笔记来自《统计学习方法》第四章。
大体分析
朴素贝叶斯的优缺点
优点:
朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。
NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。
缺点:
理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的(可以考虑用聚类算法先将相关性较大的属性聚类),这给NBC模型的正确分类带来了一定影响。在属性个数比较多或者属性之间相关性较大时,NBC模型的分类效率比不上决策树模型。而在属性相关性较小时,NBC模型的性能最为良好。
需要知道先验概率。
分类决策存在错误率
朴素贝叶斯
联合概率分布
联合概率分布可以由先验概率和条件概率来得到:
也就是说,只要知道了先验概率分布和条件概率分布,就可以算出联合概率分布,而先验概率分布和条件概率分布可以由极大似然估计或者贝叶斯估计得出。
极大似然估计
极大似然估计就是通过事件发生的频率来估计事件发生的概率:
贝叶斯估计
由极大似然估计得到的概率,如果概率值为零的话,会影响到后验概率的计算(分母不能为零)
那么,在随机变量各个取值的频数上赋予一个正数,就可以避免这个问题:
在这里,时为极大似然估计,时是拉普拉斯平滑,其中的一些参数是,,
朴素贝叶斯法
有了计算各个概率的方法之后,我们就可以去计算每一个,然后取值最大的那个概率对应的作为预测的结果。
在学习的时候,我们需要模型去学习一个机制,使得能够最大,这就确保了,当系统接收到一个输入样本的时候,系统最可能给出正确的分类答案,即。
有极大似然估计或者贝叶斯估计,我们可以计算出和,那么我们怎么才能得到呢?
由贝叶斯公式(或者贝叶斯定理),我们有:
而我们知道,任何一个输入的样本都可以被表示为一个n维向量,那么条件概率分布:
而在朴素贝叶斯法中,对条件概率分布做了条件独立性的假设,那么就有:
于是乎:
省去不会变化的分母,朴素贝叶斯分类器可以表示为:
也就是说,找到一个,使得上式最大化即可,这个就是分类器预测的结果。
例题
书中给出了两个例子:参数未修正、参数修正,两种场景的估计,都是三步走,一样的套路。
问题描述:

参数未修正:
第一步:类别信息
第二步:不同类别的特征信息
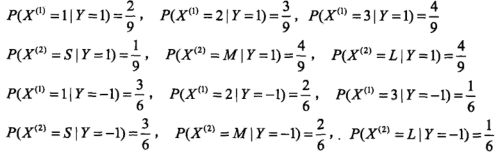
第三步:不同类别概率估计
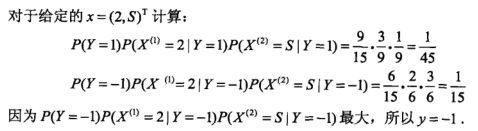
参数修正:这里
第一步:类别信息
第二步:不同类别的特征信息

第三步:不同类别概率估计

Python 实现
import numpy as np
#构造NB分类器
def Train(X_train, Y_train, feature):
global class_num,label
class_num = 2 #分类数目
label = [1, -1] #分类标签
feature_len = 3 #特征长度
#构造3×2的列表
feature = [[1, 'S'],
[2, 'M'],
[3, 'L']]
prior_probability = np.zeros(class_num) # 初始化先验概率
conditional_probability = np.zeros((class_num,feature_len,2)) # 初始化条件概率
positive_count = 0 #统计正类
negative_count = 0 #统计负类
for i in range(len(Y_train)):
if Y_train[i] == 1:
positive_count += 1
else:
negative_count += 1
prior_probability[0] = positive_count / len(Y_train) #求得正类的先验概率
prior_probability[1] = negative_count / len(Y_train) #求得负类的先验概率
'''
conditional_probability是一个2*3*2的三维列表,第一维是类别分类,第二维和第三维是一个3*2的特征分类
'''
#分为两个类别
for i in range(class_num):
#对特征按行遍历
for j in range(feature_len):
#遍历数据集,并依次做判断
for k in range(len(Y_train)):
if Y_train[k] == label[i]: #相同类别
if X_train[k][0] == feature[j][0]:
conditional_probability[i][j][0] += 1
if X_train[k][1] == feature[j][1]:
conditional_probability[i][j][1] += 1
class_label_num = [positive_count, negative_count] #存放各类型的数目
for i in range(class_num):
for j in range(feature_len):
conditional_probability[i][j][0] = conditional_probability[i][j][0] / class_label_num[i] #求得i类j行第一个特征的条件概率
conditional_probability[i][j][1] = conditional_probability[i][j][1] / class_label_num[i] #求得i类j行第二个特征的条件概率
return prior_probability,conditional_probability
#给定数据进行分类
def Predict(testset, prior_probability, conditional_probability, feature):
result = np.zeros(len(label))
for i in range(class_num):
for j in range(len(feature)):
if feature[j][0] == testset[0]:
conditionalA = conditional_probability[i][j][0]
if feature[j][1] == testset[1]:
conditionalB = conditional_probability[i][j][1]
result[i] = conditionalA * conditionalB * prior_probability[i]
result = np.vstack([result,label])
return result
def main():
X_train = [[1, 'S'], [1, 'M'], [1, 'M'], [1, 'S'], [1, 'S'],
[2, 'S'], [2, 'M'], [2, 'M'], [2, 'L'], [2, 'L'],
[3, 'L'], [3, 'M'], [3, 'M'], [3, 'L'], [3, 'L']]
Y_train = [-1, -1, 1, 1, -1, -1, -1, 1, 1, 1, 1, 1, 1, 1, -1]
#构造3×2的列表
feature = [[1, 'S'],
[2, 'M'],
[3, 'L']]
testset = [2, 'S']
prior_probability, conditional_probability= Train(X_train, Y_train, feature)
result = Predict(testset, prior_probability, conditional_probability, feature)
print(result)
if __name__ == '__main__':
main()