A.设计流程
从项目启动之时,数据库设计工作就已经开始,贯穿于项目前期阶段的需求调研、分析、确认、业务梳理过程,只不过这时的设计大都停留在脑海中,正式的设计过程起始于最终的需求确认完成、业务梳理清晰之后。
就目前来看,最好的关系型数据库设计工具还是PowerDesigner(以后简称PD),我们要求正式数据库设计过程中必须使用此工具,先出CDM(Concept Data Model,概念数据模型),再根据实际的数据库类型由CDM导出PDM(Physical Data Model,物理数据模型),最后由PDM将设计成果直接导入到数据库中。同时导出相应的数据库文档,以供项目组开发人员查阅。
CDM设计过程中只做最简单必要的设计,约束、关系、主键、外键、命名规则等在转换成PDM过程中PD可自行处理的部分均交由工具自行处理。就是说数据库设计者只负责工具无法处理的少许部分,工具可完成的部分则用工具统一处理,这样设计工作会更高效省时,最终的设计成果也会更规范合理。
初版数据库设计完成之后进入项目开发阶段,如果前期的需求调研分析、业务梳理没问题,后期数据库结构发生大规模改动的情况不应该频繁出现的。但需求总是在变,意外才是唯一的法则,即便设计者在前期调研、了解、分析、设计的过程中再过谨慎,怕只能减少这种情况出现的风险,却不能完全避免。还有随着开发的深入,数据库结构发生局部变动,比如增删改些表字段等也是再正常不过的了。针对这些,都应该有相应的对策,才能以不变应万变。
第一版的数据库设计完成,由PDM生成相应的SQL脚本在数据库中执行之后,随开发深入而再进行的数据库改动分两种情况:一种是大改,比如原有的业务有变动,或因在设计时考虑不周、对需求了解不清导致设计出错,表及引用关系都要发生重大变化,刚也说了这种情况不应该出现;另一种是小改,比如有新增业务的情况要新建些表,有拿掉部分业务的情况可能会删除些表,还有更常出现的是增删改部分表的部分字段。
对于以上两种,有增加表或大规模业务变动的情况,建议是在PD中修改PDM,然后重新生成SQL脚本在数据库中执行,当然只生成新增表或发生业务变动部分的即可,而对于简单的增删改些字段或业务变动不大的情况,建议直接在数据库中对表进行修改。然后通过PD菜单中的Database——Update Model from Database……连接数据库逆向更新PDM,使PDM和最新的数据库结构保持一致,而后再生成最新的数据库文档。但要注意的是,使用此功能逆向更新PDM,只会更新修改或新增的表字段,而不更新删除的字段。就是说,如果在数据库中对一个表的字段进行了修改,或者新增了一些字段,PD会同步在PDM中的相应表中做出相应的修改或新增,但如果在数据库中删除了表中的某个字段,PD是不会删除PDM中相应表的相应字段的。为什么这般处理,自己也觉得很奇怪。
后期的数据库改动,一般发生在程序开发启动后,如果主程序可自动生成,第二种小改的情况还是比较容易处理的,重新生成下主程序,而手写的部分(非自动生成部分)一般不会受到太大影响。但如果是第一种情况,业务发生了变动,那可能意味着手写的程序(非自动生成部分)要重写。之前的文章中也有提及,一定要注意前期的需求调研了解分析系统设计,后期的问题几乎都是由前期的不慎造成,有经验的项目经理可以在前期预料到后面可能的问题而提前采取相应的预防措施。防之于未有,治之于未乱。项目想要做的出色,有太多不可测因素,但如果手底下的项目都很稳当,其能力必是值得肯定的。

这里还要提一点,后期数据库表小范围的修改一般是由开发人员发现,比如在开发过程中发现少了一些字段,或局部业务有些问题等等,应该禁止开发人员擅自直接更改数据库,所有更改无论大小必须经过数据库主设计师的审核同意,以避免可能影响到全局的更改出现。
数据库的设计工作虽然集中在项目的业务梳理清晰之后、正式开发之前,但相关细枝末节的工作却不止于此,很可能会贯穿于整个项目的起始流程。
B.三种关系
有人说数据库难以设计,其实难的并不是数据库的设计,而是业务流程的梳理。再复杂的业务,只要理得清,表现在数据库中,无外乎是表与表间的三种关系:一对一(one-to-one)、一对多(one-to-many)以及多对多(many-to-many)。更进一步的,many-to-many实际上就是两个one-to-many。
在Java中万事万物皆对象,在关系型数据库中万事万物皆是二维表,而事物之间的联系系就是表与表间的这三种关系。
后面还会多次提及,我们的设计原则是尽可能让粒度小、容忍度高,比如在“设计规范”——“字段设置”——“通用字段处理”中有关于日期时间类型设置的说明,要求日期时间类型的字段,尽可能用datetime类型,精确到时分秒,而不要用date类型。表现在这里,处理业务关系时,对于核心业务部分尚不能明确表与表关系的,能一对多就不要一对一,能多对多就不要一对多。这样开发的复杂度会增加,却消除了后面可能的修改扩展的隐患。对于非核心业务也不能明确关系的,可根据实际情况,综合考量开发实现的烦琐程度及未来的可变性再做决定。
PD细化了这三种关系的表述,表现在CDM关系中Cardinalities选项卡的Cardinality选项中、表现在PDM引用中Integrity选项卡的Cardinality选项中。Cardinality,基数,在CDM的选项中表示另一方对于当前方的每个实例,可能拥有的实例的最少和最多数;在PDM的选项中表示父表中的每个实例,子表中可能拥有的实例的最少和最多数。
比如“病人”与“会诊单”两个实体之间的联系是one-to-many联系,换个方向说“会诊单”和“病人”之间的联系是many-to-one联系。而且一个会诊单必须属于一个病人,并且只能属于一个病人,不能属于零个病人,所以从“会诊单”实体至“病人”实体的基数为“1,1”;从联系的另一方向考虑,一个病人可以拥有多个会诊单,也可以没有任何会诊单,即零个会诊单,所以该方向联系的基数就为“0,n”。CDM中的表示如下图所示:
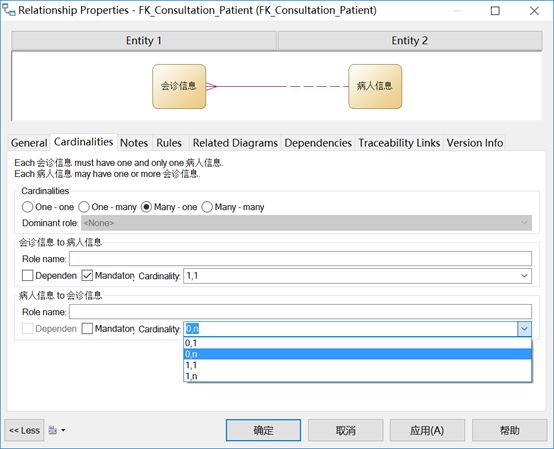
在构建CDM、选择两个实体之间的关系时,这部分会自动赋值的。
类似的,一个品牌必需且只能属于一个企业,一个企业却可以有一个或多个品牌,又或者一个也没有。在PDM的选项中表示父表为企业、子表为品牌,父表(企业)中的每个实例,子表(品牌)中可能拥有的实例的最少和最多数。如下图所示:
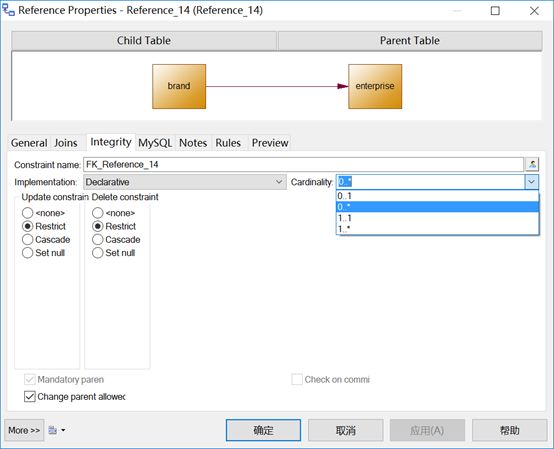
PD的细化在于,one-to-one关系中到底是must have one and only one还是may have at most one,one-to-many关系中到底是must have one or more还是may have one or more。many-to-many关系需要借助中间表实现,分解成两个one-to-many组合,类似的,也可被细分成严格的多对多还是模糊的多对多。可以拿用户和角色的例子说明,严格的多对多是一个用户至少有一个角色、一个角色至少被一个用户拥有,模糊的多对多是一个用户可以没有任何角色、一个角色可以不被任何用户拥有。
个人认为对one-to-many和many-to-many两种关系进行细化的意义不大,因为对于one-to-many、many-to-one,无论是否严格,都要在many方加入引用one方主键的外键;而对于many-to-many,无论是否严格,中间表都是必须的。所以对于这两种关系,无论是否为严格的,设计方案是确定的。
但对于one-to-one,严格的和非严格关系之间设计上是有区别的。比如订单和取消原因,一个订单可以有一个或零个取消原因(may have at most one),本来如果是严格的一对一关系,取消原因是可以整合到订单表中的,而无需单建表存储。再比如班级与班长,一个班级只有一个正班长,一个班长只在一个班中任职,两边都是must have one and only one,那班长表完全可以省略,而直接在班级表中加入相应描述班长信息的字段即可,比如班长名称、性别等等,又或者直接有个班长的外键字段指向学生表。
C.如何设计
拿到项目后,完成早期的需求调研,在分析设计的过程中,先考虑的是要实现所需功能、需要的实体有哪些。比如要实现登录功能,那必需要有用户实体。继续扩展思路,登录往往伴随着角色划分,为此要有角色、权限相关的实体。为了记录登录请求,又要有登录日志实体。这些实体表现在数据库即为相应的表,实体确定,同步考虑实体与实体间的关系。一个用户可以有多个角色,一个角色可以被多个用户拥有,所以用户和角色是多对多关系,多对多关系意味着出现中间表。一个用户可以有多条登录日志,一条登录日志有且只能对应一个用户,所以用户和登录日志是一对多的关系,登录日志表中要有外键引用用户表。这就是数据库设计的过程。
数据库的设计往往和前端界面的设计并行,前者稍晚于后者,两者的进行伴随在业务梳理的过程中、前期需求确认之后,为确保对需求理解的准确性、设计的准确性,此过程中应该继续和需求提出者保持沟通。如果在设计数据库时不考虑前端界面设计、或者是在设计界面时不考虑数据库设计,且不说两边对业务需求的理解可能有偏差,即便完全没有,最终怕也不能完好无误的进行融合,这也是为什么觉得项目经理、产品经理、技术经理的角色一人扮演要比三人分饰更好的原因。成熟的社会体制下,人与人间的分工应该更加明确,这无可厚非,问题就出在很多公司分工提前明确了,协作体制却不完善。如此这般,做一件事情参与的人越多,不但不会节省工时,反而导致的问题越多,大大降低了工作效率。
负责数据库设计工作的人应该是最懂项目、最懂业务需求、最有设计经验的人,此人必须跟踪整个项目的设计开发过程,产品界面的设计、程序的开发都要和其沟通确认方可。项目设计开发实施过程中,很多决定,不是参与决定的人越多越好,而是由一个最懂项目的人决定最好。有时为了某个决定组织集体讨论,最终的决定往往来自于主导讨论者,而非是最懂项目者。做项目和带兵打仗一样,最怕饭桶主导局势。而做为项目主负责人,你可以不是最懂项目的,但一定要清楚的是这个项目安排给谁去懂最合适,他有没有这个能力、是否能听从安排。一旦让他去懂,在项目推进过程中观察他是否能胜任、各子环节最懂的那个人又是谁。明白谁最懂、谁肯听众安排,则把相应部分的决定权交到相应最懂、最听从安排的人手中。而后除非出现特殊情况,自己不要去干涉、也不要让其他人去干涉。
D.主设计师
原则上讲,百张表内的数据库最好由一人来设计。一百张表,即使每张有一百个字段,总共也不过一万个,如果用工具生成,三五天内足够。当然数据库设计工作的难易并非是由表个数、字段个数决定的,而更多在于业务的复杂程度。表个数、字段个数在一定程度上可以反应出业务的复杂程度,但却非决定性因素。这里讲百张表内的设计工作量并不大,是说业务理清后将设计具体化成CDM、PDM的体力工作。要求由一人来设计是为了确保最终数据库的统一性、完整性、协调性,如果不能保证统一,最终项目的稳定性绝对得不到保障。不仅数据库的设计如此,架构、程序、前端、样式、脚本、UI都一样。在项目设计阶段,通常情况下,局部模块设计的优良并不会提升整个项目的质量,然而局部模块设计出现的问题最终却可能撼动整个项目的稳定。千里之堤毁于蚁穴,务必要确保设计工作的谨慎协调统一。再说大部分企业内部应用系统,项目规模有限,一个人主设计足够。
特殊情况下,如果项目大到一定程度,所有数据库设计工作交到一人手上着实过量,不得不安排多人参与其中,那主设计师也必须只有一位,且所有参与人员都要严格遵守相应的数据库设计规范。要利用PD的版本控制功能协调统一,最终由主设计师汇总校验所有人的设计,最终的数据库设计应该看起来像一个人的杰作,这也是程序、脚本、样式、UI设计开发所追求的目标。
主设计师汇总校验之后,还应再组织会议对设计成果校验,包括所有参与设计的人员、程序开发人员等,一起讨论。查找可能出现的不合理的地方,比如有部分可能和需求业务不合、可能会影响到开发实现等等。数据库的校验审核工作,参与人员尽可能多点,鼓励提问,有助于查缺补漏,发现问题。
E.关于DBA
有公司规定所有项目的数据库设计,DBA必须参与,但数据库设计工作重在对业务的把控、了解,其次才是对数据库本身的了解,这两项缺一不可,且前者更为重要。DBA的专业技能或许会更好一点,但是对业务的了解呢?还有公司的运维团队中,DBA会脱离项目实际,设置一些不必要的数据库规范,强加给开发团队。
在做项目时,一方面非常讨厌外部强加的规范,另一方面又不停的给自己、给团队设定规范。讨厌外部强加的规范是因为这些规范大都是些PMO指定的人凭空设想出来、脱离项目实际的,这些规范只会给项目带来更多的麻烦。而给自己和团队设定规范,则是为了约束设计和开发行为,确保项目最终实现的合理统一协调,这在后面的“命名规范”——“引言”中还有进一步的说明。
大的项目、大的团队可能会有多个专业DBA负责数据库维护工作,但就自己接触,即便公司、团队本身有DBA,绝大部分规模的项目中数据库维护工作还是多由程序开发人员兼顾。再者,真正优秀的DBA少之又少,有时不够专业的DBA过多介入反而会阻碍项目的正常开发。
DBA出现的时机应该是在开发人员无法解决数据库出现的问题时,比如当数据量大到一定程度,项目运行缓慢,仅凭程序优化已遇到瓶颈,这时可以向公司申请DBA介入,优化数据库设计、SQL语句等。再比如遇到数据备份问题、出现数据丢失问题等,也可申请DBA协助。如果项目规模大到一定程度,出现性能瓶颈问题是很正常的,这时专业DBA的作用才开始突显,且会在其中扮演一个非常重要的角色。
总之,DBA应该是在被需要时出现,而不应该被强制需要。
我的项目开发思路非常明确,关于团队,人越少越优秀越好,人员明确分工;关于开发模式,前端、后端、数据库明确分工。在项目规模、工作量允许的范围内人越少越好、涉及合作的部门越少越好,以便统一管理控制,节约沟通协调的成本。开发过程中的规范和约定采用大一统的方式,严格限制脱离中央管控的脚本或代码出现。