apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: 192.168.200.197:80/test-private/busybox:latest
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
通过下面的方式运行:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
pod/counter created
查看日志方式:
[root@kube-196 ~]# kubectl logs -f counter
1126: Tue Jun 18 09:27:07 UTC 2019
1127: Tue Jun 18 09:27:08 UTC 2019
1128: Tue Jun 18 09:27:09 UTC 2019
1129: Tue Jun 18 09:27:10 UTC 2019
1130: Tue Jun 18 09:27:11 UTC 2019
1131: Tue Jun 18 09:27:12 UTC 2019
这些日志文件,在宿主机上的什么位置呢?
[root@kube-196 ~]# less /var/log/pods/default_counter_9ce0c974-91a8-11e9-9cd8-fa163e1e5fde/count/0.log
{"log":"1081: Tue Jun 18 09:26:22 UTC 2019\n","stream":"stdout","time":"2019-06-18T09:26:22.866910994Z"}
{"log":"1082: Tue Jun 18 09:26:23 UTC 2019\n","stream":"stdout","time":"2019-06-18T09:26:23.868754044Z"}
{"log":"1083: Tue Jun 18 09:26:24 UTC 2019\n","stream":"stdout","time":"2019-06-18T09:26:24.870266589Z"}
{"log":"1084: Tue Jun 18 09:26:25 UTC 2019\n","stream":"stdout","time":"2019-06-18T09:26:25.871929216Z"}
[root@kube-197 kube-proxy]# cd /var/log/containers/
[root@kube-197 containers]# ll
total 112
lrwxrwxrwx 1 root root 101 Jun 25 10:47 apm-els-elasticsearch-master-2_default_chown-2a0eea1ac1a4c4a8fe66fa5ab16bbdcf896fde9c5e752abdc5bbe6340fd00a17.log -> /var/log/pods/default_apm-els-elasticsearch-master-2_ac94ba63-96f2-11e9-9cd8-fa163e1e5fde/chown/0.log
lrwxrwxrwx 1 root root 109 Jun 25 10:47 apm-els-elasticsearch-master-2_default_elasticsearch-e6727337b8d1146868f480ce829a13100629aa78f61786c1aa8823850bfdfbc5.log -> /var/log/pods/default_apm-els-elasticsearch-master-2_ac94ba63-96f2-11e9-9cd8-fa163e1e5fde/elasticsearch/0.log
$ kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
$ kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
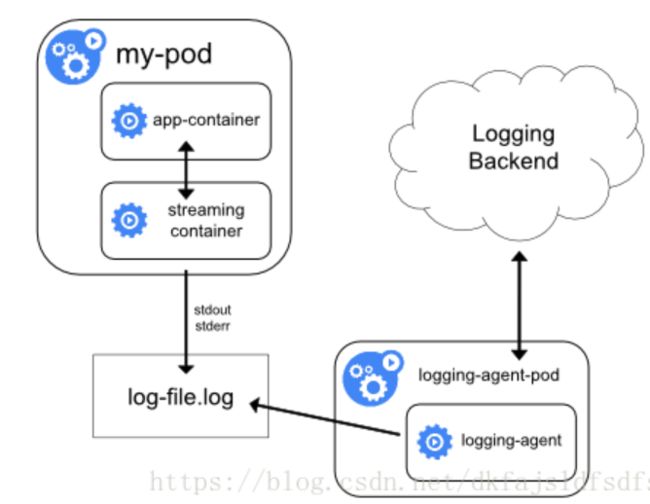
由于 sidecar 跟主容器之间是共享Volume的,所以这里的sidecar方案的额外性能损耗并不高,也就是多占用一点 CPU 和内存罢了。
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
type google_cloud
现实生活中,有些工作是需要团队中成员依次完成的,这就涉及到了一个顺序问题。现在有T1、T2、T3三个工人,如何保证T2在T1执行完后执行,T3在T2执行完后执行?问题分析:首先问题中有三个实体,T1、T2、T3, 因为是多线程编程,所以都要设计成线程类。关键是怎么保证线程能依次执行完呢?
Java实现过程如下:
public class T1 implements Runnabl
hive在使用having count()是,不支持去重计数
hive (default)> select imei from t_test_phonenum where ds=20150701 group by imei having count(distinct phone_num)>1 limit 10;
FAILED: SemanticExcep
转载源:http://blog.sina.com.cn/s/blog_4f925fc30100rx5l.html
mysql -uroot -p
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
[root@centos var]# service mysql
#mq
xdr.mq.url=tcp://192.168.100.15:61618;
import java.io.IOException;
import java.util.Properties;
public class Test {
String conf = "log4j.properties";
private static final
有一个工程,本来运行是正常的,我想把它移植到另一台PC上,结果报:
java.lang.RuntimeException: Unable to instantiate activity ComponentInfo{com.mobovip.bgr/com.mobovip.bgr.MainActivity}: java.lang.ClassNotFoundException: Didn't f
// 报错如下:
$ git pull origin master
fatal: unable to access 'https://git.xxx.com/': SSL certificate problem: unable to get local issuer ce
rtificate
// 原因:
由于git最新版默认使用ssl安全验证,但是我们是使用的git未设