Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取前程无忧招聘数据
2.主题式网络爬虫爬取的内容与数据特征分析
爬取相关岗位的招聘信息及各岗位在各个城市的分布状况
爬取内容:职位名,公司名,工作地点,薪资
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:1.使用requests库来实现
2.获取网页的HTML,获取需要的征文内容,调用获取源码
技术难点:数据爬取的时候会出现错误
生成图片难度大
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征


一共有708页,爬取了前五页数据。爬取数据是静态。
2.Htmls页面解析
我们可以看到这里列了"职位名"、"公司名"、"工作地点"、"薪资"等,我们就可以把这些关键信息爬取下来。确定了需求,下一步我们就审查元素找到我们所需信息所在的标签,再写一个正则表达式把元素筛选出来就可以了!
这样就有一个正则表达式:
reg = re.compile(r'class="t1 ">.*?(.*?).*?(.*?)',re.S)

3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)


三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
import urllib.request
import re
import pandas as pd
#职位名
work = []
#公司名
company = []
#工作地点
address = []
#薪资
salary = []
def get_html(page): #获取网页的HTML
url = 'http://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=000000%2C00&district=000000&funtype=0000&industrytype=00&issuedate=9&providesalary=99&keyword=Python&keywordtype=2&curr_page=2&lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&list_type=0&fromType=14&dibiaoid=0&confirmdate=9'.format(page)
html = urllib.request.urlopen(url).read()
html = html.decode('gbk')
return html
def get_you_want(html): #获取需要的征文内容
reg = re.compile(r'class="t1 ">.*?(.*?).*?(.*?)',re.S)
you_want = re.findall(reg,html)
return you_want
for get_page in range(1,6):
htmls = get_html(get_page) #调用获取源码
for i in get_you_want(htmls):
work.append(i[0])
company.append(i[1])
address.append(i[2])
salary.append(i[3])
column_list = ["职位名","公司名","工作地点","薪资"]
data = list(zip(work,company,address,salary))
df = pd.DataFrame(data,columns = column_list,index = range(1,len(work)+1))
print(df)
df.to_csv("./前程无忧.csv")

2.对数据进行清洗和处理
输入前五行数据
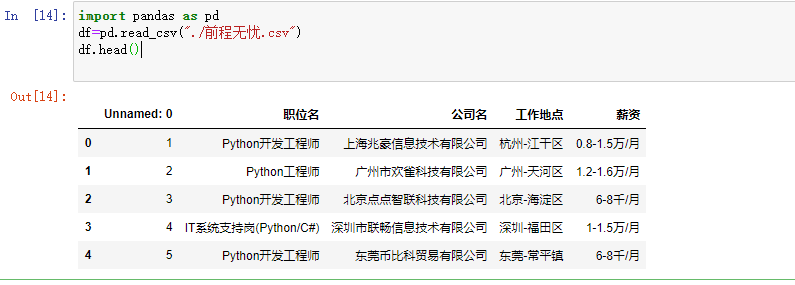
删除无效列

查找重复值
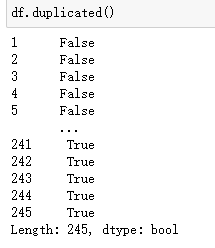
删除重复值

空值查询
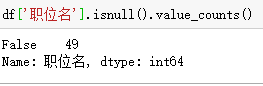
数据异常处理

3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
import seaborn as sns sns.countplot(df['薪资'])
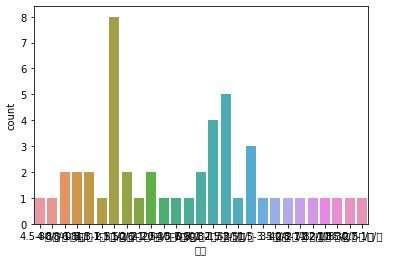
sns.load_dataset(df['薪资'])
5.数据持久化

6.附完整程序代码
import urllib.request
import re
import pandas as pd
#职位名
work = []
#公司名
company = []
#工作地点
address = [] #薪资 salary = [] def get_html(page): #获取网页的HTML url = 'http://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=000000%2C00&district=000000&funtype=0000&industrytype=00&issuedate=9&providesalary=99&keyword=Python&keywordtype=2&curr_page=2&lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&list_type=0&fromType=14&dibiaoid=0&confirmdate=9'.format(page) html = urllib.request.urlopen(url).read() html = html.decode('gbk') return html def get_you_want(html): #获取需要的征文内容 reg = re.compile(r'class="t1 ">.*?(.*?).*?(.*?)',re.S) you_want = re.findall(reg,html) return you_want for get_page in range(1,6): htmls = get_html(get_page) #调用获取源码 for i in get_you_want(htmls): work.append(i[0]) company.append(i[1]) address.append(i[2]) salary.append(i[3]) column_list = ["职位名","公司名","工作地点","薪资"] data = list(zip(work,company,address,salary)) df = pd.DataFrame(data,columns = column_list,index = range(1,len(work)+1)) print(df) df.to_csv("./前程无忧.csv")
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
在一线城市对岗位的需求量大,薪资也高,同理,在偏远地区的岗位需求小,薪资少。
2.对本次程序设计任务完成的情况做一个简单的小结。
在爬取数据的时候时常会遇到困难,但都克服下来了。这个项目做下来,自己也了解了一些爬虫的技巧。收获颇多。