前情提要
前一篇文章中,因为豆瓣的 API 请求限制,我无法一次性请求整个读书记录的信息列表,于是想到在每个请求前随机等待若干时间,以避免豆瓣的请求限制。
前有堵截,后有追兵
文档描述与实际情况不一致?
运行代码,发现还是无法获得预期效果。用 Postman 再次查看信息,发现出现的错误信息跟之前一样:
{
"msg": "rate_limit_exceeded2: 43.243.12.21",
"code": 112,
"request": "GET /v2/book/search"
}
又到网络上搜索资料,这次发现,有很多开发者遇到了类似的问题,而且他们在自己的博客中指出,豆瓣限制的其实不只是文档中写明的一小时的请求频率,还有一分钟的请求频率。
我将信将疑,等时间限制过了之后,用 Postman 再次发送请求,这次我重点查看 response header,发现有了两个参数跟文档上描述得不一致。
插图
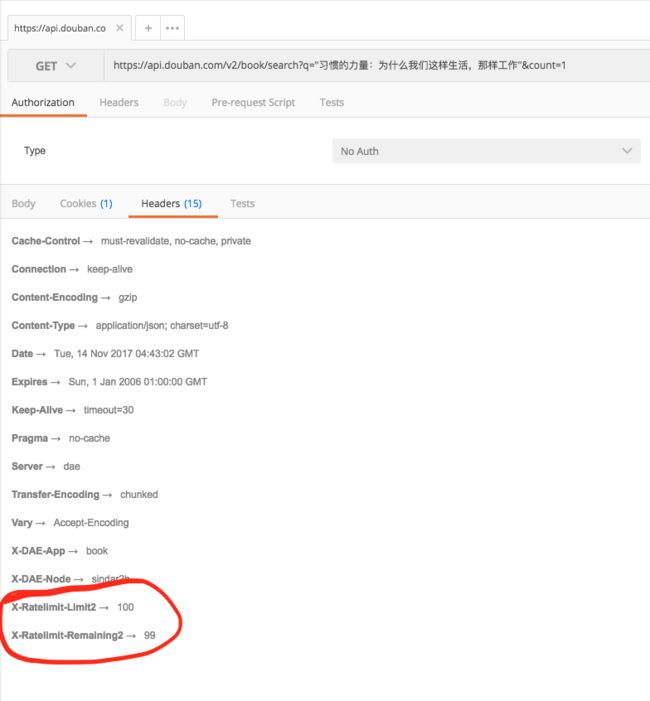

插图
文档上最低的请求限制是 500 次每小时,可在我得到的响应中,写得却是 100 次每小时。
难道是因为我没有申请豆瓣的开发者账号吗?
算了,且不纠结这个。
每分钟 35 次限制?
看别人的博客时,发现有的博主说到,豆瓣的 API 还有个每分钟不能超过 35 个请求的限制。
我不是很请求这个限制是否真的有,也不想试,因为请求次数很宝贵,试上两次就得等个一小时才能重新发请求了。
干脆直接就将这个条件纳入考虑。
每分钟速度限制 + 每小时次数限制
综合考虑到这两个限制之后,我大概的思路是这个样子的:
- 将两百多条记录做个 partition,分为四份,一个小时请求一次
- 每个请求前,随机等待 0 - 5 秒钟 (试了十几次,最长的一次请求返回之间大概是三秒,稍微多等待一点时间)
程序是下面这个样子
const agent = require('superagent');
const async = require('async');
const _ = require('underscore');
const bookTitleList = require('./book_title_list');
function sleep(milliseconds) {
let start = new Date().getTime();
for (let i = 0; i < 1e7; i++) {
if ((new Date().getTime() - start) > milliseconds) {
break;
}
}
}
function random_sleep(second) {
sleep(Math.floor((Math.random() * second) + 1) * 1000)
}
function requestTags(bookTitle, done) {
random_sleep(5);
agent.get(encodeURI(`https://api.douban.com/v2/book/search?q="${bookTitle}"&count=1`))
.end((err, res) => {
if (err) {
console.log(err);
} else {
const tag = res.body.books[0].tags;
done(null, tag);
}
}
);
}
function partition(items, size) {
let result = _.groupBy(items, function(item, i) {
return Math.floor(i/size);
});
return _.values(result);
}
const milliseconds_of_one_hour = 60 * 60 * 1000;
partition(bookTitleList, 80).forEach(subList => {
async.map(subList, requestTags, (err, tags) => {
tags.forEach(tag => {
console.log(tag);
})
});
sleep(milliseconds_of_one_hour);
})
写好程序之后,我满心欢喜,运行命令,就直接工作去了。想着晚上下班了直接看效果就行了
当头棒喝
没想到呀没想到,结果还是错的,这是怎么搞得!
命名已经将时间限制和次数限制都加上了呀,还有什么其他问题呢?
仔细地看了错误信息,发现很奇怪的一点,有几个请求是成功的,但是还是无法拿到 tag,报了空指针异常,也就是在 const tag = res.body.books[0].tags; 这一行报错了。
欸,难道是这本书不存在。
的确有可能,为了验证这个想法,我加了个防御语句
let book = res.body.books[0];
const tag = book ? book.tags : `=======================================================empty book ${bookTitle}`
只有当响应中包含 books 并且第一个元素不为空时,我才去取 tags,对于不存在的书,返回特定的字符串加上书名,后面好看得出来是哪本书没有得到响应。
Deadline 是第一生产力
改完之后,发现时间已经不够用了,距离 11 点写作训练的截止时间只剩下不到两小时。如果还按照这个程序执行的话,我就无法完成今天的训练了。
情急之下,我把读书记录分为 8 份,每份 30 条记录左右。手动执行程序,在一个小时多一点的时间内,拿到了所有的豆瓣标签,并将它们合到了一块。
重新使用抄来的 python 程序,成功生成词云图,由于这次直接使用标签而不是书名,所以我拿掉了 分词 的语句。但是,又遇到了编码的问题,几经周
折,最后终于在既定时间内以非常丑陋的代码既定的目标。
最后生成的标签词云如下:

对比上一次使用分词工具对书名处理过后得到的词云图,结果看起来区别还是很大的。

比如,在新的图片中,看不到重复的词(比如旧图中重复的 Java),也没有被错误分开的词语(比如 皮格马利翁效应 )。总的来说,这次生成的词云应该算是成功的。
未完待续……
因为赶时间,所以我最后是以非常丑陋的代码实现的这些功能。在下一篇文章给中,我想讲讲我如何重构我这些丑陋的代码,使得它们不那么丑陋(挽回一点面子 -_-|| )。
如果你想看下有多丑陋,点击前往代码库