
上一篇我们的基本工作已经准备完成,这篇我们说重要的安装过程。
kubernetes 相关服务安装
- 在 kubernetes 所有节点上验证 SELINUX 模式,必须保证 SELINUX 为 permissive 模式,否则 kubernetes 启动会出现各种异常。
[root@k8s-master1 yaml]# getenforcePermissive
- 在 kubernetes 所有节点上安装并启动 kubernetes 和 docker
yum install -y kubernetes-cni-0.6.0-0.x86_64 kubelet-1.10.3-0.x86_64 kubectl-1.10.3-0.x86_64 kubeadm-1.10.3-0.x86_64systemctl enable docker && systemctl start dockersystemctl enable kubelet && systemctl start kubelet
- 独立 etcd 集群部署
- 在 k8s-master1 节点上以 docker 方式启动 etcd 集群
$ docker stop etcd && docker rm etcd$ rm -rf /var/lib/etcd-cluster$ mkdir -p /var/lib/etcd-cluster$ docker run -d \--restart always \-v /etc/ssl/certs:/etc/ssl/certs \-v /var/lib/etcd-cluster:/var/lib/etcd \-p 4001:4001 \-p 2380:2380 \-p 2379:2379 \--name etcd \k8s.gcr.io/etcd-amd64:3.2.17 \etcd --name=etcd0 \--advertise-client-urls=http://172.24.12.32:2379,http://172.24.12.32:4001 \--listen-client-urls=http://0.0.0.0:2379,http://0.0.0.0:4001 \--initial-advertise-peer-urls=http://172.24.12.32:2380 \--listen-peer-urls=http://0.0.0.0:2380 \--initial-cluster-token=9477af68bbee1b9ae037d6fd9e7efefd \--initial-cluster=etcd0=http://172.24.12.32:2380,etcd1=http://172.24.12.33:2380,etcd2=http://172.24.12.34:2380 \--initial-cluster-state=new \--auto-tls \--peer-auto-tls \--data-dir=/var/lib/etcd
- 在 k8s-master2 节点上以 docker 方式启动 etcd 集群
$ docker stop etcd && docker rm etcd$ rm -rf /var/lib/etcd-cluster$ mkdir -p /var/lib/etcd-cluster$ docker run -d \--restart always \-v /etc/ssl/certs:/etc/ssl/certs \-v /var/lib/etcd-cluster:/var/lib/etcd \-p 4001:4001 \-p 2380:2380 \-p 2379:2379 \--name etcd \k8s.gcr.io/etcd-amd64:3.2.17 \etcd --name=etcd1 \--advertise-client-urls=http://172.24.12.33:2379,http://172.24.12.33:4001 \--listen-client-urls=http://0.0.0.0:2379,http://0.0.0.0:4001 \--initial-advertise-peer-urls=http://172.24.12.33:2380 \--listen-peer-urls=http://0.0.0.0:2380 \--initial-cluster-token=9477af68bbee1b9ae037d6fd9e7efefd \--initial-cluster=etcd0=http://172.24.12.32:2380,etcd1=http://172.24.12.33:2380,etcd2=http://172.24.12.34:2380 \--initial-cluster-state=new \--auto-tls \--peer-auto-tls \--data-dir=/var/lib/etcd
- 在 k8s-master3 节点上以 docker 方式启动 etcd 集群
$ docker stop etcd && docker rm etcd$ rm -rf /var/lib/etcd-cluster$ mkdir -p /var/lib/etcd-cluster$ docker run -d \--restart always \-v /etc/ssl/certs:/etc/ssl/certs \-v /var/lib/etcd-cluster:/var/lib/etcd \-p 4001:4001 \-p 2380:2380 \-p 2379:2379 \--name etcd \k8s.gcr.io/etcd-amd64:3.2.17 \etcd --name=etcd2 \--advertise-client-urls=http://172.24.12.34:2379,http://172.24.12.34:4001 \--listen-client-urls=http://0.0.0.0:2379,http://0.0.0.0:4001 \--initial-advertise-peer-urls=http://172.24.12.34:2380 \--listen-peer-urls=http://0.0.0.0:2380 \--initial-cluster-token=9477af68bbee1b9ae037d6fd9e7efefd \--initial-cluster=etcd0=http://172.24.12.32:2380,etcd1=http://172.24.12.33:2380,etcd2=http://172.24.12.34:2380 \--initial-cluster-state=new \--auto-tls \--peer-auto-tls \--data-dir=/var/lib/etcd
- 在 k8s-master1、k8s-master2、k8s-master3 上检查 etcd 启动状态
[root@k8s-master1 yaml]# docker exec -ti etcd ash/ # etcdctl member list7952c466eeed1e71: name=etcd0 peerURLs=http://172.24.12.32:2380 clientURLs=http://172.24.12.32:2379,http://172.24.12.32:4001 isLeader=falseea0f9c89ab07d1c2: name=etcd2 peerURLs=http://172.24.12.34:2380 clientURLs=http://172.24.12.34:2379,http://172.24.12.34:4001 isLeader=truefd15cb75a309af35: name=etcd1 peerURLs=http://172.24.12.33:2380 clientURLs=http://172.24.12.33:2379,http://172.24.12.33:4001 isLeader=false/ # etcdctl cluster-healthmember 7952c466eeed1e71 is healthy: got healthy result from http://172.24.12.32:2379member ea0f9c89ab07d1c2 is healthy: got healthy result from http://172.24.12.34:2379member fd15cb75a309af35 is healthy: got healthy result from http://172.24.12.33:2379cluster is healthy/ # exit
- kubeadm 初始化
- 在 k8s-master1 上修改 kubeadm-init.yaml 文件,设置 etcd.endpoints 的
${HOST_IP}为 k8s-master1、k8s-master2、k8s-master3 的 IP 地址
[root@k8s-master1 yaml]# cat kubeadm-init.yamlapiVersion: kubeadm.k8s.io/v1alpha1kind: MasterConfigurationkubernetesVersion: v1.10.3networking: podSubnet: 10.244.0.0/16apiServerCertSANs:- k8s-master1- k8s-master2- k8s-master3- 172.24.12.32- 172.24.12.33- 172.24.12.34- 172.24.12.80etcd: endpoints: - http://172.24.12.32:2379 - http://172.24.12.33:2379 - http://172.24.12.34:2379
注:如果使用kubeadm初始化集群,启动过程可能会卡在以下位置,那么可能是因为 cgroup-driver 参数与 docker 的不一致引起,如下:
[apiclient] Created API client, waiting for the control plane to become ready$ journalctl -t kubelet -S '2017-06-08' #查看日志,发现如下错误error: failed to run Kubelet: failed to create kubelet: misconfiguration: kubelet cgroup driver: "systemd"
需要修改 KUBELET_CGROUP_ARGS=--cgroup-driver=systemd 为 KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs
$ vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf#Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=systemd" Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs"
- 在 k8s-master1 上使用 kubeadm 初始化 kubernetes 集群,连接外部 etcd 集群
$ kubeadm init --config=/home/yaml/kubeadm-init.yaml
- 在 k8s-master1 上设置 kubectl 的环境变量 KUBECONFIG,连接 kubelet
$ vi ~/.bashrc export KUBECONFIG=/etc/kubernetes/admin.conf$ source ~/.bashrc
- flannel 网络组件安装
$ kubectl create -f /home/yaml/kube-flannel.yml
在 k8s-master1 上验证 kube-dns 成功启动,大概等待3分钟,验证所有 pods 的状态为 Running,验证方式见 k8s-测试dns
$ kubectl get pods --all-namespaces -o wide
- dashboard 和 heapster 组件安装
kubectl create -f /home/yaml/kubernetes-dashboard-admin.rbac.yamlkubectl create -f /home/yaml/kubernetes-dashboard.yaml
注:在 k8s-master1 上允许在 master 上部署 pod,否则 heapster 会无法部署,执行以下命令:
$ kubectl taint nodes --all node-role.kubernetes.io/master-node "k8s-master1" taintedkubectl create -f /home/yaml/heapster-rbac.yamlkubectl create -f /home/yaml/heapster.yaml
在本机上访问 dashboard 地址 http://172.24.12.32:30090,验证 heapster 成功启动,查看 Pods 的 CPU 以及 Memory 信息是否正常呈现,如下:

至此,第一台 master 成功安装,并已经完成 flannel、dashboard、heapster 的部署。
master 集群高可用设置
- 在 k8s-master1 上把 /etc/kubernetes/ 复制到 k8s-master2、k8s-master3
- 在 k8s-master2、k8s-master3 上重启 kubelet 服务,并检查 kubelet 服务状态为 active (running)
systemctl daemon-reload && systemctl restart kubelet
- 在 k8s-master2、k8s-master3 上设置 kubectl 的环境变量 KUBECONFIG,连接 kubelet
$ vi ~/.bashrcexport KUBECONFIG=/etc/kubernetes/admin.conf$ source ~/.bashrc
- 在 k8s-master2、k8s-master3 检测节点状态,发现节点已经加进来
[root@k8s-master1 yaml]# kubectl get nodes -o wide
- 在 k8s-master2、k8s-master3 上修改 kube-apiserver.yaml 的配置,
${HOST_IP}改为本机 IP
$ vi /etc/kubernetes/manifests/kube-apiserver.yaml- --advertise-address=${HOST_IP}
- 在 k8s-master2 和 k8s-master3 上的修改 kubelet.conf 设置,
${HOST_IP}改为本机 IP
$ vi /etc/kubernetes/kubelet.confserver: https://${HOST_IP}:6443
- 在 k8s-master2 和 k8s-master3 上的重启服务
$ systemctl daemon-reload && systemctl restart docker kubelet
- 创建证书
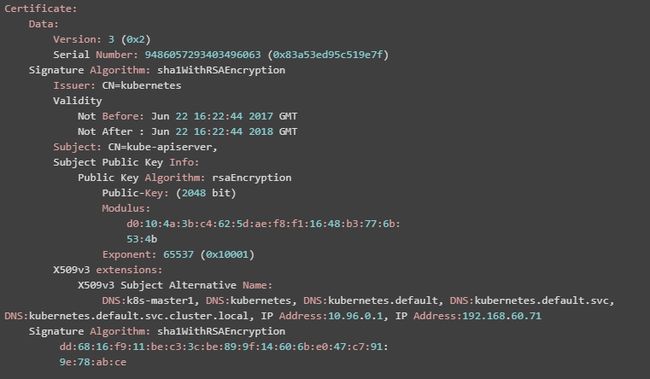
(1)在 k8s-master2 和 k8s-master3 上修改 kubelet.conf 后,由于 kubelet.conf 配置的 crt 和 key 与本机 IP 地址不一致的情况,kubelet 服务会异常退出,crt 和 key 必须重新制作。查看 apiserver.crt 的签名信息,发现 IP Address 以及 DNS 绑定了 k8s-master1,必须进行相应修改。
$ openssl x509 -noout -text -in /etc/kubernetes/pki/apiserver.crt
(2)在 k8s-master1、k8s-master2、k8s-master3 上使用 ca.key 和 ca.crt 制作 apiserver.crt 和
apiserver.key
$ mkdir -p /etc/kubernetes/pki-local$ cd /etc/kubernetes/pki-local
(3)在 k8s-master1、k8s-master2、k8s-master3 上生成 2048 位的密钥对
$ openssl genrsa -out apiserver.key 2048
(4)在 k8s-master1、k8s-master2、k8s-master3 上生成证书签署请求文件
$ openssl req -new -key apiserver.key -subj "/CN=kube-apiserver," -out apiserver.csr
(5)在 k8s-master1、k8s-master2、k8s-master3 上编辑 apiserver.ext 文件,${HOST_NAME}修改为本机主机名,${HOST_IP}修改为本机 IP 地址,${VIRTUAL_IP}修改为 keepalived 的虚拟 IP(172.24.12.80)
$ vi apiserver.extsubjectAltName = DNS:${HOST_NAME},DNS:kubernetes,DNS:kubernetes.default,DNS:kubernetes.default.svc, DNS:kubernetes.default.svc.cluster.local, IP:10.96.0.1, IP:${HOST_IP}, IP:${VIRTUAL_IP}
(6)在 k8s-master1、k8s-master2、k8s-master3 上使用 ca.key 和 ca.crt 签署上述请求
$ openssl x509 -req -in apiserver.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out apiserver.crt -days 365 -extfile /etc/kubernetes/pki-local/apiserver.ext
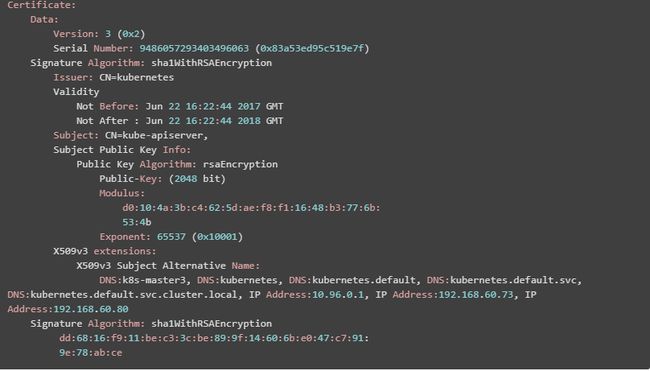
(7)在 k8s-master1、k8s-master2、k8s-master3 上查看新生成的证书:
$ openssl x509 -noout -text -in apiserver.crt
(8)在 k8s-master1、k8s-master2、k8s-master3 上把 apiserver.crt 和 apiserver.key 文件复制到 /etc/kubernetes/pki 目录
cp apiserver.crt apiserver.key /etc/kubernetes/pki/
- 在 k8s-master2 和 k8s-master3 上修改 admin.conf,
${HOST_IP}修改为本机 IP 地址
$ vi /etc/kubernetes/admin.confserver: https://${HOST_IP}:6443
- 在 k8s-master2 和 k8s-master3 上修改 controller-manager.conf,
${HOST_IP}修改为本机 IP 地址
$ vi /etc/kubernetes/controller-manager.confserver: https://${HOST_IP}:6443
- 在 k8s-master2 和 k8s-master3 上修改 scheduler.conf,
${HOST_IP}修改为本机 IP 地址
$ vi /etc/kubernetes/scheduler.confserver: https://${HOST_IP}:6443
- 在 k8s-master1、k8s-master2、k8s-master3 上重启所有服务
$ systemctl daemon-reload && systemctl restart docker kubelet
验证高可用安装
- 在 k8s-master1、k8s-master2、k8s-master3 任意节点上检测服务启动情况,发现 apiserver、controller-manager、kube-scheduler、proxy、flannel 已经在 k8s-master1、k8s-master2、k8s-master3 成功启动
$ kubectl get pod --all-namespaces -o wide | grep k8s-master1$ kubectl get pod --all-namespaces -o wide | grep k8s-master2$ kubectl get pod --all-namespaces -o wide | grep k8s-master3

- 在 k8s-master1、k8s-master2、k8s-master3 任意节点上通过 kubectl logs 检查各个 controller-manager 和 scheduler 的 leader election 结果,可以发现只有一个节点有效表示选举正常
$ kubectl logs -n kube-system kube-controller-manager-k8s-master1$ kubectl logs -n kube-system kube-controller-manager-k8s-master2$ kubectl logs -n kube-system kube-controller-manager-k8s-master3$ kubectl logs -n kube-system kube-scheduler-k8s-master1$ kubectl logs -n kube-system kube-scheduler-k8s-master2$ kubectl logs -n kube-system kube-scheduler-k8s-master3
- 在 k8s-master1、k8s-master2、k8s-master3 任意节点上查看 deployment 的情况
$ kubectl get deploy --all-namespaces

- 在 k8s-master1、k8s-master2、k8s-master3 任意节点上把 kubernetes-dashboard、kube-dns、 scale up 扩成 replicas=3,保证各个 master 节点上都有运行
$ kubectl scale --replicas=3 -n kube-system deployment/kube-dns$ kubectl get pods --all-namespaces -o wide| grep kube-dns$ kubectl scale --replicas=3 -n kube-system deployment/kubernetes-dashboard$ kubectl get pods --all-namespaces -o wide| grep kubernetes-dashboard$ kubectl scale --replicas=3 -n kube-system deployment/heapster$ kubectl get pods --all-namespaces -o wide| grep heapster
keepalived 安装配置
- 在 k8s-master、k8s-master2、k8s-master3 上安装 keepalived
$ yum install -y keepalived$ systemctl enable keepalived && systemctl restart keepalived
- 在 k8s-master1、k8s-master2、k8s-master3 上备份 keepalived 配置文件
$ mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
- 在 k8s-master1、k8s-master2、k8s-master3 上设置 apiserver 监控脚本,当 apiserver 检测失败的时候关闭 keepalived 服务,转移虚拟 IP 地址
$ vi /etc/keepalived/check_apiserver.sh#!/bin/bash err=0 for k in $( seq 1 10 ) do check_code=$(ps -ef|grep kube-apiserver | wc -l) if [ "$check_code" = "1" ]; then err=$(expr $err + 1) sleep 5 continue else err=0 break fi done if [ "$err" != "0" ]; then echo "systemctl stop keepalived" /usr/bin/systemctl stop keepalived exit 1 else exit 0 fi$ chmod a+x /etc/keepalived/check_apiserver.sh
- 在 k8s-master1、k8s-master2、k8s-master3 上查看接口名字
$ ip a | grep 172.24.12
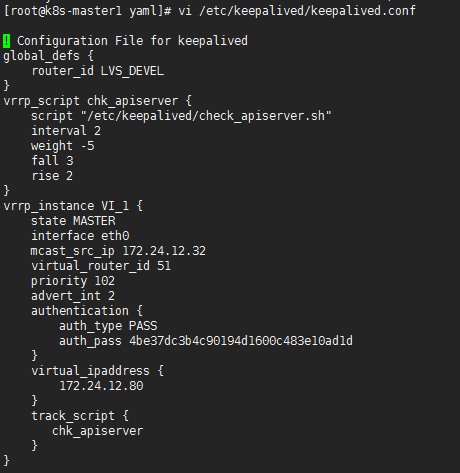
- 在 k8s-master1、k8s-master2、k8s-master3 上设置 keepalived,参数说明如下:
state${STATE}:为 MASTER 或者 BACKUP,只能有一个 MASTER
interface${INTERFACE_NAME}:为本机的需要绑定的接口名字(通过上边的 ip a 命令查看)
mcast_src_ip${HOST_IP}:为本机的IP地址
priority${PRIORITY}:为优先级,例如 102、101、100,优先级越高越容易选择为 MASTER,优先级不能一样, master设置应高于 backup
${VIRTUAL_IP}:为虚拟的 IP 地址,这里设置为 172.24.12.80
$ vi /etc/keepalived/keepalived.conf
- 在 k8s-master1、k8s-master2、k8s-master3 上重启 keepalived 服务,检测虚拟 IP 地址是否生效
$ systemctl restart keepalived$ ping 172.24.12.80
nginx负载均衡配置
- 在 k8s-master1、k8s-master2、k8s-master3 上修改 nginx-default.conf设置,
${HOST_IP}对应 k8s-master1、k8s-master2、k8s-master3 的地址。通过 nginx 把访问 apiserver 的 6443 端口负载均衡到 8433 端口上
$ vi /home/yaml/nginx-default.confstream { upstream apiserver { server ${HOST_IP}:6443 weight=5 max_fails=3 fail_timeout=30s; server ${HOST_IP}:6443 weight=5 max_fails=3 fail_timeout=30s; server ${HOST_IP}:6443 weight=5 max_fails=3 fail_timeout=30s; } server { listen 8443; proxy_connect_timeout 1s; proxy_timeout 3s; proxy_pass apiserver; } }
- 在 k8s-master1、k8s-master2、k8s-master3 上启动 nginx 容器
$ docker run -d -p 8443:8443 \ --name nginx-lb \ --restart always \ -v /home/yaml/nginx-default.conf:/etc/nginx/nginx.conf \ nginx
- 在 k8s-master1、k8s-master2、k8s-master3 上检测 keepalived 服务的虚拟 IP 地址指向
$ curl -L 192.168.60.80:8443 | wc -l% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 14 0 14 0 0 18324 0 --:--:-- --:--:-- --:--:-- 14000 1
- 业务恢复后务必重启 keepalived,否则 keepalived 会处于关闭状态
$ systemctl restart keepalived
- 在 k8s-master1、k8s-master2、k8s-master3 上查看 keeplived 日志,有以下输出表示当前虚拟 IP 地址绑定的主机
$ systemctl status keepalived -lVRRP_Instance(VI_1) Sending gratuitous ARPs on ens160 for 172.24.12.80
kube-proxy配置
- 在 k8s-master1 上设置 kube-proxy 使用 keepalived 的虚拟IP地址,避免 k8s-master1 异常的时候所有节点的 kube-proxy 连接不上
$ kubectl get -n kube-system configmap NAME DATA AGE extension-apiserver-authentication 6 4h kube-flannel-cfg 2 4h kube-proxy 1 4h
- 在 k8s-master1 上修改 configmap/kube-proxy 的 server 指向 keepalived 的虚拟IP地址
$ kubectl edit -n kube-system configmap/kube-proxy server: https://172.24.12.80:8443
- 在 k8s-master1 上查看 configmap/kube-proxy 设置情况
$ kubectl get -n kube-system configmap/kube-proxy -o yaml
- 在 k8s-master1 上删除所有 kube-proxy 的 pod,让 proxy 重建
kubectl get pods --all-namespaces -o wide | grep proxy
- 在 k8s-master1、k8s-master2、k8s-master3 上重启 docker kubelet keepalived 服务
systemctl restart docker kubelet keepalived
验证 master 集群高可用
在 k8s-master1 上检查各个节点 pod 的启动状态,每个上都成功启动 heapster、kube-apiserver、kube-controller-manager、kube-dns、kube-flannel、kube-proxy、kube-scheduler、kubernetes-dashboard、monitoring-grafana、monitoring-influxdb。并且所有 pod 都处于 Running 状态表示正常
$ kubectl get pods --all-namespaces -o wide | grep k8s-master1$ kubectl get pods --all-namespaces -o wide | grep k8s-master2$ kubectl get pods --all-namespaces -o wide | grep k8s-master3
node 节点加入高可用集群设置
- 在 k8s-master1 上查看集群的 token
$ kubeadm token list
- 在 k8s-node1~k8s-node8 上,
${TOKEN}为 k8s-master1 上显示的 token,${VIRTUAL_IP}为 keepalived 的虚拟 IP 地址 172.24.12.80
$ kubeadm join --token ${TOKEN} ${VIRTUAL_IP}:8443
- 查看 kubelet status,确保 activing
[root@k8s-node1 ~]# systemctl start kubelet[root@k8s-node1 ~]# journalctl -xeu kubelet
注:如果有不必要的报错,使用下面 join 方法:
[root@k8s-node1 ~]# kubeadm join --token efeayj.qa8q6c0ojo72crsn 172.24.12.80:8443 --ignore-preflight-errors 'all' --discovery-token-unsafe-skip-ca-verification
部署应用验证集群
- 在 k8s-node1 ~ k8s-node8 上查看 kubelet 状态,kubelet 状态为 active (running) 表示 kubelet 服务正常启动
systemctl status keepalived
- 在 k8s-master1 上检查各个节点状态,发现所有 k8s-nodes 节点成功加入
[root@k8s-master1 yaml]# kubectl get nodes -o wide

- 在 k8s-master1 上测试部署 nginx 服务,nginx 服务成功部署到 k8s-node1 上
[root@k8s-master1 yaml]# kubectl run nginx --image=nginx --port=80[root@k8s-master1 yaml]# kubectl get pod -o wide -l=run=nginx

- 在 k8s-master1 让 nginx 服务外部可见
[root@k8s-master1 yaml]# kubectl expose deployment nginx --port=80 --target-port=80 --type=NodePort[root@k8s-master1 yaml]# kubectl get svc -l=run=nginx

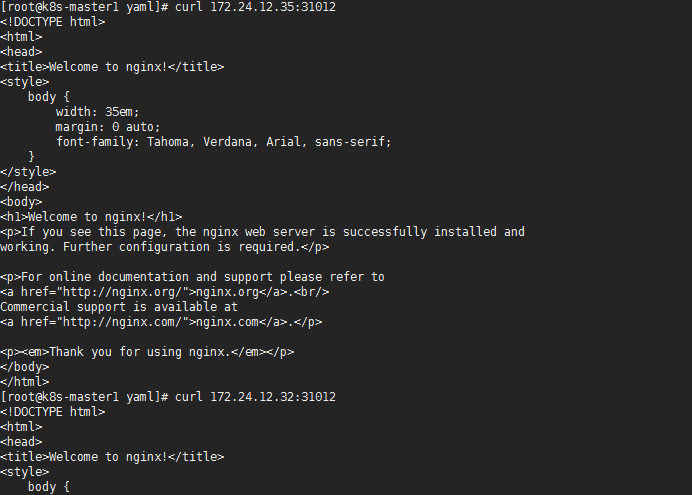
- 访问测试
[root@k8s-master1 yaml]# curl 172.24.12.35:31012
或者使用浏览器访问,如下:

至此,kubernetes 高可用集群成功部署!