Java 虚拟机负责处理内存,程序员无须关心,看起来很美好。然而一旦出现内存泄漏或溢出,如果不了解虚拟机的内存管理机制,那么排查错误就是一种痛苦的工作。
1 运行时的数据区域
根据 Java 虚拟机规范(Java SE 7),Java 虚拟机把内存划分为以下几个不同的数据区域:
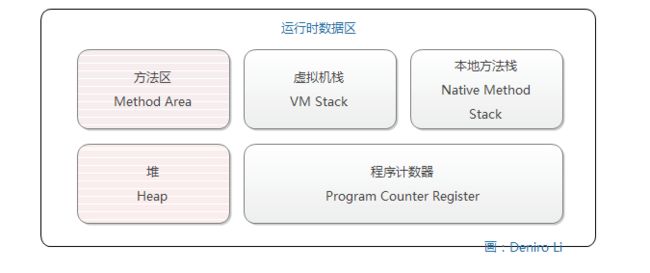
- 横条区:是由所有线程共享的区域。
- 其他:线程私有(线程隔离)的区域。
1.1 程序计数器
程序计数器是一块较小的区域,可以认为是当前线程所执行的字节码的行号指示器。在虚拟机概念模型中,字节码解析器是通过这个计数器来选取下一条需要执行的字节码指令的,比如分支、循环、跳转、异常处理、线程恢复等基础操作都需要依赖这个计数器。
Java 虚拟机的多线程,是通过线程切换来分配处理器的执行时间的。所以在任意时刻,一个处理器(多核处理器中指的是一个内核)只会执行一个线程中的指令。为了线程切换后能够恢复到正确的执行位置,每个线程都需要一个独立的程序计数器。
程序计数器是唯一一个在规范中没有规定出现 OutOfMemoryError 情况的区域。
1.2 Java 虚拟机栈
Java 虚拟机栈也是线程私有的,它的生命周期与线程相同。虚拟机栈保存的是执行 Java 方法的内存模型,用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
局部变量表存的是编译期可知的基本数据类型(boolean、byte 等)、对象引用类型和 returnAddress 类型(指向一条字节码指令的地址)。
64 位长度的 long 和 double 类型的数据会占用 2 个局部变量空间,其他类型只会占用一个。
规范对这个区域规定了两种异常情况:
- 如果线程请求的栈深度大于虚拟机所允许的深度,会抛出 StackOverflowError 异常;
- 如果虚拟机栈可以动态扩展(规范也允许固定长度的虚拟机栈),在扩展时无法申请到足够的内存,会抛出 OutOfMemoryError 异常。
1.3 本地方法栈
本地方法栈是为虚拟机用到的 Native 方法服务。规范没有对本地方法栈使用的语言、方法和数据结构进行强制要求,所以具体的虚拟机可以自由实现。甚至有的虚拟机(HotSpot)直接就把本地方法栈和虚拟机栈合二为一咯O(∩_∩)O~
本地方法栈与 Java 虚拟机栈一样,也会抛出 StackOverflowError 或 OutOfMemoryError 异常。
1.4 Java 堆
对大多数应用来说,Java 堆是 Java 虚拟机所管理的内存中最大的一块。它被所有线程共享,在虚拟机启动时创建。用于存放对象实例。
Java 堆是垃圾回收器主要的管理区域,因此它又被称为 “GC 堆”(Garbage Collected Heap)。
根据规范,Java 堆可以处于物理上不连续(逻辑上连续)的内存空间中。当前主流的虚拟机是按照可扩展的方式实现的(通过 -Xmx 和 -Xms 控制)。如果堆中没有内存可以分配实例,而且也无法再扩展时,就会抛出 OutOfMemoryError 异常。
1.5 方法区
方法区(Method Area)和 java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 Java 虚拟机规范把方法描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的是为了与 Java 堆区分开来。
Java 虚拟机规范对方法区的限制非常宽松, 除了和 Java 堆一样不需要连续的内存和可以选择固定大小或者可扩展之外, 还可以选择不实现垃圾收集。 相对而言, 垃圾收集行为在这个区域是比较少出现的, 但并非数据进入了方法区就如永久代的名字一样“ 永久” 存在了。 这个区域的回收“ 成绩” 比较难以令人满意, 尤其是类型的卸载, 条件相当苛刻, 但是这部分区域的回收确实是必要的。 在 Sun 公司的 BUG 列表中, 曾出现过的若干个严重的 BUG 就是由于低版本的 HotSpot 虚拟机对此区域未完全回收而导致内存泄漏。
根据 Java 虚拟机规范的规定, 当方法区无法满足内存分配需求时, 将抛出 OutOfMemoryError 异常。
1.6 运行时常量池
运行时常量池(Runtime Costant Pool )是方法区的一部分,Class 文件中除了有类的版本、字段、方法、接口等描述信息之外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
Java 虚拟机对 Class 文件的每一部分的格式都有严格的规定,但对于运行时常量池,Java 虚拟机规范没有做任何细节的要求。
运行时常量池相对于 Class 文件常量池的一个重要特征是具备动态性,Java 语言并不要求常量一定只有在编译期才能产生,也就是并非预置入
Class 文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的变量放入池中,这种特性被开发人员利用的比较多的便是 String类中的 intern() 方法。
既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 异常。
1.7 直接内存
在 JDK1.4 中新加入了 NIO (New Input/Output)类,引入了一种基于通道与缓冲区的 I/O 方式,他可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著地提高性能,因为这种方法避免了在Java 堆和 Native 堆中来回复制数据。
显然,本机直接内存的分配不会受到 Java 堆大小的限制,但是还是会受到本机总内存大小以及处理器寻址空间的限制。服务器管理员在配置虚拟机参数时,会根据实际内存设置 -Xmx 等参数信息,但经常忽略了直接内存,这会使得各个内存区域总和大于物理内存限制(包括物理的和操作系统级的限制),从而导致动态扩展时出现 OutOfMemoryError 异常。
2 HotSpot 虚拟机对象
我们以常用的虚拟机 HotSpot 和常用的内存区域 java 堆为例,来深入探讨 HotSpot 虚拟机在 java 堆中对象分配、布局和访问的全过程。
2.1 对象的创建
虚拟机在遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
在类加载检查通过后,虚拟机将将为新生对象分配内存,对象所需的内存大小在类加载完成后便可完全确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。分配内存的方法有这些:
- 指针碰撞 - 假设 Java 堆中的内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界点的指示器,那么分配内存就仅仅把那个指针向空闲空间那边挪动一段与对象大小相等的距离。
- 空闲列表 - 假设 Java 堆中的内存不是绝对规整的,已使用的内存和空闲的内存相互交错,那么虚拟机就必须维护一个列表,记录有哪些内存块是可用的,在分配时从列表中找到一块足够大的空间划分给对象实例,更更新列表上的记录。
选择哪一种分配方式由 java 堆是否规整来决定,而 java 堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。因此,在使用 Serial、ParNew 等带压缩过程的收集器时,系统采用的分配算法是指针碰撞,而使用 CMS 这种基于 Mark-Sweep 算法的收集器时,则通常采用空闲列表算法。
对象创建在虚拟机中是非常频繁的行为,因此要考虑在并发情况下保证线程安全。有两种解决方案:
- 对分配内存空间的动作进行同步处理 - 实际上虚拟机采用 CAS 配上失败重试的方案来保证更新操作的原子性。
- 把分配内存空间的动作按照线程划分在不同的空间之中进行,即每个线程在 java
堆中预先分配一小块内存,称为本地线程分配缓冲(Thread Local Allocation Buffer,TLAB)。哪个线程要分配内存,就在哪个线程的 TLAB 上分配,只有 TLAB
用完并分配新的 TLAB 时,才需要同步锁定。虚拟机是否使用 TLAB,可以通过-XX:+/-UseTLAB参数来设定。
内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),如果使用了 TLAB,这一工作也可以提前到 TLAB 分配时进行。这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就可以直接使用。
从程序的角度来看,执行 new 指令之后还会接着执行 init 方法,把对象按照编码者的意愿进行初始化。这样一个正在可用的对象才算完全产生出来。
HotSpot 虚拟机中 new 指令的代码片段(bytecodeInterpreter.cpp):
CASE(_new): {
u2 index = Bytes::get_Java_u2(pc+1);
constantPoolOop constants = istate->method()->constants();
//确保常量池中存放的是已解释的类
if (!constants->tag_at(index).is_unresolved_klass()) {
//断言确保是 klassOop 和 instanceKlassOop
// Make sure klass is initialized and doesn't have a finalizer
oop entry = constants->slot_at(index).get_oop();
assert(entry->is_klass(), "Should be resolved klass");
klassOop k_entry = (klassOop) entry;
assert(k_entry->klass_part()->oop_is_instance(), "Should be instanceKlass");
instanceKlass* ik = (instanceKlass*) k_entry->klass_part();
//确保对象所属类型已经经过初始化阶段
if ( ik->is_initialized() && ik->can_be_fastpath_allocated() ) {
size_t obj_size = ik->size_helper();//取对象长度
oop result = NULL;
// If the TLAB isn't pre-zeroed then we'll have to do it
bool need_zero = !ZeroTLAB;//记录是否需要将对象所有字段置零值
if (UseTLAB) {
result = (oop) THREAD->tlab().allocate(obj_size);
}
if (result == NULL) {
need_zero = true;
// Try allocate in shared eden(直接在 eden 中分配对象)
retry:
HeapWord* compare_to = *Universe::heap()->top_addr();
HeapWord* new_top = compare_to + obj_size;
// cmpxchg 是 x86 中的 CAS 指令(C ++ 方法),这里通过 CAS 指令来分配空间,如果并发失败,会转到 retry 中重试,直到成功分配为止
if (new_top <= *Universe::heap()->end_addr()) {
if (Atomic::cmpxchg_ptr(new_top, Universe::heap()->top_addr(), compare_to) != compare_to) {
goto retry;
}
result = (oop) compare_to;
}
}
if (result != NULL) {//如果需要,则为对象初始化零值
// Initialize object (if nonzero size and need) and then the header
if (need_zero ) {
HeapWord* to_zero = (HeapWord*) result + sizeof(oopDesc) / oopSize;
obj_size -= sizeof(oopDesc) / oopSize;
if (obj_size > 0 ) {
memset(to_zero, 0, obj_size * HeapWordSize);
}
}
if (UseBiasedLocking) {//根据是否启用偏向锁来设置对象头信息
result->set_mark(ik->prototype_header());
} else {
result->set_mark(markOopDesc::prototype());
}
result->set_klass_gap(0);
result->set_klass(k_entry);
SET_STACK_OBJECT(result, 0);
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1);
}
}
}
// Slow case allocation
CALL_VM(InterpreterRuntime::_new(THREAD, METHOD->constants(), index),
handle_exception);
//将对象引用入栈,继续执行下一条指令
SET_STACK_OBJECT(THREAD->vm_result(), 0);
THREAD->set_vm_result(NULL);
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1);
}
2.2 对象的内存布局
在 HotSpot 虚拟机中,对象在内存中存储的布局可以分为 3 块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
HotSpot 虚拟机的对象头包括两部分信息:
- Mark Word - 用于存储对象自身的运行时数据,如哈希码、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等,这部分的数据的长度在 32 位和 64 位的虚拟机(未开启压缩指针)中分别为 32bit 和 64bit。对象需要存储的运行时数据很多,其实已经超出了 32 位、64 位 Bitmap 结构所能记录的限度了,但是对象头信息是与对象自身定义的数据的概述,所以 Mark Word 被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。以 32 位的 HotSpot 虚拟机为例:
| 存储内容 | 标志位 | 状态 |
|---|---|---|
| 对象哈希码、对象分代年龄 | 01 | 未锁定 |
| 指向锁记录的指针 | 00 | 轻量级锁定 |
| 指向重量级锁的指针 | 10 | 重量级锁定 |
| 空,不需要记录的信息 | 11 | GC 标记 |
| 偏向指针、偏向时间戳、对象分代年龄 | 01 | 可偏向 |
- 类型指针 - 即对象指向它的类元数据的指针,虚拟机会通过这个指针来确定这个对象是哪个类的实例。并不是所有的虚拟机实现都必须在对象数据上保留类型指针,换句话说,查找对象的元数据信息并不一定要经过对象本身。另外,如果对象是一个 java 数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通 java 对象的元数据信息确定 java 对象的大小,但是从数组的元数据中无法确定数组的大小。
markOop.hpp 中的代码注释部分,描述了 32 bit 下 Mark Word 的存储状态:
// Bit-format of an object header (most significant first, big endian layout below):
//
// 32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。这部分的存储顺序会受到虚拟机分配策略参数(FieldAllocationStyle)和字段在 java 源码中定义顺序的影响。HotSpot 虚拟机默认的分配策略为 longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Pointers),从分配策略中可以看出,相同宽度的字段总是被分配到一起。在满足这个前提条件的情况下,在父类中定义的变量会出现在子类之前。如果 CompactFields 参数值为 true(默认为true),那么子类之中较窄的变量也可能会插入到父类变量的空隙之中。
第三部分的对齐填充不是必然存在的,它仅仅起着占位符的作用。因为 HotSpot VM 的自动内存管理要求对象的起始地址必须是 8 字节的整数倍,所以对象的大小必须是 8 字节的整数倍。而对象头部分刚好是 8 字节的倍数(1 倍或 2 倍),所以当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
2.3 对象的访问定位
java 程序需要通过栈上的 reference 数据来操作堆上的具体对象。由于 reference
类型在 java 虚拟机规范中只规定了一个指向对象的引用,并没有定义这个引用通过何种方式去定位、访问堆中的对象的具体位置,所以对象访问方式也是取决于虚拟机的实现而定的。目前主流的访问方式有使用句柄和直接指针两种方式。
- 句柄 - java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息。
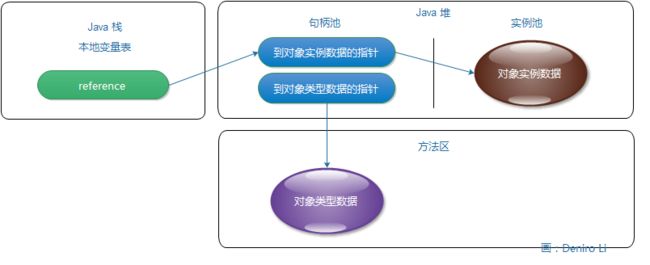
- 直接指针 - 在 reference 中存储的是对象地址。

这两种对象访问方式各有优势,使用句柄来访问的最大好处就是 reference 中存储的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而 reference 中存储的对象的句柄地址不需要修改。
使用直接指针访问方式的最大好处就是速度更快,它节省了一次指针定位的时间开销。由于对象的访问在 Java 中非常频繁,因此此类开销积少成多后也是一项非常可观的执行成本。就 Sun HotSpot 而言,它是使用直接指针来访问对象的,但从整个软件开发范围来看,各种语言或框架使用句柄来访问的情况也十分常见。
3 OutOfMemoryError 异常
这里将通过若干实例来验证 OutOfMemoryError 异常发生的场景,并会初步介绍几个与内存相关的最基本的虚拟机参数。
我们的目的有两个:第一,通过代码验证 Java 虚拟机规范中描述的各个运行时区域存储的内容;第二,希望开发者在工作中遇到实际的内存溢出异常时,能根据异 常的信息快速判断是哪个区域出现内存溢出,知道什么样的代码可能会导致这些区域的内存溢出,以及出现这些异常后该如何处理。
下面代码的开头都注释了执行时所需要设置的虚拟机启动参数(“VM options” 后面跟着的参数),这些参数对实验的结果有直接影响,所以调试代码时,不要忘了哦。
下面的代码都是基于 JDK1.8 运行的,对于不同公司的不同版本的虚拟机 ,参数和程序运行的结果可能会有所差别。
3.1 Java 堆溢出
Java 堆用于存储对象实例,只要不断地创建对象,并且保证 GC Roots 到对象之间有可达路径来避免垃圾回收机制清除这些对象,那么在对象数量到达最大堆的容量限制后就会产生内存溢出异常。
public class HeapOOM {
static class OOMObject {
}
public static void main(String[] args) {
List list = new ArrayList();
while (true) {
list.add(new OOMObject());
}
}
}
VM options:
-Xms20m -Xmx20m -XX:+HeapDumpOnOutOfMemoryError
VM 参数限制了 Java 堆的大小为 20MB,并且不可扩展(将堆的最小值 -Xms 参数与最大值 -Xmx 参数设置为一样即可避免堆自动扩展),通过参数-XX:+HeapDumpOnOutOfMemoryError 可以让虚拟机在出现内存溢出异常时 Dump 出当前的内存堆转储快照以便事后进行分析。
运行结果:
java.lang.OutOfMemoryError: Java heap space
Dumping heap to java_pid8872.hprof ...
Heap dump file created [28637555 bytes in 0.153 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3210)
at java.util.Arrays.copyOf(Arrays.java:3181)
at java.util.ArrayList.grow(ArrayList.java:261)
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:235)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:227)
at java.util.ArrayList.add(ArrayList.java:458)
at net.deniro.jvm.HeapOOM.main(HeapOOM.java:20)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:140)
Java 堆内存的 OOM 异常是实际应用中常见的内存溢出异常。当出现 Java 堆内存溢出时 ,异常堆栈信息 “java.lang.OutOfMemoryError” 会跟着进一步提示“Java heap space”。
要解决这个 Java 堆异常,一般的手段是先通过内存映像分析工具(如 Eclipse Memory Analyzer ) 对 Dump 出来的堆转储快照进行分析,重点是确认内存中的对象是否是必要的,也就是要先分清楚到底是出现了内存泄漏(Memory Leak) 还是内存溢出(Memory Overflow) 。 下面显示了使用 Eclipse Memory Analyzer 打开的堆转储快照文件。
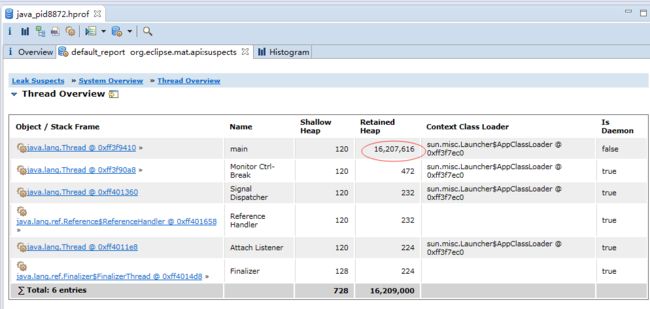
如果是内存泄露,可进一步通过工具查看泄露对象到 GC Roots 的引用链。这样就能找到泄露对象是通过怎样的路径与 GC Roots 相关联并导致垃圾收集器无法自动回收它们的问题所在咯。掌握了泄露对象的类型信息及 GC Roots 引用链的信息,就可以比较准确地定位出泄露代码的位置。
如果不存在泄露,即内存中的对象确实都还必须存活着,那就应当检查虛拟机的堆参数(-Xmx与-Xms ) 与机器物理内存比较,看是否还可以调大,从代码上检查是否存在某些对象生命周期过长、持有状态时间过长的情况,尝试减少程序运行期的内存消耗。
以上是处理 Java 堆内存问题的基本思路,处理这些问题所需要的知识、工具与经验以后我们会说到哦O(∩_∩)O~。
3.2 虚拟机栈和本地方法栈溢出
由于在 HotSpot 虚拟机中并不区分虚拟机栈和本地方法栈,因此,对于 HotSpot 来 说,虽然 -Xoss 参数 (设置本地方法栈大小)存在,但实际上是无效的,栈容量只由 -Xss 参数设定。 关于虚拟机栈和本地方法栈,在 Java 虚拟机规范中描述了两种异常:
- 如果线程请求的栈深度大于虚拟机所允许的最大深度,将拋出 StackOverflowError 异常。
- 如果虚拟机在扩展栈时无法申请到足够的内存空间,则拋出 OutOMemoryError 异常。
这里把异常分成两种情况,看似更加严谨,但却存在着一些互相重叠的地方:当栈空间无法继续分配时,到底是内存太小,还是已使用的栈空间太大,其本质上只不过是对同一件事情的两方面的描述而已。
使用 -Xss 参数减少了栈内存容量。结果会拋出 StackOverflowError 异常,异常出现时输出的堆栈深度相应缩小。
VM options: -Xss128k
public class JavaVMStackSOF {
private int stackLength = 1;//栈深度
public void stackLeak() {
stackLength++;
stackLeak();
}
public static void main(String[] args) throws Throwable {
JavaVMStackSOF oom = new JavaVMStackSOF();
try {
oom.stackLeak();
} catch (Throwable e) {
System.out.println("stack length:" + oom.stackLength);
throw e;
}
}
}
测试结果:
stack length:977
Exception in thread "main" java.lang.StackOverflowError
at net.deniro.jvm.JavaVMStackSOF.stackLeak(JavaVMStackSOF.java:14)
at net.deniro.jvm.JavaVMStackSOF.stackLeak(JavaVMStackSOF.java:15)
at net.deniro.jvm.JavaVMStackSOF.stackLeak(JavaVMStackSOF.java:15)
结果表明:在单个线程下,无论是由于栈帧(一个方法中包含的本地变量数)太大还是虚拟机栈容量(-Xss 参数减少每个线程栈内存容量)太小,当内存无法分配的时,虚拟机拋出的都是 StackOverflowError 异常。
如果测试时不限于单线程,通过不断地建立线程的方式倒是可以产生内存溢出异常。但是这样产生的内存溢出异常与栈空间是否足够大并不存在任何联系,或者准确地说,在这种情况下,为每个线程的栈分配的内存越大,反而越容易产生内存溢出异常。
原因不难理解,操作系统分配给每个进程的内存是有限制的,譬如 32 位的Windows 限制为 2GB。虚拟机提供了参数来控制 Java 堆和方法区的这两部分内存的最大值。剩余的内存为 2GB ( 操作系统限制)减去 Xmx ( 最大堆容量),再减去MaxPermSize (最大方法区容量),程序计数器消耗内存很小,可以忽略掉。如果虚拟机进程本身耗费的内存不计算在内,剩下的内存就由虚拟机栈和本地方法栈 “瓜分” 了。每个线程分配到的栈容量越大,可以建立的线程数量自然就越少,建立线程时也就越容易把剩下的内存耗尽。
因此开发者在开发多线程的应用时要特别注意,出现 StackOverflowError 异常时有错误的堆栈信息被打印出来,相对来说,比较容易找到问题的所在。而且 ,如果使用虚拟机默认参数,栈深度在大多数情况下(因为每个方法压入栈的帧大小并不是一样的)达到 1000〜2000 完全没有问题,对于正常的方法调用(包括递归),这个深度应该完全够用了。但是 ,如果是建立了过多的线程而导致的内存溢出,在不能减少线程数或者更换 64 位虚拟机的情况下,就只能通过减少最大堆和减少栈容量来换取更多的线程。如果没有这方面的处理经验,这种通过 “减少内存” 的手段来解决内存溢出的方式会比较难以想到哦O(∩_∩)O~
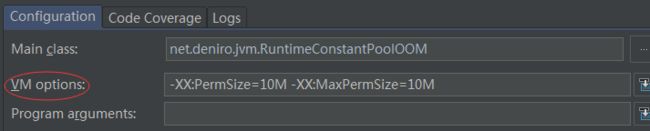
3.3 方法区和运行时常量池溢出
由于运行时常量池是方法区的一部分,因此这两个区域的溢出测试就放在一起进行。前面提到 JDK 1.7 开始逐步 “去永久代” ,在此就以测试代码观察一下这件事对程序的实际影响。
VM options: -XX:PermSize=10M -XX:MaxPermSize=10M
public class RuntimeConstantPoolOOM {
public static void main(String[] args) {
//list 中保持着常量池的引用,避免 Full GC 回收常量池行为
List list = new ArrayList();
//10MB 的 PermSize 在 integer 范围内可以产生内存溢出异常咯
int i = 0;
while (true) {
list.add(String.valueOf(i++).intern());
}
}
}
在 JDK1.8 中,while 循环将一直进行下去。而在 JDK 1.6 及之前的版本中,由于常量池分配在永久代内,我们可以通过 -XX : PermSize 和 -XX : MaxPermSize 限制方法区大小,从而间接限制其中的常量池容量。
我们再看一段代码:
public class RuntimeConstantPoolOOM2 {
public static void main(String[] args) {
String str1=new StringBuilder("de").append("niro").toString();
System.out.println(str1.intern()==str1);
String str2=new StringBuilder("ja").append("va").toString();
System.out.println(str2.intern()==str2);
}
}
输出结果:
true
false
这段代码在 JDK 1.6 中运行,会得到两个 false,而在JDK 1.7及之后的版本(这里是 JDK 1.8)中运行,会得到一个 true 和一个 false。产生差异的原因是:在JDK 1.6 中 , intern ( ) 方法会把首次遇到的字符串实例复制到永久代中,返回的也是永久代中这个字符串实例的引用,而由 StringBuilder 创建的字符串实例在 Java 堆上,所以必然不是同一个引用,所以会返回 false。而JDK 1.7 (以及部分其他虚拟机 ,例如JRockit) 的 intern ( ) 实现不会再复制实例,只是在常量池中记录首次出现的实例引用,因此 intern( ) 返回的引用和由 StringBuilder()创建的那个字符串实例是同一个。对 str2 比较返回 false 是因为 “java” 这个字符串在执行 StringBuilder.toString ( ) 之前已经出现过,字符串常量池中已经有它的引用了,不符合 “首次出现” 的原则 ,而 “deniro” 这个字符串则是首次出现的,所以返回 true。
3.4 本机直接内存溢出
DirectMemory 容量可通过 -XX : MaxDirectMemorySize 指定,如果不指定,则默认与 Java 堆最大值(-Xmx指定)一样 ,下面的代码越过了 DirectByteBuffer 类 ,直接通过反射获取 Unsafe 实例进行内存分配【Unsafe 类的 getUnsafe ( ) 方法限制了只有引导类加载器才会返回实例,也就是设计者希望只有 rt.jar 中的类才能使用Unsafe 的功能】。因为,虽然使用 DirectByteBuffer 分配内存也会拋出内存溢出异常,但它抛出异常时并没有真正向操作系统申请分配内存,而是通过计算得知内存无法分配,于是手动拋出异常,真正申请分配内存的方法 unsafe.allocateMemory ( ) 。
VM options: -Xmx20M -XX:MaxDirectMemorySize=10M
public class DirectMemoryOOM {
public static final int _1MB = 1024 * 1024;
public static void main(String[] args) throws IllegalAccessException {
Field unsafeField = Unsafe.class.getDeclaredFields()[0];
unsafeField.setAccessible(true);
Unsafe unsafe = (Unsafe) unsafeField.get(null);
while (true) {
unsafe.allocateMemory(_1MB);
}
}
}
运行结果:
Exception in thread "main" java.lang.OutOfMemoryError
at sun.misc.Unsafe.allocateMemory(Native Method)
at net.deniro.jvm.DirectMemoryOOM.main(DirectMemoryOOM.java:21)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:140)
由于 DirectMemory 导致的内存溢出,一个明显的特征是在 Heap Dump 文件中不会看见明显的异常,如果我们发现在 OOM 之后的 Dump文件很小,而程序中又直接或间接使用了 NIO,那就可以考虑检查一下是不是这方面的原因啦O(∩_∩)O~