前言
收到告警信息:”10.XXX.XXX.XXX机器CPU占用过高,请立即查看排查,确认无误后关闭告警!“, 那 linux CPU占用飙升要如何排查定位呢?
自己简单规整了下,最基本的排查方式可以分为以下几步吧?
- 确认是程序性能问题导致,还是系统硬件瓶颈?
- 确认引发CPU飙升的进程,进程PID?
- 确认引发飙升进程下哪个线程CPU占用率较高?
- jstack打印进程下全部的线程堆栈信息,查找CPU占用较高的线程的堆栈详情信息?
- 根据第四步的堆栈信息,确定出现问题的代码行号,对比程序,修改优化程序。
如何确认是程序性能问题导致,还是系统硬件瓶颈?
个人习惯的做法是,使用先vmstat查看CPU负载情况:
vmstat : 查看系统维度的CPU负载
// 每间隔1秒钟打印一次系统维度的CPU复杂情况
vmstat -n 1

返回结果中的主要数据列说明:
r: 表示系统中 CPU 等待处理的线程。由于 CPU 每次只能处理一个线程,所以,该数值越大,通常表示系统运行越慢。
us:用户模式消耗的 CPU 时间百分比。该值较高时,说明用户进程消耗的 CPU 时间比较多,比如,如果该值长期超过 50%,则需要对程序算法或代码等进行优化。
sy:内核模式消耗的 CPU 时间百分比。
wa:IO 等待消耗的 CPU 时间百分比。该值较高时,说明 IO 等待比较严重,这可能磁盘大量作随机访问造成的,也可能是磁盘性能出现了瓶颈。
id:处于空闲状态的 CPU 时间百分比。如果该值持续为 0,同时 sy 是 us 的两倍,则通常说明系统则面临着 CPU 资源的短缺。
一般我主要关注us与wa两列,如果us列长时间处于高占比,比如50%以上,那么我会怀疑是程序导致的,文章我们也是以程序导致为例来看这个问题。
确认引发CPU飙升的进程,进程PID?
上一步我们确认了是程序导致的(不需要关注图片的具体参数,因为只是记录,并不是真实的CPU飙升场景),这里我们会使用TOP命令来查看进程维度的CPU负载:
// 直接输入top命令
top

直接在终端输入P,可按照cpu占用排序显示
我们发现java进程的cpu占比较高,而我这台机器上确实部署了一个个人网站,是java开发的(https://www.relaxheart.cn),所以可以初步确定是这个java应用中的某个线程,或者多个线程导致的。
当然你也可以在top命令模式下,进程这个操作(输入小写k,然后输入进程PID,回车)直接终止掉占比较高的进程。
load average 是对 CPU 负载的评估,其值越高,说明其任务队列越长,处于等待执行的任务越多。
出现此种情况时,可能是由于僵死进程导致的。可以通过指令 ps -axjf 查看是否存在 D 状态进程。
D 状态是指不可中断的睡眠状态。该状态的进程无法被 kill,也无法自行退出。只能通过恢复其依赖的资源或者重启系统来解决。
确认引发飙升进程下哪个线程CPU占用率较高?
确认了是java进程导致CPU飙升后,我们可以在终端通过jps或者java进程的PID,然后在使用 top -H -p java进程pid 查看占用CPU较高的java线程
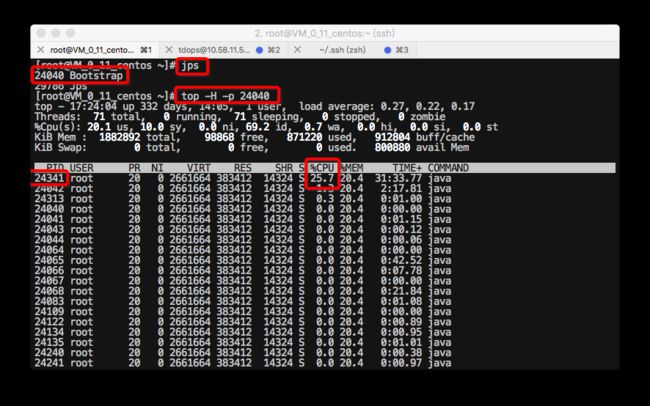
以我这台机器打印结果中的24341这个PID对应的线程为例,我们假设就是这个线程占用最高导致的。
jstack打印进程下全部的线程堆栈信息,查找CPU占用较高的线程的堆栈详情信息?
将24341这个十进制的pid转化为16进制的,方式如下:
[root@VM_0_11_centos ~]# printf "%x\n" 24341
5f15
然后使用jstack打印java进程的堆栈信息,查看0x5f15对应的具体堆栈信息:
[root@VM_0_11_centos ~]# jstack 24040 | grep 5f15
"ContainerBackgroundProcessor[StandardEngine[Catalina]]" #35 daemon prio=5 os_prio=0 tid=0x00007fd53022b800 nid=0x5f15 waiting on condition [0x00007fd4fb0fd000]
可以看到这样显示的不全,那一般的话会先打印全部堆栈信息到文件中,在文件中查看:
[root@VM_0_11_centos ~]# jstack 24040 > jstack.log

找到nid=0x5f15对应的堆栈信息,查看对应的java应用哪一行的代码,在具体的确认问题,针对问题就行代码修改或优化。