一、大数据技术体系

大数据应用领域
互联网领域:搜索引擎、推荐系统、广告系统
电商领域:用户画像、推荐系统、用户行为分析
医疗领域:流行病预测、病情分析
视频领域:用户标签系统、视频分析、广告系统
金融领域:风控系统、欺诈分析
二、如何学习大数据(老师建议)
1.良好的自主学习能力和动手能力
2.系统了解大数据生态系统技术框架
3.找到学习切入点,不断拓展知识的广度(大数据平台开发、数据分析)
4.抓住一个技术方向,不断深入研究,增加知识结构的深度
5.主动学习探索新知识
6.定期知识梳理
三、大数据必备技能(重点)

四、大数据就业方向
1、大数据分析工程师
2、大数据平台开发工程师
3、大数据运维工程师
4、大数据算法工程师
5、大数据内核开发工程师
五、Zookeeper设计原理
1、分布式系统概念:是一个硬件或软件组件分布在不同的网络计算机上,彼此之间通过消息传递进行通信和协调的系统。《分布式系统概念与设计》
2、分布式特点:分布性、对等性、并发性、缺乏全局时钟、故障总是会发生
3、为什么选择Zookeeper? 开源免费、高效、可靠的解决数据一致性问题、简单易用、工业界大型分布式系统广泛应用。
4、Zookeeper 概念:一个开源的针对大型分布式系统的可靠协调系统。
提供的功能包括:发布/订阅,分布式协调/通知,配置管理,集群管理,主从协调,分布式锁等。
5、Zookeeper特性:最终一致性、顺序性、可靠性、实时性、原子性、单一视图

6.Zookeeper的架构
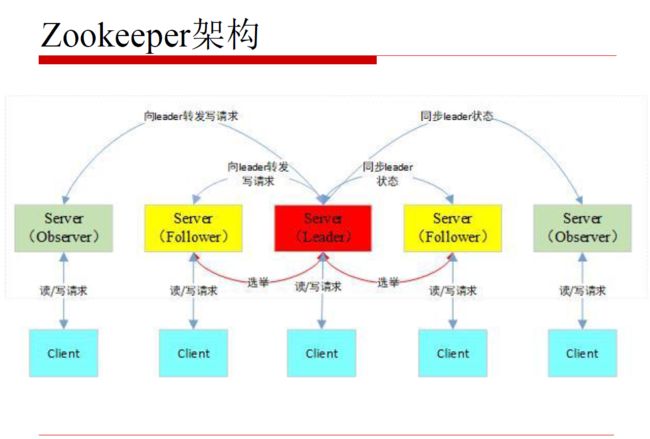
注意:如果leader挂掉了会从follwer里面选取,不会从观察者(Observer)中选取

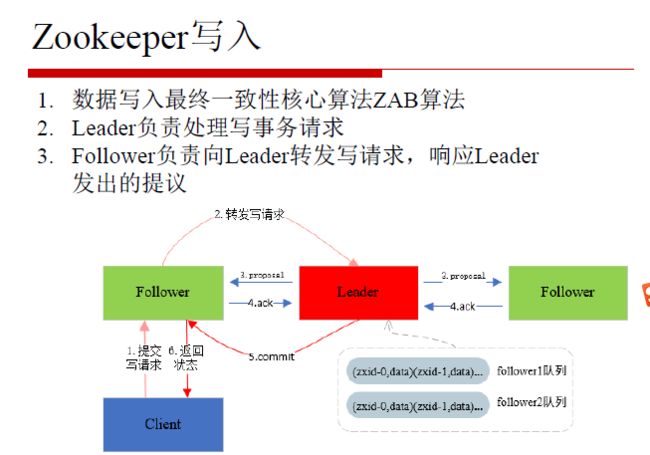
7.Zookeeper写入
(1)数据写入最终一致性核心算法:ZAB算法
(2)Leader负责处理写事务请求(收到半数以上的Follwer的请求,提交给Follwer,Leader会自身也提交请求)
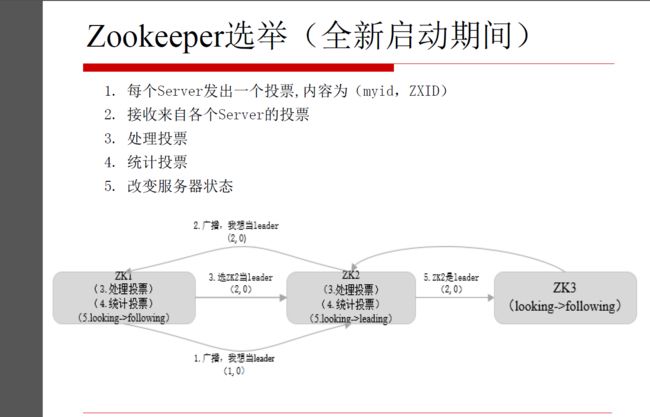
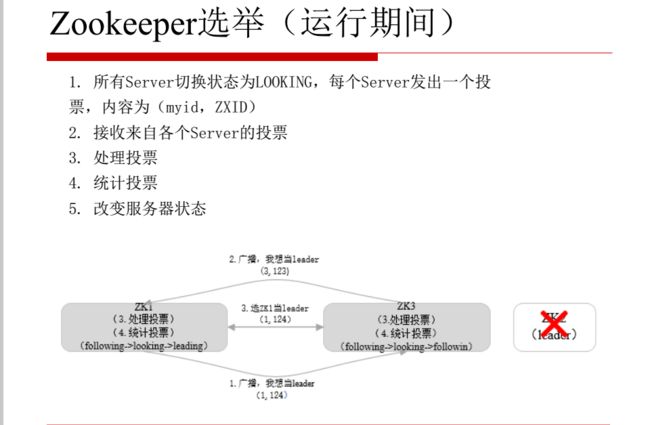
8.Zookeeper选举
服务器四种状态:looking/leading/follwing/observer


9.Znode节点类型:不允许在临时节点下创建

Znode版本号,初始为0每次操作一次+1.

悲观锁一般解决并发问题,要求对数据从头到尾都加锁。排他性
乐观锁一般用于并发不大,数据冲突不强烈的。事务请求,同时并发会回滚操作。
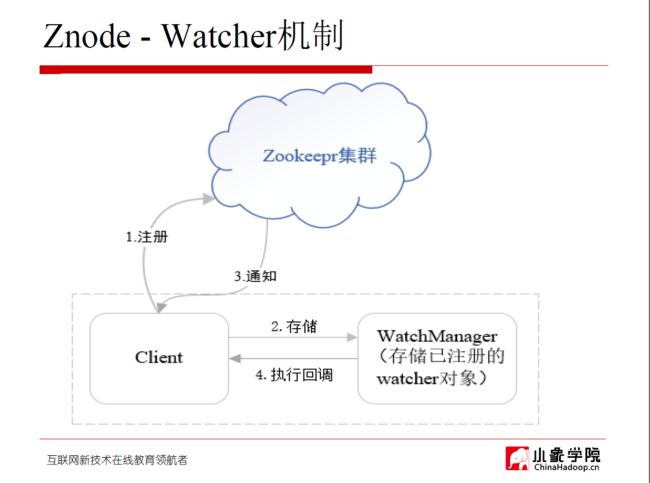
六、重要概念解答(老师解答)
1、心跳的意思是,从节点周期性的向leader发送消息,比如2秒钟发送一次消息,这种有规律的通信就叫做心跳
2、znode是zookeeper中的一个数据节点,znode下还可以创建子znode,可以理解为文件夹的构造,一个文件夹下可以有子文件夹或者子文件
3、整个集群会选举出一个leader,这个leader负责处理客户端的事务请求,事务请求包括znode的创建、修改、删除等,follower负责处理客户端的读请求。
4、维护Znode:当集群中的任何一个follower节点接收到客户端的事务请求,都会转发给leader,也就是说整个集群只有leader可以处理事务请求,其他角色的节点都不能处理,当leader处理事务请求的时候,就要向整个集群广播一个提议,这个提议的意思就是告诉follower你们要创建/修改/删除一个znode,然后follower接收到leader的提议之后,就会做相应的操作,操作完成告诉leader完成了。
当leader接收到集群中的大多数follower的成功操作的回复之后,这里的大多数指的是超过集群机器数量的一半。
当收到大多数follower的回复之后,leader就认为这次事务被成功处理了,然后再向集群通知所有的follower提交事务,最后会返回给客户端一个事务被成功处理的状态。
如果有落后的follower,这些落后的follower也会从leader同步状态,保持与leader的状态一致。
七、Zookeeper安装配置常见问题及解决方法
问题一如下图:
通过ssh-copy-id命令将node01这台机器root用户的公钥文件(id_rsa.pub)文件内容拷贝到node02和node03两台机器时报错
问题分析:路径错误
scp -r /home/hadoop/apps/zookeeper-3.4.10 hadoop@node02:/home/hadoop/apps
问题解决:按照最新安装文档14步骤操作
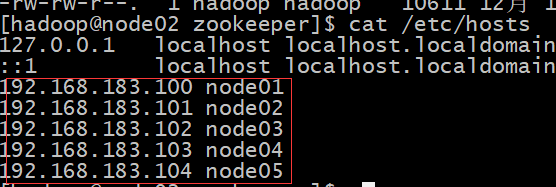
问题二如下图:

解决办法:要在所有机器的/etc/hosts中配置ip和主机名称的映射关系:如下
问题三如下图:

问题分析:配置的root用户的免密码登录,然后使用的hadoop的用户拷贝,导致提示输入免密
解决方法:如果用hadoop用户拷贝,要配置hadoop用户的ssh免密码登录。配置root免密登录不代表所有用户都可以免密码登录。
问题四如下图:

问题分析:配置好后使用root用户启动成功了zookeeper,导致hadoop用户无权限启动。
解决办法:用root用户直接去data目录下删除掉那个pid文件用hadoop用户启动就好了。