Inception模块分为V1、V2、V3和V4。
- V1(GoogLeNet)的介绍
论文:Going deeper with convolutions
论文链接:https://arxiv.org/pdf/1409.4842v1.pdf
主要问题:
- 每张图中主体所占区域大小差别很大。由于主体信息位置的巨大差异,那选择合适的卷积核相对来说就比较困难。信息分布更全局性的图像适合选用较大的卷积核,信息分布较局部的图像适合较小的卷积核。
- 非常深的网络更容易过拟合。将梯度更新传输到整个网络是很困难的。
- 简单地堆叠较大的卷积层非常消耗计算资源。
解决方法:
作者在神经网络设计上不是增加深度而是增加网络宽度,并且为了降低算力成本,作者在3*3和5*5卷积层之前添加额外的1*1卷积层,来限制输入信道的数量。

2.V2介绍
论文:Rethinking the Inception Architecture for Computer Vision
论文地址:https://arxiv.org/pdf/1512.00567v3.pdf
主要问题:
- 减少特征的表征性瓶颈。直观来说,当卷积不会大幅度改变输入维度时,神经网络可能会执行地更好。过多地减少维度可能会造成信息的损失,也成为[特征性瓶颈]。
- 使用更优秀的因子分解方法,卷积才能在计算复杂度上更加高效。
解决方法:
最左侧一排将5*5分解成两个3*3,实际上一个5*5卷积的计算成本是一个3*3卷积的2.78倍。所以叠加会提升性能。如下图:
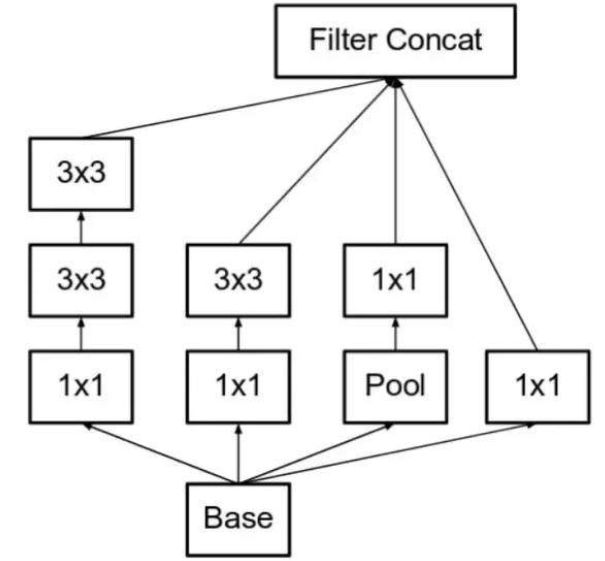
推论出,若有n*n卷积核,那么我们可以分解为1*n和n*1两个卷积。如下图,若n为3,则和上图一致:
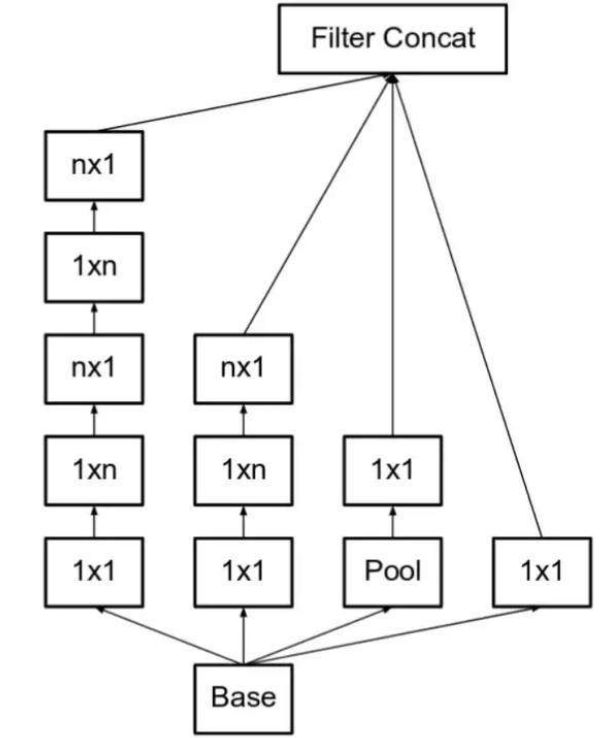
但是,为了解决表征性瓶颈,我们若拓宽模型而不是加深模型,那么会避免信息损失,如下图:

3.V3介绍
论文:Rethinking the Inception Architecture for Computer Vision
论文地址:https://arxiv.org/pdf/1512.00567v3.pdf
主要问题:
- 作者注意到辅助分类器直到训练过程快结束时才有较多的贡献,那时准确率接近饱和。作者认为辅助分类器的功能是正则化,尤其是它们具备BN和dropout时。
- 是否能够改进V2而无需大幅更改模块仍需要研究。
解决方法:
- RMSProp优化器;
- Factorized7*7卷积;
- 辅助分类器使用了BN;
- 标签平滑(添加到巡视公式的一种正则化项,旨在组织网络对某一类别过分自信,即阻止过拟合)。
4.V4介绍
论文:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
论文地址:https://arxiv.org/pdf/1602.07261.pdf
主要问题:
使模块更加一致。作者还注意到某些模块有不必要的复杂性。这允许我们通过添加更多一致的模块来提高性能。
解决方法:
图1左侧是V4的整体结构,图1右侧是V4的stem部分,用于对于进入Inception模块钱的数据进行预处理,减小对图像压缩的精度损失。stem部分就是多次卷积+2次池化,池化采用了V3论文里面提到的卷积+pooling并行的结构,来防止bottleneck问题。stem后用了3种Inception模块。直接的Reduction模块起到了pooling作用,同样使用了并行的结构来防止bottleneck问题。
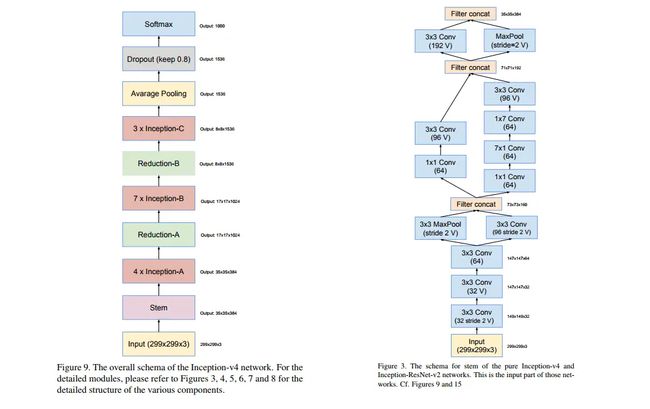
图1:Inception-V4结构
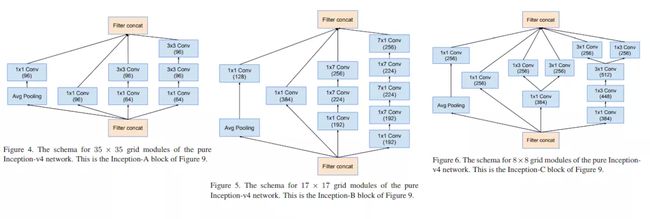
图2:从左到右分别为Inception-V4中的InceptionA\B\C模块
图3所示,V4中引入了专用的reduction block,它被用于改变网络的宽度和高度。

图3:Inception-V4中的Reduction模块
小总结:
- 降维:比如,一张500*500且厚度depth为100的图片在20个filter上做1*1的卷积,那么结果的大小为500*500*20.
- 加入非线性。卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励,提升网络的表达能力;可以在保持特征面尺度不变的(即不损失分辨率)的前提下大幅度增加非线性特性(利用后接的非线性激活函数),把网络坐的很深。