主要内容
1.从项目中看机器学习对商业决策的重要性
2.什么是机器学习?从案例分析中介绍机器学习能解决的问题
3.数据可视化,进行分析进而得到商业洞察
一、机器学习
人工智能的分支,目标是通过算法从现有的数据中建立模型来解决问题
特点:
1.交叉学科。涉及概率统计、优化、计算机编程等
2.用途广泛。如预测信用卡违约风险、癌症病人五年生存概率、汽车无人驾驶等
3.备受重视。在决策分析的时候,越来越多的利用定量方法(quantitive approach)来衡量一个决策的优劣
解析
关于定量方法在网上也是查了很久,具体的定义写的都很模糊。找到了如图中的定义讲解,不确定是否正确,链接放在这里研究方法-定量方法

机器学习与大数据的关系
应用机器学习的算法到数据中来估计模型参数,而大规模的数据是获得稳健参数估计的基础
机器学习主要任务
- 监督学习:从给定的训练数据集中学出一个函数,新的数据可根据这个函数预测结果;监督学习的训练集要求包括输入和输出,也可以说是特征和目标
例:预测某地区的房价、信用卡违约概率、手写数字的识别、房贷违约预测
- 无监督学习:训练集没有人为标注的结果,从输入数据本身探索规律
例:图片聚类分析、文章主题分类、基因序列分析、高维数据降维
二、案例分析
(一)波士顿地区房价
房价分析与预测是典型的监督学习
- 数据来源

- 特征描述

- 数据读取
- 数据可视化
解析
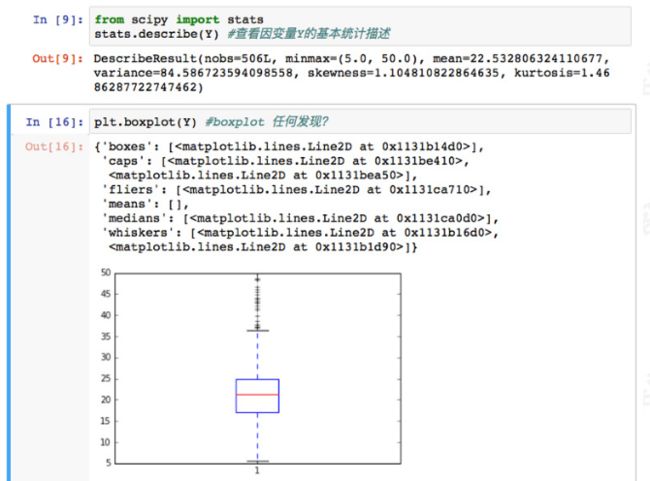
1.箱线图的绘制依靠实际数据,不需要事先假定数据服从特定的分布形式,没有对数据作任何限制性要求,它只是真实直观地表现数据形状的本来面貌;另一方面,箱形图判断异常值的标准以四分位数和四分位距基础,四分位数具有一定的耐抗性,多达25%的数据可以变得任意远而不会很大地扰动四分位数,所以异常值不能对这个标准施加影响,箱形图识别异常值的结果比较客观。由此可见,箱形图在识别异常值方面有一定的优越性 ——源自百度百科
2.从图中可以看出,Y最小值5,最大值50,中间值22左右。箱线图顶部有一些离群值,房价偏高。整体数据分布并不对称

- 模型拟合

解析
1.sklearn是机器学习中一个常用的python第三方模块,里面对一些常用的机器学习方法进行了封装。在进行机器学习任务时,并不需要每个人都实现所有的算法,只需要简单的调用sklearn里的模块就可以实现大多数机器学习任务
2.直线拟合是否充分?抛物线拟合会不会更好?
关于这个问题很难给出我的回答,因为两种方法都有各自的优势,没有哪个更好的说法,只有合适不合适一说。抛物线拟合可能会更准确,然而可能会面对过拟合等问题,无法保证准确度;直线拟合可能会遗漏重要的数值,同样也无法保证新的数据输入后输出数据的准确度。
- 商业洞察

- 特征选择

解析
因案例是经典的回归问题,所以采用Lasso方法进行特征提取。Lasso特征选取方法亦可称之为L1正则化。
在这里简单的描述一下正则化模型,想要了解更多的特征提取方法,可以戳进这个链接如何进行特征选取
正则化模型:正则化就是把额外的约束或者惩罚项【penalty,处罚之意。课件中写错了在此纠正一下】加到已有模型(损失函数)上,以防止过拟合并提高泛化能力。
损失函数则由原来的E(X,Y)变为E(X,Y)+alpha||w||,w是模型系数组成的向量,||·||一般是L1或者L2范数(想了解范数可自行百度谷歌,此处不再赘述)
alpha是一个可调的参数,控制着正则化的强度。当用在线性模型上时,L1正则化和L2正则化也称为Lasso和Ridge。两者的区别在于L2惩罚项中系数是二次方的,系数的取值也更平均。具体的定义与特征可戳链接解读。
Lasso将系数w的l1范数作为惩罚项加到损失函数上,由于正则项非零,这就迫使那些弱的特征所对应的系数变成0。因此Lasso往往会使学到的模型很稀疏(系数w经常为0),这个特性使得L1正则化成为一种很好的特征选择方法。
- 选取最优alpha
解析
1.cross-validation,交叉验证。其基本思想是把在某种意义下将原始数据进行分组,一部分做为训练集,另一部分做为测试集。首先用训练集对分类器进行训练,再利用测试集来测试训练得到的模型,以此来做为评价分类器的性能指标
2.RMSE,均方根误差。i=1,2,3,…n,在有限测量次数中,均方根误差常用下式表示:√[∑di^2/n]=Re,n为测量次数,di为一组测量值与真值的偏差
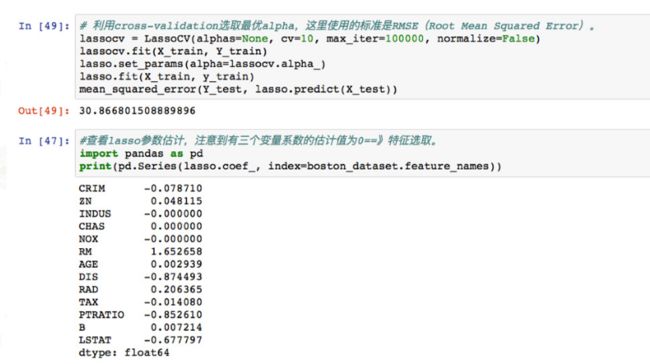
3.从上图可以看出众多特征对房价的影响,排除无影响的三个因素后,可观察到犯罪率对房价的影响是负相关的,而波士顿的房价与房子的年龄成正相关,这与我们的常识认知相悖。
当然在了解到关于波士顿的基础知识后也同样能得出这样的结论,然而这需要经过大量功课才了解到的信息我们通过简单的数据信息提取就可以获得。
同样,不同的特征影响的程度也高低不同,从结果中可以看到对房价负面影响最大的是距离就业中心的加权距离,而正面影响最大的是平均每户的房间数。
从以上的解析中可以进一步预测波士顿地区的房价,筛选出有发展前景的地区,进一步规划未来的建设。当然说的有点远,但并不妨碍我们了解到数据分析的便捷与重要性,机器学习在数据分析中对最终决策的重大影响。
(二)贷款违约预测
典型的监督学习中的分类问题,最常见的方法有逻辑回归或分类树
- 数据来源
借贷俱乐部静止贷款记录(已偿还或已违约的贷款)
- 特征描述

- 分类变量描述


解析
1.从贷款信息描述图中可看出B类贷款占比重最大
2.从两年内违约量图中可得出, 均值0.21,最小值0,最大值29,中位数是0,四分位数均为0,可以得出变量高度不对称,高度右偏的,所以均值大于中位数。
- 数据可视化
解析
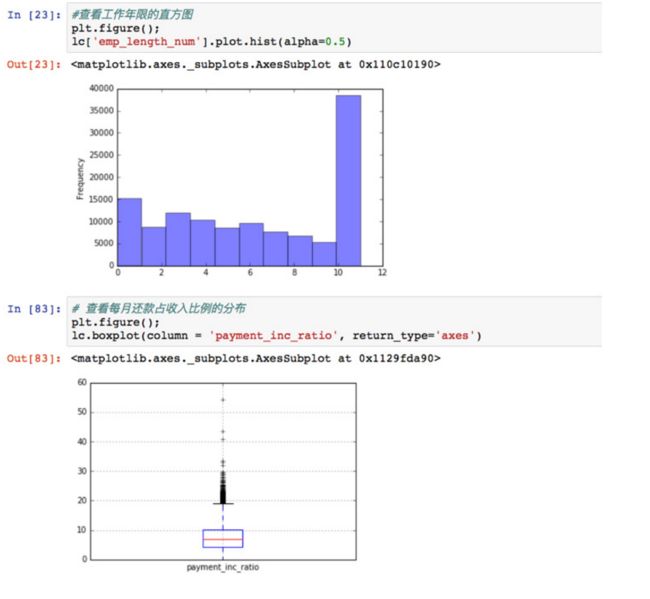
1.大部分人的工作经验超过10年,一部分人工作年限<1年
2.每月月供占收入百分比最小值在0左右,中位数在8~9左右。在箱线图顶层有部分离群值,可得出这组数据是高度不对称的分布
- 模型拟合
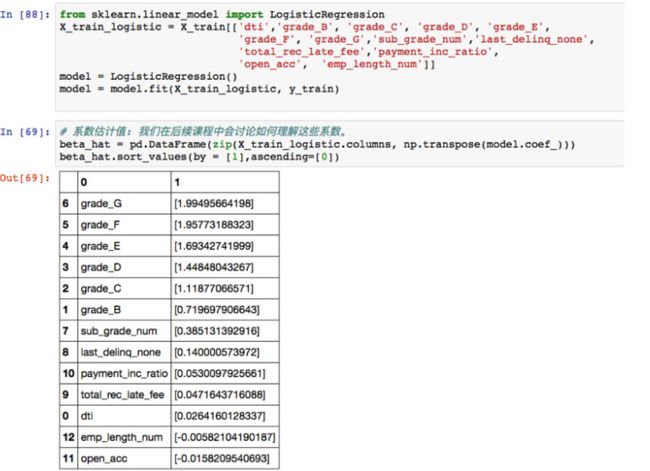
解析
1.如图中结果所示,G级贷款对违约影响最大,依次顺序影响递减
2.贷款等级越差,违约概率越高
3.贷款收入比dti增加,贷款违约率也会增加
4.工作年限越长,贷款违约率越低
5.拥有越多的信用卡,违约率越低【原因:信用卡公司会评估用户的信用与还款能力,能得到越多的信用卡,就有越高的还款能力】
- 商业洞察

- 概率预测

解析
得到预测的违约概率结果后,需要确定边界值。当预测概率大于边界值便归为违约,小于边界值则不违约。
那么问题来了:哪个预测失败的代价更大?
违约预测成正常贷款,正常贷款预测成违约哪个代价更大?
前者受到经济上的损失,后者损失一名潜在客户
简单来说,我们希望采用更保守的方法,以减少经济损失,所以边界值取得相对较小
- 测试模型表现
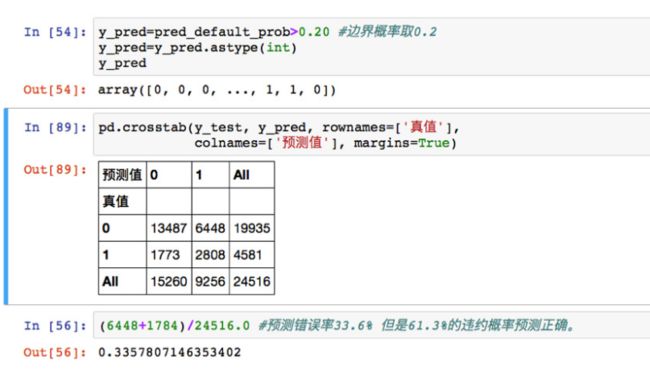
解析
边界值定为0.2,将真值预测正确的概率是正确率,预测错误的概率是错误率,根据计算可得到预测错误率为33.6%,正确率61.3%。
【key】找到平衡点:降低错误率的同时,也不能漏掉违约的那些可能**
- 决策树
快速确定决定违约风险的重要变量
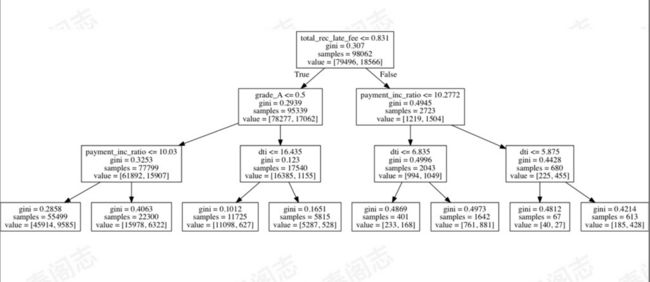
解析
通过决策树可以很直观的看到哪些因素将影响最后的违约概率,也可以利用决策树的可视化与他人进行业务沟通
三、总结

四、思考
简单的案例分析让我们认知到缜密的分析流程,便捷的分析算法包与模块,灵活的运用机器学习方法,恍然间有种竟然如此简单的想法。当然只是幻觉,这一切呈现出来的细节与逻辑思想都没有分析透彻,只是了解大概的步骤,知其然不知其所以然。达到吴博士那个运用自如的程度怕是还有很长时间,当然这也不能成为阻止我们前进的理由。
在回顾课程期间,通过自主搜索也了解到了很多未接触过的知识,本身也是自我知识迭代的过程。非常期待后续关于机器学习的课程,感觉自己会学到很多东西,同时把这些学到的知识整理成文也让我对它们有了新的认知。
以上。