock()
......
// Create a transaction associated with the database.
t := &Tx{} (1)
t.init(db) (2)
// Keep track of transaction until it closes.
db.txs = append(db.txs, t) (3)
n := len(db.txs)
// Unlock the meta pages.
db.metalock.Unlock()
......
return t, nil
}
在db.beginTx()中:
- 获取db.metalock,因为后面要对db对象进行读写;
- 获取db.mmaplock读锁,db.mmaplock是一个读写锁(sync.RWMutex),它的读锁在只读transaction关闭的时候释放,也即db.mmaplock的读锁在整个只读transaction的生命周期中被占用。前面我们在db.mmap()中接触过它,db.mmap()的整个过程被db.mmaplock的写锁保护。db.mmap()在两种情况下会被调用: 第一情形便是我们前文介绍的数据文件创建或打开后进行第一次内存映射时;第二种情形是我们后面将要介绍到的,在写入数据库后且数据库文件要增大时,分配新的页框后,需要重新进行mmap系统调用将新的文件范围映射入进程地址空间。在前一种情况中,还没有开始db.beginTx()的调用,故不存在db.mmaplock锁争用问题,但当数据库在不同线程中进行读写时,可能存在其中一个线程中的读写transaction写入了大量数据,在Commit时,由于当前已映射区的空闲页不够,会调用db.mmap()重新进行内存映射,此时若有未关闭的只读transaction,由于它占用着在db.mmaplock的读锁,db.mmap()会阻塞在争用db.mmaplock写锁的地方。也就是说,如果存在着耗时的只读transaction,同时写transaction需要remmap时,写操作会被读操作阻塞。由此可以看出,使用BoltDB时,应尽量避免耗时的读操作,同时在写操作时应避免频繁地remmap,我们将在介绍BoltDB的MVCC机制时再讨论这个问题。
- 代码(1)处创建一个只读transaction对象,代码(2)处对其进行初始化;
- 代码(3)处将刚创建并初始化的只读transation加入到db.txs中。
db.beginRWTx()和db.beginTx()的主要工作均是准备Tx,我们来看一看它的定义:
//boltdb/bolt/tx.go
// Tx represents a read-only or read/write transaction on the database.
// Read-only transactions can be used for retrieving values for keys and creating cursors.
// Read/write transactions can create and remove buckets and create and remove keys.
//
// IMPORTANT: You must commit or rollback transactions when you are done with
// them. Pages can not be reclaimed by the writer until no more transactions
// are using them. A long running read transaction can cause the database to
// quickly grow.
type Tx struct {
writable bool
managed bool
db *DB
meta *meta
root Bucket
pages map[pgid]*page
stats TxStats
commitHandlers []func()
// WriteFlag specifies the flag for write-related methods like WriteTo().
// Tx opens the database file with the specified flag to copy the data.
//
// By default, the flag is unset, which works well for mostly in-memory
// workloads. For databases that are much larger than available RAM,
// set the flag to syscall.O_DIRECT to avoid trashing the page cache.
WriteFlag int
}
其中各字段的意义如下:
- writable: 指示是否是可读写的transaction;
- managed: 指示当前transaction是否被db托管,即通过db.Update()或者db.View()来写或者读数据库。BoltDB还支持直接调用Tx的相关方法进行读写,这时managed字段为false;
- db: 指向当前db对象
- meta: transaction初始化时从db中数到的meta信息;
- root: transaction的根Bucket,所有的transaction均从根Bucket开始进行查找;
- pages: 当前transaction读或写的page;
- stats: 与transaction操作统计相关,不作介绍;
- commitHandlers: transaction在Commit时的回调函数;
- WriteFlag: 复制或移动数据库文件时,指定的文件打开模式,暂不作介绍,有兴趣的读者可以自行分析。
其中比较关键的字段是meta和root,我们将在tx.init()方法中看到它们的初始化过程:
//boltdb/bolt/tx.go
// init initializes the transaction.
func (tx *Tx) init(db *DB) {
tx.db = db
tx.pages = nil
// Copy the meta page since it can be changed by the writer.
tx.meta = &meta{}
db.meta().copy(tx.meta)
// Copy over the root bucket.
tx.root = newBucket(tx)
tx.root.bucket = &bucket{}
*tx.root.bucket = tx.meta.root
// Increment the transaction id and add a page cache for writable transactions.
if tx.writable {
tx.pages = make(map[pgid]*page)
tx.meta.txid += txid(1)
}
}
在tx.init()中:
- 将tx.db初始化为传入的db,将tx.pages初始化为空;
- 创建一个空的meta对象,并用它初始化tx.meta,然后将db中的meta复制到刚创建的meta对象中,请注意,这里的复制是对象拷贝而不是指针拷贝。前面我们介绍过,db中有两个meta,那这里拷贝的是哪一个meta呢?我们来看看db.meta()的代码:
//boltdb/bolt/db.go
// meta retrieves the current meta page reference.
func (db *DB) meta() *meta {
// We have to return the meta with the highest txid which doesn't fail
// validation. Otherwise, we can cause errors when in fact the database is
// in a consistent state. metaA is the one with the higher txid.
metaA := db.meta0
metaB := db.meta1
if db.meta1.txid > db.meta0.txid {
metaA = db.meta1
metaB = db.meta0
}
// Use higher meta page if valid. Otherwise fallback to previous, if valid.
if err := metaA.validate(); err == nil {
return metaA
} else if err := metaB.validate(); err == nil {
return metaB
}
// This should never be reached, because both meta1 and meta0 were validated
// on mmap() and we do fsync() on every write.
panic("bolt.DB.meta(): invalid meta pages")
}
可以看出,db.meta()返回的是两个meta中txid更大且通过校验的那个,前面我们说meta中的txid可以看作是数据库的修改版本号,所以db.meta()返回的meta对应的是数据库最新的状态。
- 通过newBucket(tx *Tx)创建一个Bucket,并将其设为根Bucket,同时用meta中保存的根Bucket的头部来初始化transaction的根Bucket头部。在没有介绍Bucket之前,这里稍微有点不好理解,简单地说,Bucket包括头部(bucket)和一些正文字段,头部中包括了Bucket的根节点所在的页的页号和一个序列号,所以tx.init()中对tx.root的初始化其实主要就是将meta中存的根Bucket(它也是整个db的根Bucket)的头部(bucket)拷贝给当前transaction的根Bucket;
- 如果是可读写的transaction,就将meta中的txid加1,当可读写transaction commit后,meta就会更新到数据库文件中,数据库的修改版本号就增加了。
到此,db.Update()中的db.Begin(bool)的主要过程我们就都了解了,它主要是准备了Tx对象,初始化了其中的meta和根Bucket。接着,我们就可以在回调函数中通过回传的Tx指针来执行创建、查找、删除和遍历Bucket等操作。BoltDB中所有的K/V记录都归属在Bucket中,Bucket可以嵌套,形成树结构。BoltDB中读K/V时,得先从根Bucket开始查找到K/V所在的Bucket,再在找到的Bucket中通过Key查找K/V记录;类似地,写K/V时,得指定写入哪一个Bucket,或者先创建一个Bucket再往新的Bucket中写入记录。那么,Bucket究竟是什么样子的,它们是如何嵌套的,它们是否也是通过B+Tree来组织的呢?我们将在下篇文章《区块的持久化之BoltDB(三)》中介绍。
==大家可以关注我的微信公众号,后续文章将在公众号中同步更新:==
