Python高级应用程序设计任务(爬取天气后报中国历史天气网)
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取天气后报全国历史天气
2.主题式网络爬虫爬取的内容与数据特征分析
爬取天气后报全国历史天气,对全国所有城市从2011-2019年所有的天气进行爬取,将爬取出来的数据转存为csv文件,
运用python的可视化库对爬取出来的数据进行可视化出来 使得天气的温度变化一目了然,主要爬取的为天气状况与最高气温和最低气温
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
对于天气历史数据进行爬取数据的思路是将一个一个城市数据都爬取出来,虽然这个网站没有反爬虫机制,但是他的数据比较庞大。中国的城市众多,运用现在所学的知识还无法用简单的代码将他轻松实现,根据对网址的一一分析,变化的只有城市拼音的不同,由此我找到了比较相对容易实现的方法,对url地址进行改变进而可以对所有城市数据都进行爬取
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
网页的结果就是有在时间日期后这三个内容
| 日期 | 天气状况 | 气温 | 风力风向 |
打开网页的源代码查看

这三个内容就在table下的tbody里面 这正是我们要爬取的内容
2.Htmls页面解析
先找出网站头部信息,根据头部信息来请求数据
找到div的table文件头 进行搜索对需要的天气数据进行爬取
然后数据通过正则表达式获得
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
全部数据通过正则表达式获得,先对一个城市进行爬取 接下来改变url中城市的拼音对下一个城市进行反复操作
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
本次实验我们采用了requests库 还有RequestException用来爬取异常函数,还用了了beautifulsoup库来分析数据,用了三个系统自带库 os,csv,和time库,分别的作用是作系统接口模块 用来写入爬出数据,爬取出来的数据存储为csv文件还有时间
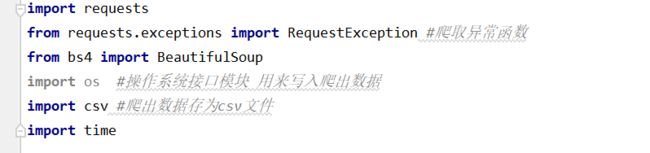
定义一个函数,获取网页的url,进行网页的数据爬取

2.对数据进行清洗和处理
对网页的内容进行出来还有数据的清洗

主函数部分
设置打开csv文件部分,存在f,将爬出来的数据写入csv文件,但一个年份爬取完就爬取下个年份,
当这个城市爬完就改变city,接着下一个城市
爬取后输出爬取完毕

city列表包含所有城市名称

爬取年份从2011到现在 月份是1月到12月

代码运行状况

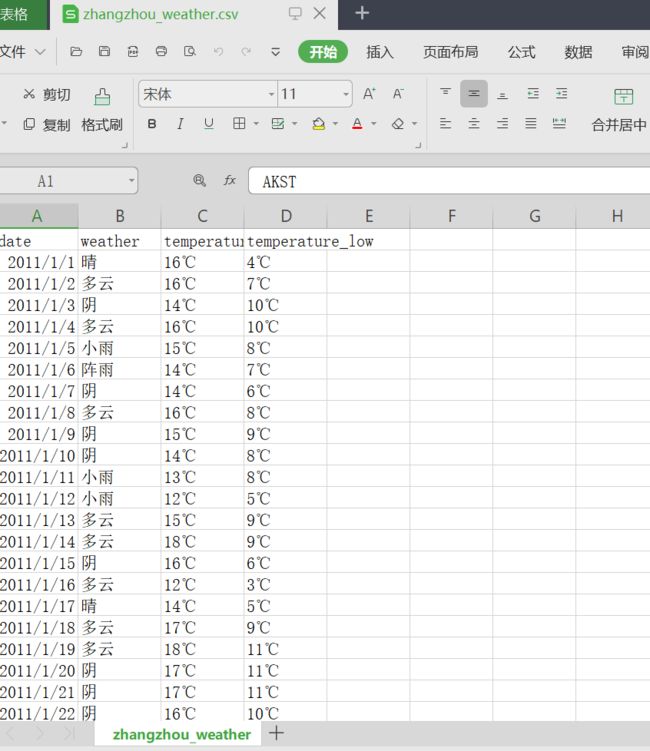
存为csv文件 文件里面数据
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
从我们网页爬出出来的数据存储到csv文件中,用可视化库将数据用图片的形式展示出来
用的3个库,为自带的csv库
还有matplotlib库、
还有datetime

读取csv 定义函数


设置可视图的大小尺寸,颜色,还有标题,和x,y轴数值

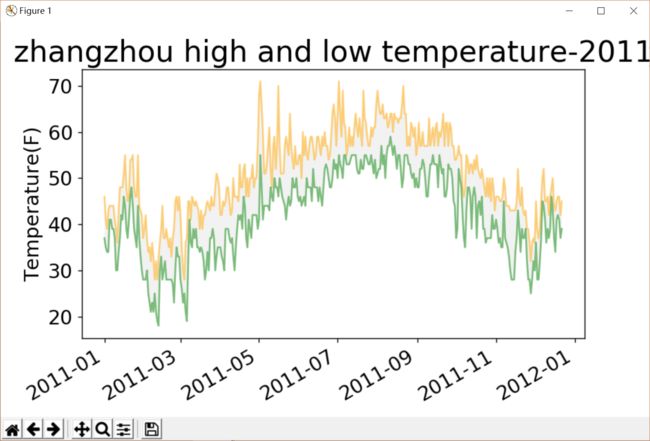
效果图
5.数据持久化
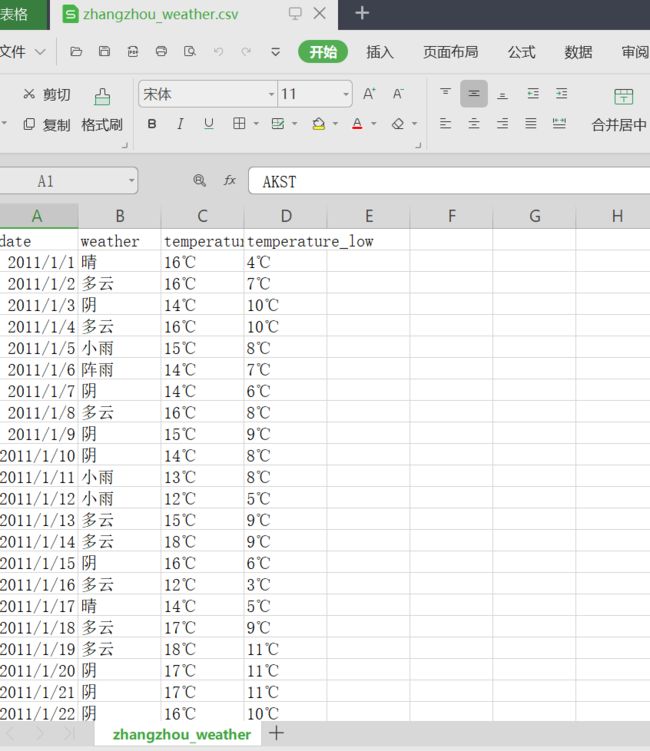
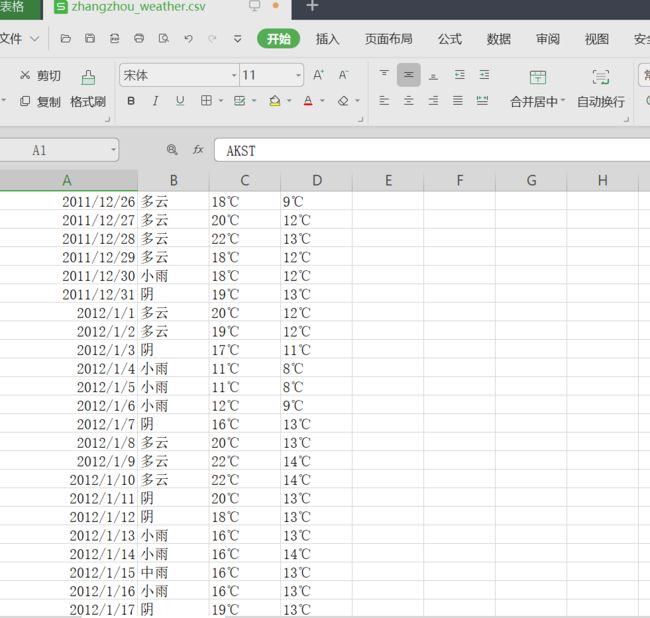
数据的持久化我们采用的是直接用内置库,csv 。将网页爬取到的数据存为测试csv中
打开文件内容
6.附完整程序代码
爬取代码
import requests from requests.exceptions import RequestException #爬取异常函数 from bs4 import BeautifulSoup import os #操作系统接口模块 用来写入爬出数据 import csv #爬出数据存为csv文件 import time def get_one_page(url): #获取网页url 进行爬取 print('进行爬取'+url) headers={'User-Agent':'User-Agent:Mozilla/5.0'} #头文件的user-agent try: response = requests.get(url,headers=headers) if response.status_code == 200: return response.content return None except RequestException: return None def parse_one_page(html):#解析清理网页 soup = BeautifulSoup(html, "lxml") info = soup.find('div', class_='wdetail') rows=[] tr_list = info.find_all('tr')[1:] # 使用从第二个tr开始取 for index, tr in enumerate(tr_list): # enumerate可以返回元素的位置及内容 td_list = tr.find_all('td') date = td_list[0].text.strip().replace("\n", "") # 取每个标签的text信息,并使用replace()函数将换行符删除 weather = td_list[1].text.strip().replace("\n", "").split("/")[0].strip() temperature_high = td_list[2].text.strip().replace("\n", "").split("/")[0].strip() temperature_low = td_list[2].text.strip().replace("\n", "").split("/")[1].strip() rows.append((date,weather,temperature_high,temperature_low)) return rows cities = ['beijing','shanghai','tianjin','chongqing','akesu','anning','anqing', 'anshan','anshun','anyang','baicheng','baishan','baiyiin','bengbu','baoding', 'baoji','baoshan','bazhong','beihai','benxi','binzhou','bole','bozhou', 'cangzhou','changde','changji','changshu','changzhou','chaohu','chaoyang', 'chaozhou','chengde','chengdu','chenggu','chengzhou','chibi','chifeng','chishui', 'chizhou','chongzuo','chuxiong','chuzhou','cixi','conghua', 'dali','dalian','dandong','danyang','daqing','datong','dazhou', 'deyang','dezhou','dongguan','dongyang','dongying','douyun','dunhua', 'eerduosi','enshi','fangchenggang','feicheng','fenghua','fushun','fuxin', 'fuyang','fuyang1','fuzhou','fuzhou1','ganyu','ganzhou','gaoming','gaoyou', 'geermu','gejiu','gongyi','guangan','guangyuan','guangzhou','gubaotou', 'guigang','guilin','guiyang','guyuan','haerbin','haicheng','haikou', 'haimen','haining','hami','handan','hangzhou','hebi','hefei','hengshui', 'hengyang','hetian','heyuan','heze','huadou','huaian','huainan','huanggang', 'huangshan','huangshi','huhehaote','huizhou','huludao','huzhou','jiamusi', 'jian','jiangdou','jiangmen','jiangyin','jiaonan','jiaozhou','jiaozou', 'jiashan','jiaxing','jiexiu','jilin','jimo','jinan','jincheng','jingdezhen', 'jinghong','jingjiang','jingmen','jingzhou','jinhua','jining1','jining', 'jinjiang','jintan','jinzhong','jinzhou','jishou','jiujiang','jiuquan','jixi', 'jiyuan','jurong','kaifeng','kaili','kaiping','kaiyuan','kashen','kelamayi', 'kuerle','kuitun','kunming','kunshan','laibin','laiwu','laixi','laizhou', 'langfang','lanzhou','lasa','leshan','lianyungang','liaocheng','liaoyang', 'liaoyuan','lijiang','linan','lincang','linfen','lingbao','linhe','linxia', 'linyi','lishui','liuan','liupanshui','liuzhou','liyang','longhai','longyan', 'loudi','luohe','luoyang','luxi','luzhou','lvliang','maanshan','maoming', 'meihekou','meishan','meizhou','mianxian','mianyang','mudanjiang','nanan', 'nanchang','nanchong','nanjing','nanning','nanping','nantong','nanyang', 'neijiang','ningbo','ningde','panjin','panzhihua','penglai','pingdingshan', 'pingdu','pinghu','pingliang','pingxiang','pulandian','puning','putian','puyang', 'qiannan','qidong','qingdao','qingyang','qingyuan','qingzhou','qinhuangdao', 'qinzhou','qionghai','qiqihaer','quanzhou','qujing','quzhou','rikaze','rizhao', 'rongcheng','rugao','ruian','rushan','sanmenxia','sanming','sanya','xiamen', 'foushan','shangluo','shangqiu','shangrao','shangyu','shantou','ankang','shaoguan', 'shaoxing','shaoyang','shenyang','shenzhen','shihezi','shijiazhuang','shilin', 'shishi','shiyan','shouguang','shuangyashan','shuozhou','shuyang','simao', 'siping','songyuan','suining','suizhou','suzhou','tacheng','taian','taicang', 'taixing','taiyuan','taizhou','taizhou1','tangshan','tengchong','tengzhou', 'tianmen','tianshui','tieling','tongchuan','tongliao','tongling','tonglu','tongren', 'tongxiang','tongzhou','tonghua','tulufan','weifang','weihai','weinan','wendeng', 'wenling','wenzhou','wuhai','wuhan','wuhu','wujiang','wulanhaote','wuwei','wuxi','wuzhou', 'xian','xiangcheng','xiangfan','xianggelila','xiangshan','xiangtan','xiangxiang', 'xianning','xiantao','xianyang','xichang','xingtai','xingyi','xining','xinxiang','xinyang', 'xinyu','xinzhou','suqian','suyu','suzhou1','xuancheng','xuchang','xuzhou','yaan','yanan', 'yanbian','yancheng','yangjiang','yangquan','yangzhou','yanji','tantai','yanzhou','yibin', 'yichang','yichun','yichun1','yili','yinchuan','yingkou','yulin1','yulin','yueyang','yongkang', 'yongzhou','yuxi','changchun','zaozhuang','zhangjiajie','zhangjiakou','changsha','changle', 'zhangzhou','zhuhai','zhengzhou','zunyi','fuqing','foshan',''] #获取城市名称 years = ['2011','2012','2013','2014','2015','2016','2017','2018'] months = ['01','02','03','04','05','06', '07', '08','09','10','11','12'] if __name__ == '__main__':#主函数 # os.chdir() # 设置工作路径 for city in cities: with open(city + '_weather.csv', 'a', newline='') as f: writer = csv.writer(f) writer.writerow(['date','weather','temperature_high','temperature_low']) for year in years: for month in months: url = 'http://www.tianqihoubao.com/lishi/'+city+'/month/'+year+month+'.html' html = get_one_page(url) content=parse_one_page(html) writer.writerows(content) print(city+year+'年'+month+'月'+'数据爬取完毕!') time.sleep(2)
可视化代码
import csv from matplotlib import pyplot as plt from datetime import datetime #读取CSV文件数据 filename='zhangzhou_weather.csv' with open(filename) as f: #打开这个文件,并将结果文件对象存储在f中 reader=csv.reader(f) #创建一个阅读器reader header_row=next(reader) #返回文件中的下一行 dates,highs,lows=[],[],[] #声明存储日期,最值的列表 for row in reader: current_date=datetime.strptime(row[0],'%Y-%m-%d') #将日期数据转换为datetime对象 dates.append(current_date) #存储日期 high=int(row[1]) #将字符串转换为数字 highs.append(high) #存储温度最大值 low=int(row[3]) lows.append(low) #存储温度最小值 #根据数据绘制图形 fig=plt.figure(dpi=128,figsize=(10,6)) plt.plot(dates,highs,c='Orange',alpha=0.5)#实参alpha指定颜色的透明度,0表示完全透明,1(默认值)完全不透明 plt.plot(dates,lows,c='green',alpha=0.5) plt.fill_between(dates,highs,lows,facecolor='gray',alpha=0.1) #给图表区域填充颜色 plt.title('zhangzhou high and low temperature-2011',fontsize=24) plt.xlabel('',fontsize=16) plt.ylabel('Temperature(F)',fontsize=16) plt.tick_params(axis='both',which='major',labelsize=16) fig.autofmt_xdate() #绘制斜的日期标签 plt.show()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
经过我们对天气网的爬取 得到了,全国城市的所有天气数据,从 2011 到现在为止 虽然我们没有将全国的所有天气完全爬不下来,这是客观原因上的 但是我们先将自己省内的城市扒取下来,经过数据的分析,省内城市的天气情况在这几年,最低温度最高温度都有所上涨 最高温度比往年多了一两 最低温度也比往年多了一两度 从这些数据看出当今,全球气候变暖的情况日益严重 我们有责任和义务,保护环境,防止全球变暖加剧 从可视化,直观图更可以看出,温度的曲线在不断的往上爬升,更加印证了全球变暖的可怕
2.对本次程序设计任务完成的情况做一个简单的小结。
这次的程序任务,使我加深了对Python的兴趣,这门语言去掉条条框框,更直观的代码操作,使我们更容易理解和操作。强大的第三方库,几乎是你想不到的,你要什么有什么都能实现,就拿这次的主题扒取天气网的数据来说,我需要爬取网页的内容,就用到了第三方库raquests 数据清理整理用的beautifulsoup 等等诸多的方便,许多第三方可视化的库,也能让我们直观的,将扒取到的数据呈现出来,看到它数据变化的趋势和未来的发展,这正是现在大数据和云计算所需要的有利工具。这次的课程实验,更加笃定的我学习Python的心