上半部分:海藻!海藻!—R实战案例一(上)
本案例的目的是预测140个水样中7种海藻的出现频率,这部分是用多元线性回归模型和回归树模型分别进行预测。
首先进行多远线性回归,该模型给出一个有关目标变量,和解释变量关系的线性函数
#预测海藻a1出现的频率,.代表数据框中除了a1外的变量。
lm.a1<-lm(a1~.,data=clean.algae[,1:12])
summary(lm.a1)
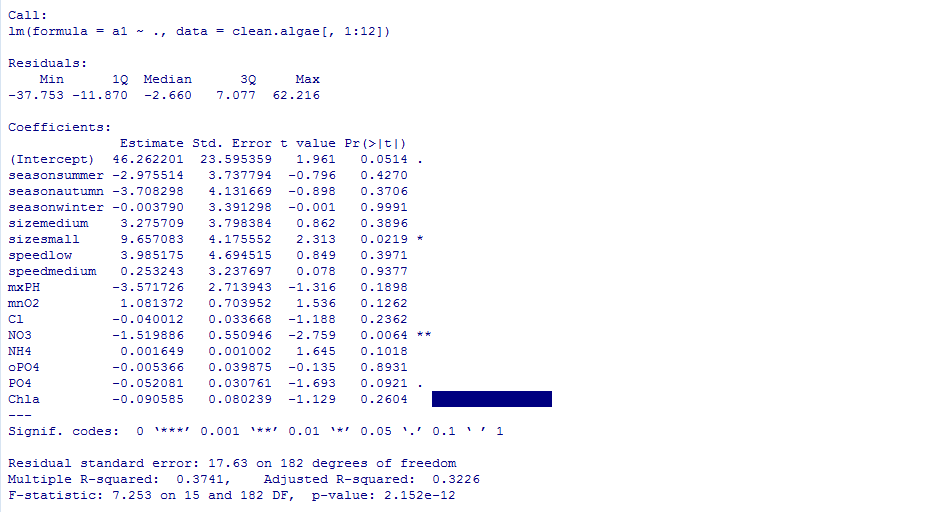
该模型解释的方差比例(R-squared)表明模型与数据的吻合度。越接近于1越好。此处为0.322,还不是很理想,所以需要精简回归模型。
首先用anova函数提供模型拟合的方差序贯分析。
anova(lm.a1)
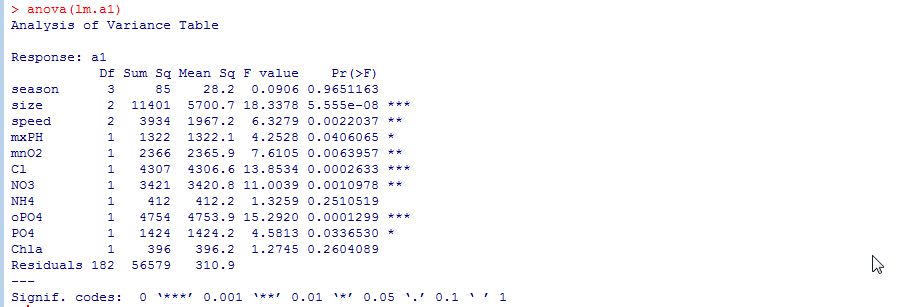
从图中可见,season对减少模型拟合误差的贡献最小,将其删除。然后再做一次线性回归模型。
lm2.a1<-update(lm.a1,.~.-season)
summary(lm2.a1)
anova(lm.a1,lm2.a1)
此处结果略,R平方是0.328,还是不理想。所以继续用anova对两个模型进行正式的比较,使用两个模型作为参数。

尽管误差平方和减少了(-449),但显著性只有0.695,说明两个模型不同的可能性为30%,应该再次消元。使用step向后消元法。
final.lm<-step(lm.a1)
summary(final.lm)
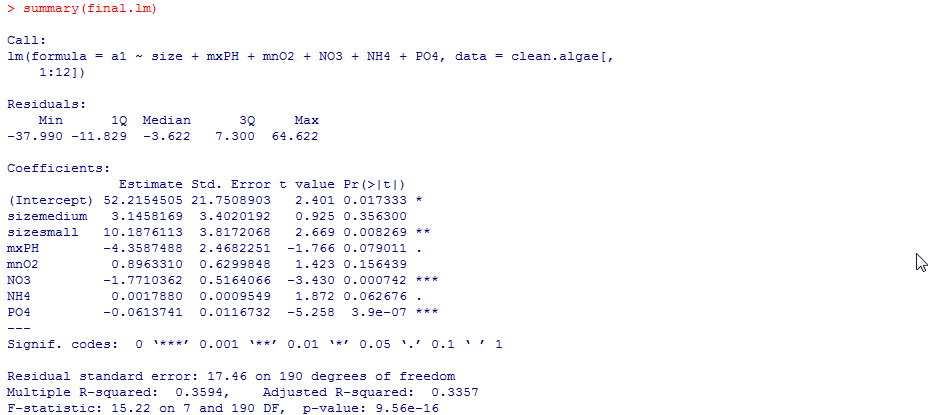
最后的R平方仍然不理想,说明在此案例,应用线性模型并不合适。
接下来运用另一种模型算法:回归树来预测。回归树是对某些解释变量分层次的逻辑测试,基于树的模型自动筛选相关的变量。
library(rpart)
rt.a1<-rpart(a1~.,data=algae[,1:12])
rt.a1
prettyTree(rt.a1)
prettyTree主要是可视化,图形如下:
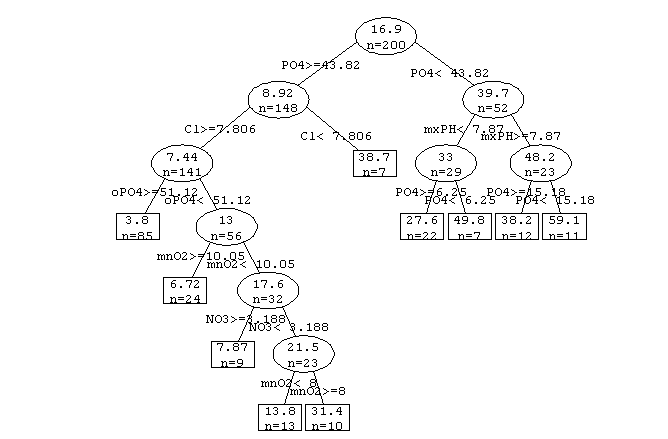
此外,可以用复杂度损失修剪的方法,估计树节点的参数值cp,以达到预测的准确性和树大小的折中。然后利用prune来剪枝。(这里我不是很理解,先这么看着吧)
printcp(rt.a1)
rt2.a1<-prune(rt.a1,cp=0.08)
rt2.a1
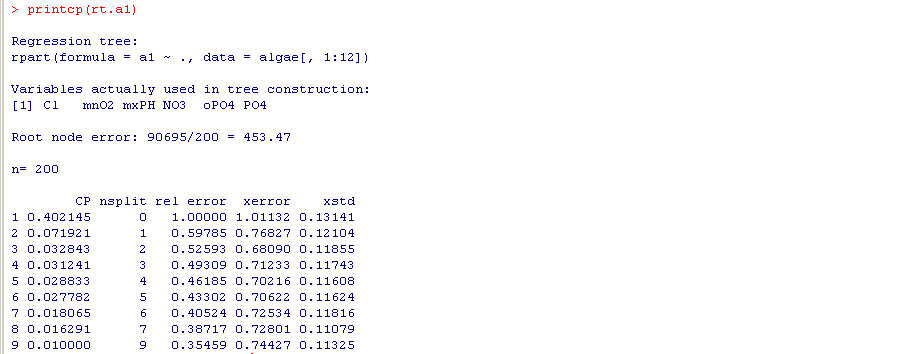

rpartXse函数是可以自动运行这个过程,但是得到的图形很奇怪。(下右图)
rt.a1<-rpartXse(a1~.,data=algae[,1:12])
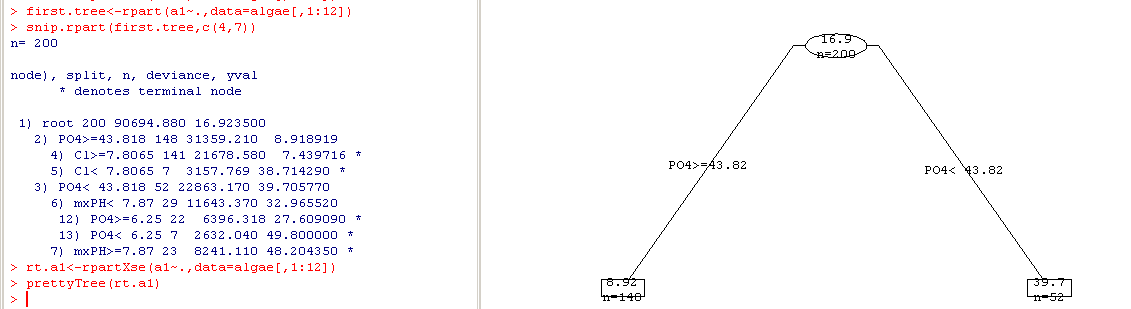
snip.rpart函数是交互的对树进行修剪(结果上左图)
first.tree<-rpart(a1~.,data=algae[,1:12])
snip.rpart(first.tree,c(4,7))
或者采用直接点击的方式修剪。(不过好像点击了也没有什么变化...)
prettyTree(first.tree)
snip.rpart(first.tree)
简而言之,这部分主要讲了线性和回归树,回归树那里常用的语句还是rpart。看其他案例,大多数也只用rpart。虽然语句很简单,也几乎不用输入参数,但内中含义很复杂啊。
最后一部分讲模型的评价和选择~~~
第二部分完整代码如下,不好用的语句我直接废掉了:
#线性模型
lm.a1<-lm(a1~.,data=clean.algae[,1:12])
summary(lm.a1)
anova(lm.a1)
lm2.a1<-update(lm.a1,.~.-season)
summary(lm2.a1)
anova(lm.a1,lm2.a1)
final.lm<-step(lm.a1)
summary(final.lm)
#回归树
library(rpart)
rt.a1<-rpart(a1~.,data=algae[,1:12])
rt.a1
prettyTree(rt.a1)
printcp(rt.a1)
rt2.a1<-prune(rt.a1,cp=0.08)
rt2.a1
#rt.a1<-rpartXse(a1~.,data=algae[,1:12])
first.tree<-rpart(a1~.,data=algae[,1:12])
snip.rpart(first.tree,c(4,7))
#prettyTree(first.tree)
#snip.rpart(first.tree)