前篇主要介绍流式计算相关的核心概念,这篇简要聊聊Flink总体架构、运行环境及其在大数据生态系统中的位置,让大家先对Flink有整体认知,便于后期理解。
一、Flink介绍
1.1 什么是流处理
还是选回顾下流处理到底解决了什么问题、流处理的优势是什么,更详细的描述可看这篇文章:#Flink CookBook—流式计算介绍#
在用流处理之前,状态数据通常存储在数据库、文件系统,然后应用程序根据需要再查询或计算数据:

流式计算改变了这种处理模型,应用的处理、查询和分析是连续不断的,数据不间断的从系统中流过。流系统接收到事件后,会做一系列操作,比如更新聚合数据或进行其他统计,甚至多个流进行join,产生新的数据流供其他应用使用:

在Lambda架构中,流处理层提供相似结果集,这是因为早期的流系统,比如Storm存在限制,现代的流处理引擎有很强的容错性,而且Flink的状态管理有生产级的可靠性,即使程序出现异常也能保证正确的结果。
1.2 什么是Flink
Flink是一个低延迟、高吞吐、批流统一的、有状态的流式计算引擎,用于为大批量数据构建高效、快速、准确和容错的流处理应用。Flink把批处理作为流处理的特殊情况去支持,在这种模式下,依然没有丢失流处理的优势。随着近两年Flink在企业成功应用的案例越来越多,而且阿里巴巴对Blink的开源,极大的增加了Flink的成熟度,Flink逐步被人们所关注、所熟知。
时间列表
flink诞生于德国一家叫data Artisans的公司,最初产品名叫Stratosphere,2014年项目改名为Flink、捐献给Apache基金会进行开源,并基于0.5版本的Stratosphere构建了第一个Flink版本,版本号是0.6。Flink在2015年正式毕业,成为apache顶级项目。flink社区活跃度图:
二、系统架构
2.1 系统组件
Flink由以下几个组件组成,通过协同完成计算工作:
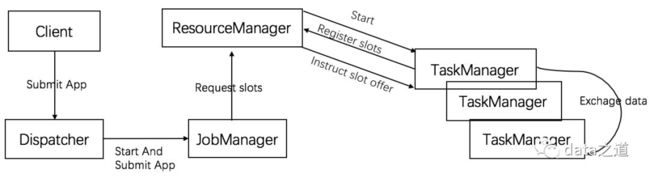
Flink组件交互图
根据部署环境的不同,上面中的一些步骤可能省略或组件可能在同一节点(JVM)运行。
JobManager
flink的master进程,负责整个集群的任务管理、资源管理、协调应用程序的分布执行,每个应用程序都存在至少一个JobManager:在HA场景下,其中一个JM是active、另一个处在standy by。JM接收到要执行的应用程序,会向RM请求资源(资源单位是solt),RM把TM空闲的slots进行分配,JM一旦分配到足够的资源,就把任务分发到对应TM上去执行。在任务执行过程中,jm也会响应所有的请求动作:比如savepoint、checkpoint等。
ResourceMananger
ResourceManager管理TaskManager的solts(flink资源单位),根据不同的执行环境,提供了不同的资源管理实现,比如Yarn、Standalone都有各自的实现方式
TaskManager
flink的work进程(JVM进程),提供一定数量的插槽,插槽数就是TM可以并发执行的task数。tm启动时,会把插槽注册到rm,rm按照规则把tm的一个或多个插槽分配给jm。当任务提交到JM,JobManager会根据已经注册的TaskManager的资源(slots)情况,将任务分配给有资源的TaskManager节点,TaskManager从JobManager接收需要部署的任务,然后使用Slot资源启动Task。Flink的worker采用单进程多线程的方式并发执行task。
Flink的TaskManager类似于Spark的worker节点,不同的是一个Spark worker节点上还可以同时跑多个Executor进程(JVM进程),一个Executor进程只会被一个Spark APP独享,然后Executor里以多线程方式执行具体任务。Spark这种设计的好处是将各个应用之间的资源消耗进行了隔离,每个应用都运行在它们各自的JVM中。
Client
用于向JM提交任务,客户端不是运行环境的一部分,也不是执行任务的一部分,一旦应用提交,客户端就可以断开连接,或者保持连接以接收程序执行进度报告
2.2 任务并发
Flink应用程序是并发执行的,任务被分发到集群里的工作进程。假设应用由五个运算符组成:A和C是source、E是sink,C和E有两个并行度(两个子任务),其他的有四个并行度(四个子任务),因为算子的最大并行度是4,该应用程序要求至少有4个可用solt(默认情况下同一个job的不同task的子任务可以共享同一个slot),JM会请求至少和应用程序的最大算子并行度一样多的solt。如果分配的solts数比并行度小,即线程数小于并发度,就满足不了以特定的并发数执行任务了。如果有两个TaskManager,每个上面都提供两个插槽,那task可能的分布情况如下:

任务并发执行
TM在一个JVM进程里以多线程的方式执行task,即一个TM是一个JVM进程,其以线程的方式执行一个或多个子任务。
当一个TM有多个插槽时,意味着多个任务共享同一个JVM的资源,比如TCP连接、心跳信息,甚至共享数据集、数据结构,这会降低每个任务的吞吐率。需要注意的是,单个task在运行时可能会把整个work的内存占满,导致一个异常的任务可能会把整个TM进程kill掉,这样运行在之上的其他任务也都被kill掉了。
当一个TM配置一个插槽,意味着每个任务在单独的JVM里执行,可达到应用程序独立部署、资源隔离的目的,防止异常的应用干扰其他无关的应用。
2.3 任务链
Flink采用任务链的方式,将多个算子的子任务链到同一个任务里,在同一个线程里执行,这样做的好处是可以减少线程切换、网络通信和缓存开销,在降低延迟的同时提高整体吞吐率。Flink即使是在同一个TaskManager的不同task(不同线程)进行数据传输,也不会产生网络通信。
任务链上的算子要求具有相同的并发度、并在本地链接,这点很容易理解,如果并发度不同或者需要跨节点通信,就没办法实现任务在同一个线程执行。

如果:三个算子,每个都有两个并发度
以任务链的方式执行,算子会链接到一个任务被一个线程执行,一个算子的输出数据以简单的方式输入到下个算子,这种情况下,函数之间的数据传递基本上不会有序列化和传输成本。

如图:任务链示意图,多个算子的子任务在一个线程里执行
没有任务链的情况,算子都是由独立的线程执行单独的task进行计算,数据被序列化后在线程间传输,而且也有可能用到TaskManager的网络缓冲(如果task在不同的worker里执行),这样可能会降低程序执行效率。当然,在某些场景下,没有任务链的执行效率可能比有任务链的执行效率还要高。

Flink任务链功能和Spark Stage划分机制有异曲同工之处,都是为了实现数据的本地化处理。
三、编程模型
3.1 API层次结构
Flink提供了不同层次的接口,方便开发者灵活的开发流处理、批处理应用,根据接口使用的便捷性、表达能力的强弱分为四层:

API层次结构
Stateful Stream Process:是Flink中处理Stateful Stream最底层的接口,用户可以使用Stateful Stream Process接口操作状态、时间等底层数据。使用Stream Process API接口开发应用的灵活性非常强,可以实现非常复杂的流式计算逻辑,但是相对用户使用成本也比较高
Core APIs:相对于ProcessFunction来说,又进一步进行了封装,封装成两个api,datastream用于处理无界数据流、dataset用于处理有界数据集。DataStream API和DataSet API接口都同时提供了各种数据处理接口,例如map, filter、joins、aggregationswindow、state等方法,用户可以直接用这些api进行数据处理操作。
Flink也提供了声明式、关系型编程接口,Table API以及基于Table API的SQL API,用户只需关注做什么、不用关注怎么做,使用结构化编程接口高效地构建Flink应用。Table API以及SQL屏蔽了底层实现细节,能够统一处理批量和实时计算业务,无须切换修改任何应用代码就能够基于同一套API编写流式应用和批量应用,从而达到真正意义的批流统一。
sql:在上层统一批处理和流处理,即一个sql可以跑流处理,又可以跑批处理。SQL是接受度最广的语言,学习成本低,能够让用户更专注于业务本身,而不用受限复杂的编程接口
Table:在底层的DataSet和DataStream加上schema信息,将数据类型抽象成表,为用户提供更加友好的处理方式。内部以目录(catalog)的形式管理Schema的元数据与命名空间,如表和UDF。
实时处理无界数据流的系统要求有很低的延迟性,而无界数据流通常不会对延迟性有要求,这样Flink对批处理会有更简单、高效的优化方式。DataStream API支持低延迟处理结果、以及对事件、时间的灵活处理;DataSet API通常对有界数据流的处理模型进行优化,这种优化的技术手段在未来又会反哺到DataStream API里。
3.2 Table、DataStream、DataSet转化关系

转换关系图
DataStream转换成Table有多种方法
直接转换,调用Table Environment的fromDataStream方法,返回一个Table对象;随后可以用registerTable方法为该Table指定一个表名
数据流转换成表,调用Stream Environment的toTable方法,数据流转换Table,该方法返回一个Table对象。其底层调用的还是fromDataStream方法
表注册,调用Table Environment的registerDataStream方法,把数据流注册成指定的表,方法接收一个表名参数
Sql在Table上执行操作:

Table转换成DataStream也有两种方式
追加模式(toAppendStream),即表的行追加到DataStream中。Table只会有新增数据,如果有更新、删除的转换就会异常
撤回模式(toRetractStream),将Stream转换成二元组,第一个字段是Boolean类型,true表示是新增消息操作、false表示是删除消息操作。
DataSet转换成Table
直接转换(fromDataSet)
注册模式(registerDataSet)
Table转换成dataset
table.toDataSet
3.3 程序结构
像MapReduce、Spark等处理引擎一样,Flink也遵循着一定的编程模式,不管是使用DataStream API还是DataSet API都具有基本相同的程序结构。
配置执行环境
流执行环境和批处理执行环境的API 分别是StreamingExecutionEnvironment和DataStream,有三种方法获取到执行环境:
//根据程序执行的上下文,返回本地执行环境或者远程执行环境getExecutionEnvironment()//创建本地执行环境createLocalEnvironment()//创建远程执行环境createRemoteEnvironment(host:String,port: Int,jarFiles:String*)
2.构造数据源
Source是应用程序读取数据的地方,Flink有预定义的Source实现,当然也可以自定义实现。如果是自定义实现,需要通过addSource方法把source添加到执行环境。

3. 在数据集(DataStream/DataSet)上执行transformation,实现业务逻辑
针对批处理和流处理,flink实现了不同的算子操作,大体上来说分为Map、开窗、分组、join、聚合、分区这几大类,也因为有了丰富的算子,降低了学习成本、提高了开发效率。流中的每个事件进行转换、多个流合并成一个流、一个流分割成多个流,聚合操作:对流中事件聚合。
4. 将最终结果保存到外部系统
一旦转换后的数据是我们业务期望的最终结果,可以创建一个sink把结果写到文件、socket、外部系统或者直接打印输出。也可以调用addSink方法添加自定义的sink

5. 执行应用程序
执行execute()方法触发程序执行,如果是批处理环境,可以不用显示执行;如果是流式环境,需要显示触发
四、Flink特性
易用性
Flink社区长期致力于提供更高级别的API,从而抽象出许多复杂的时间和状态。例如,在Flink中处理事件时间和定义时间窗口一样简单:提取时间戳、水印(每个流只需要执行一次)。处理状态就像在Java程序中定义变量并使用Flink注册变量一样简单。而像Flink的StreamSQL这样的功能将允许在无限的数据流上进行SQL查询。
惰性计算
Flink应用程序是惰性执行的,当执行程序的main方法时,数据加载和转换不会真正发生,而是创建算子、并将其加到程序的执行计划里,在环境里调用execute(),显示触发,才会真正的执行任务操作;程序是在本地执行还是集群执行,取决于执行环境。正是因为有了惰性计算,Flink才可以对用户构建的复杂应用程序的执行计划进行整体优化,比如任务链的实现。
Exactly-Once
完全一致性意味着应用程序的状态在程序发生故障前后保持一致,就好像每个消息只处理一次一样。用于容错的全局备份快照可确保Apache Flink应用程序的一致性视图,从而确保容错和Exactly-Once应用程序语义。
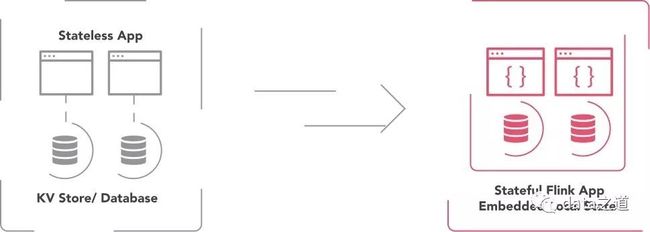
状态管理
flink内置了状态管理,所以对flink应用程序来说,状态的修改、查找都是本地操作,并且可以在不中断数据的情况下管理备份。当在应用程序内部管理数据和状态时,减少了链接外部数据库的需求,进而实现非常高的计算性能:
CheckPoint
是应用程序的定时、异步、一致性的快照操作。Flink定期记录(快照)它在输入流中读取的位置以及每个操作的相应状态, 如果发生故障,Flink会将输入流和操作状态回滚到先前的、一致的全局状态,并从那里重新开始计算,因此即使重放记录,最终结果状态就好像消息只被处理一次一样。保证不丢失状态、并且checkpoint对延迟的影响可以忽略不计。
savepoint
如果要进行Flink版本升级、应用程序的更新或者服务器停机维护,savepoint可以保证在整个过程中不丢失状态数据。savepoint依赖checkpoint,手动触发checkpoint:在整个分布式集群上捕获当前状态快照、生成检查点,并把快照写入到后端。Flink在程序可以是新增算子或删除算子,但必须保留原有的输入输出类型。当从保存点启动应用程序时,flink必须将保存点中持久化的状态和应用程序中算子进行匹配,如果应用程序的DAG发生了变化,flink要求算子分配一个唯一的id,用于状态和算子的匹配,建议程序对所有的算子分配id。

保存点默认保存在Job Manager里,如果Job Manager关闭,那么保存在上面的保存点将丢失。savepoint和定期的checkpoint的区别包括两点,是用户主动触发操作,而且checkpoint数据是用户自己管理,即使新的checkpoint完成了,旧的checkpoint数据也不会自动过期。
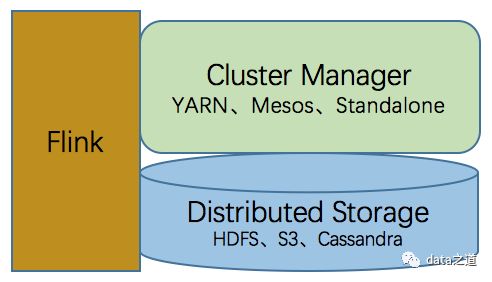
五、Flink和大数据生态系统集成
首先Flink不是用来解决数据存储问题的,而是在work节点上执行计算的,这点有别于Hadoop,Hadoop包括一个HDFS、MapReduce。可以在单个节点上的单个JVM上跑Flink(称为local模式),但更常见的场景是Flink与分布式存储系统(比如HDFS、Cassandra、S3)和集群管理器相结合使用。
分布式存储系统用于存储Flink结果数据、checkpoints、snapshots,集群管理器用于协调Flink应用在集群上的任务分发和管理。Flink支持多种不同的集群部署模式:Standalone、Apache Mesos、Hadoop YARN等。