一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
关于链家泉州本地租房信息的爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
2.1爬取的内容
租房类型,所属区县,详细地址,房屋面积,房屋朝向,房屋房型,房屋楼层,房屋价格
2.2数据特征分析
分析泉州租房区县地图分布情况,价格排名,热门房型,热门楼层等
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
1、使用requests库网络请求,通过伪造请求头模拟访问
2、利用etree库进行网页解析,并通过xpath语法解析数据
3、先访问一遍页面获取所有区县,再针对每个区县的链接详细抓取信息
4、使用异常捕获判断数据是否完整
5、通过excel保存数据,后续通过pandas读取数据处理,最终通过pyecharts做可视化展示
技术难点:
1、访问过快容易请求不了数据,降低为单线程,并伪造请求头
2、每个区县下面的页数不一样,需要实现自动判定下一页功能
3、链家单个链接搜索下,最大只能100页,所以需要细分区县,然后针对每个区县来抓取
二、主题页面的结构特征分析(15分)
1、主题页面的结构特征
通过f12开启浏览器页面,查看页面结构,页面有12个区县,在下面每个区县页数不定,需要动态抓取
2、HTML页面解析
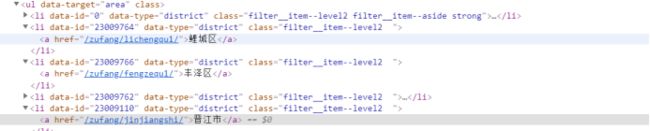
1. 区县信息如下
![]()
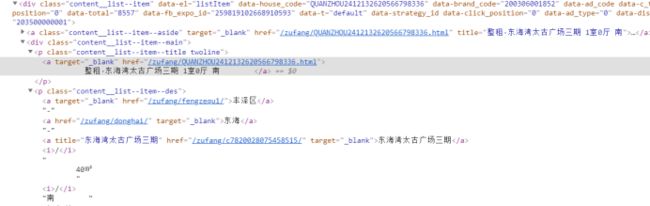
2. 每个房屋的信息

3. 页数信息

![]()
3、 节点(标签)查找方法与遍历发法(必要时画出节点数结构)
通过xpath解析区县链接,再循环遍历访问每个区县的链接,然后自定义页数为1,然后获取页面的总页数,然后通过判断是否大于总页数,来决定是否还有下一页
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1、数据爬取与采集
抓取区县信息
1 def get_area(): 2 # 请求区县地址 3 url = 'https://quanzhou.lianjia.com/zufang/' 4 5 # 循环请求,直到正确请求到数据才退出 6 while True: 7 try: 8 rsp = requests.get(url=url, headers=headers) 9 break 10 except Exception as e: 11 pass 12 dom = etree.HTML(rsp.text) 13 14 # 获取当前城市的区县信息 15 ul = dom.xpath('//ul[@data-target="area"]')[0] 16 lis = ul.xpath('./li') 17 # 删除第一个,例如不限 18 del lis[0] 19 # 存储区县信息 20 areas = [] 21 for li in lis: 22 # 获取区名称 23 dist_a = li.xpath('./a')[0] 24 dist_name = dist_a.xpath('./text()')[0] 25 dist_name = dist_name.strip() 26 # 获取区对应的连接 27 dist_href = dist_a.xpath('./@href')[0] 28 dist_href = dist_href[0].strip() 29 30 # 拼接地址 31 dist_href = root_url + dist_href 32 # 添加到列表中 33 areas.append({ 34 'dist_name': dist_name, 35 'dist_href': dist_href 36 }) 37 38 return areas
抓取每个区县下的租房信息
1 def get_area_data(area): 2 # 每次从第一页开始抓取 3 now_page = 1 4 # 存放区县数据 5 area_data = [] 6 # 获取区县链接 7 area_url = area['dist_href'] 8 while True: 9 print('当前{}页'.format(now_page)) 10 # 要抓取的目标地址 11 url = area_url + 'pg{}/'.format(now_page) 12 # 循环请求,直到正确请求到数据才退出 13 while True: 14 try: 15 rsp = requests.get(url=url, headers=headers) 16 break 17 except Exception as e: 18 pass 19 20 # 抓取每一页的信息 21 page_data = get_page(url) 22 for page in page_data: 23 area_data.append(page) 24 # 正则匹配看是否有总页数 25 patt = r'data-totalPage=(\d+) ' 26 sea_res = re.search(patt, rsp.text, re.S) 27 # 判断是否能匹配到数据 28 if sea_res: 29 # 获取总页数 30 page_num = int(sea_res.group(1)) 31 # 判断是否还有下一页 32 if now_page >= page_num: 33 break 34 else: 35 now_page += 1 36 else: 37 break 38 return area_data
抓取每一页的信息
1 # 请求每一页的数据 2 def get_page(page_url): 3 # 定义请求头,伪装成浏览器 4 headers = { 5 'Accept': 'text/html,application/xhtml+xml,application/xml;' 6 'q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 7 'Accept-Language': 'zh,en-US;q=0.9,en;q=0.8,zh-TW;q=0.7,zh-CN;q=0.6', 8 'Host': 'quanzhou.lianjia.com', 9 'Upgrade-Insecure-Requests': '1', 10 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)' 11 ' Chrome/78.0.3904.108 Safari/537.36' 12 } 13 # 循环请求,是为了防止请求过程中出问题 14 # 只有请求成功后才会退出循环 15 while True: 16 try: 17 rsp = requests.get(url=page_url, headers=headers) 18 break 19 except Exception as e: 20 pass 21 # 解析为etree格式 22 dom = etree.HTML(rsp.text) 23 # 使用xpath语法找到信息块 24 lis = dom.xpath('//div[@class="content__list--item--main"]') 25 # 存放当前页抓取的数据 26 page_data = [] 27 # 遍历每一条信息 28 for li in lis: 29 # 如果有信息不全的,就跳过 30 try: 31 line = parse_data(li) 32 except Exception as e: 33 continue 34 print(line) 35 # 添加到数据集合中 36 page_data.append(line) 37 return page_data
每一条房屋数据的解析
1 # 解析每一条数据 2 def parse_data(li): 3 line = [] 4 # 解析标题信息 5 item_title = li.xpath('./p[@class="content__list--item--title twoline"]')[0] 6 item_a = item_title.xpath('./a')[0] 7 item_text = item_a.xpath('./text()')[0] 8 title = item_text.strip() 9 # 获取详细信息块 10 item_des = li.xpath('string(./p[@class="content__list--item--des"])')[0] 11 item_desc = item_des.split('/') 12 # 获取租房类型,整租,合租 13 ttype = title.split('·') 14 ttype = ttype[0].strip() 15 line.append(ttype) 16 # 获取详细地址 17 address = item_desc[0].split('-') 18 19 # 获取地址属于哪个区 20 county = address[0].strip() 21 line.append(county) 22 # 详细地址去掉区 23 del address[0] 24 address = '-'.join(address).strip() 25 line.append(address) 26 # 获取房租面积信息 27 area = item_desc[1].strip() 28 # 去除多余字符 29 area = area.replace(' ', '') 30 area = area.replace('㎡', '') 31 line.append(area) 32 # 获取房屋朝向问题 33 orientation = item_desc[2].strip() 34 # 去除多余字符 35 orientation = orientation.replace(' ', '') 36 line.append(orientation) 37 # 获取房屋布局 38 room = item_desc[3].strip() 39 room = room.replace(' ', '') 40 line.append(room) 41 # 获取房屋楼层信息 42 floor = item_desc[4].strip() 43 floor = floor.replace(' ', '') 44 line.append(floor) 45 # 月租价格 46 item_price = li.xpath('./span[@class="content__list--item-price"]')[0] 47 item_em = item_price.xpath('./em')[0] 48 price = item_em.xpath('./text()')[0] 49 price = price.strip() 50 line.append(price) 51 52 return line
2、对数据进行清洗和处理
读取数据
1 # 使用pandas读取excel文件 2 df = pd.read_excel('泉州链家数据.xlsx')
对楼层数据进行数值提取
1 # 处理楼层数据,去除中文,保留数值 2 df['floor'] = df['floor'].str.extract(r'(\d+)', expand=False) 3 # 将字符串改为整型 4 floor = [] 5 for f in df['floor']: 6 if f == f: 7 floor.append(int(f)) 8 else: 9 floor.append(1) 10 df['floor'] = floor
格式化地区信息
1 # 格式化地区信息 2 county = [] 3 for c in df['county']: 4 if '市' in c: 5 county.append(c) 6 continue 7 if '区' not in c: 8 c += '区' 9 county.append(c) 10 df['county'] = county
对租房价格进行分组统计
1 fanwei = [] 2 label = [] 3 for x in range(0, 8000, 1000): 4 fanwei.append(x) 5 if x > 0: 6 label.append(str(x - 1000) + '-' + str(x)) 7 # 分组统计价格比例 8 # 分组区间 9 fenzu = pd.cut(df['price'].values, fanwei, right=False)
3、文本分析
词云图展示

1 # 生成词云图 2 def to_wordcloud(attr, values): 3 # 初始化词云图 4 wordcloud = WordCloud(width=800, height=500) 5 6 wordcloud.add("", attr, values, 7 word_size_range=[20, 100]) 8 # 生成图网页文件 9 wordcloud.render('房型词云图.html') 10 11 12 # 词云图 13 # 按房型分组 14 df_room = df.groupby(df['room']) 15 room_size = df_room.size() 16 # 词云图的词语 17 name_list = list(room_size.keys()) 18 # 词云图词语对应的词频数量 19 value_list = room_size.values 20 # 生成图 21 to_wordcloud(name_list, value_list)
4、可视化处理
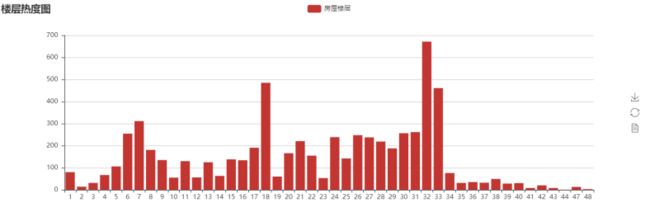
对楼层进行热度统计
1 # 生成楼层热度图 2 def to_bar(attr, values): 3 # 生成楼层图 4 bar = Bar('楼层热度图', width=1200) 5 # 设置图表参数 6 kwargs = dict( 7 name='房屋楼层', 8 x_axis=attr, 9 y_axis=values, 10 bar_category_gap=4 11 ) 12 bar.add(**kwargs) 13 # 生成图网页文件 14 bar.render('楼层热度图.html')
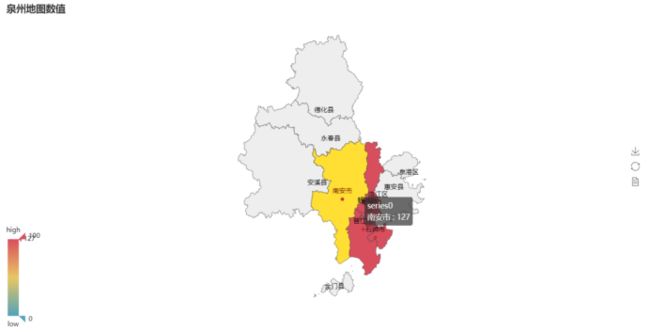
对当前抓取到的数据进行地图分布显示情况
1 # 生成地图 2 def to_map(attr, values): 3 map = Map("泉州地图数值", width=1200, height=600) 4 # 设置图表参数 5 kwargs = dict( 6 maptype="泉州", 7 is_visualmap=True, 8 is_label_show=True, 9 visual_text_color="#000" 10 ) 11 map.add( 12 "", attr, values, 13 **kwargs 14 ) 15 # 生成图网页文件 16 map.render('泉州地图数值.html')
对当前抓取的租房信息,进行价格区间分类
1 # 生成价格比例图 2 def to_pie(attr, value): 3 pie = Pie("价格比例图", title_pos='center', height=600) 4 # 设置图标参数 5 kwargs = dict( 6 radius=(40, 75), 7 label_text_color=None, 8 is_label_show=True, 9 legend_orient='vertical', 10 legend_pos='left' 11 ) 12 pie.add("", attr, value, 13 **kwargs) 14 # 生成图网页文件 15 pie.render('价格比例图.html')

租房信息排名前10
1 # 价格排名前10 2 def to_bar_top_10(attr, value, name): 3 # 设置柱状图的主标题 4 bar = Bar(name, "") 5 # 设置图表参数 6 bar.add( 7 "价格", attr, value, 8 mark_line=["average"], 9 bar_category_gap=40, 10 mark_point=["max", "min"], 11 xaxis_rotate=20, 12 yaxis_rotate=20 13 ) 14 # 生成本地文件(默认为.html文件) 15 bar.render(name + '.html')
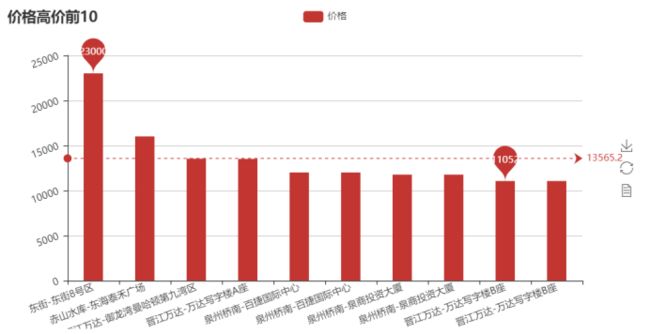
5、数据持久化
最终写入的excel
# 创建excel xls = openpyxl.Workbook() # 激活sheet sheet = xls.active # 先加入标题信息 title = ['type', 'county', 'address', 'area', 'orientation', 'room', 'floor', 'price'] # 添加列头 sheet.append(title) print("开始爬虫抓取") # 获取区县信息 area_list = get_area() # 遍历每一个区县 for area in area_list: print('当前抓取区:', area['dist_name']) # 获取区县下的房屋信息 area_data = get_area_data(area) # 遍历每一页结果 for data in area_data: # 添加到excel中 sheet.append(data) # 保存excel文件 xls.save('泉州链家数据.xlsx') print("数据抓取完成")
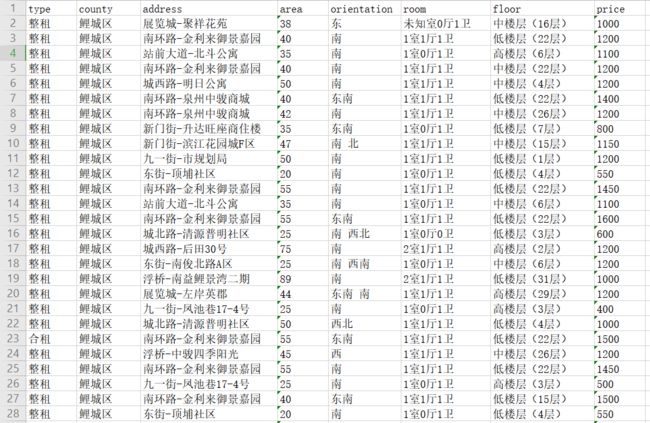
6、最终代码
1 import requests 2 from lxml import etree 3 import openpyxl 4 from pyecharts import Bar, Map, WordCloud, Pie 5 import pandas as pd 6 import re 7 8 9 # 解析每一条数据 10 def parse_data(li): 11 line = [] 12 # 解析标题信息 13 item_title = li.xpath('./p[@class="content__list--item--title twoline"]')[0] 14 item_a = item_title.xpath('./a')[0] 15 item_text = item_a.xpath('./text()')[0] 16 title = item_text.strip() 17 # 获取详细信息块 18 item_des = li.xpath('string(./p[@class="content__list--item--des"])')[0] 19 item_desc = item_des.split('/') 20 # 获取租房类型,整租,合租 21 ttype = title.split('·') 22 ttype = ttype[0].strip() 23 line.append(ttype) 24 # 获取详细地址 25 address = item_desc[0].split('-') 26 27 # 获取地址属于哪个区 28 county = address[0].strip() 29 line.append(county) 30 # 详细地址去掉区 31 del address[0] 32 address = '-'.join(address).strip() 33 line.append(address) 34 # 获取房租面积信息 35 area = item_desc[1].strip() 36 # 去除多余字符 37 area = area.replace(' ', '') 38 area = area.replace('㎡', '') 39 line.append(area) 40 # 获取房屋朝向问题 41 orientation = item_desc[2].strip() 42 # 去除多余字符 43 orientation = orientation.replace(' ', '') 44 line.append(orientation) 45 # 获取房屋布局 46 room = item_desc[3].strip() 47 room = room.replace(' ', '') 48 line.append(room) 49 # 获取房屋楼层信息 50 floor = item_desc[4].strip() 51 floor = floor.replace(' ', '') 52 line.append(floor) 53 # 月租价格 54 item_price = li.xpath('./span[@class="content__list--item-price"]')[0] 55 item_em = item_price.xpath('./em')[0] 56 price = item_em.xpath('./text()')[0] 57 price = price.strip() 58 line.append(price) 59 60 return line 61 62 63 # 请求每一页的数据 64 def get_page(page_url): 65 # 循环请求,是为了防止请求过程中出问题 66 # 只有请求成功后才会退出循环 67 while True: 68 try: 69 rsp = requests.get(url=page_url, headers=headers) 70 break 71 except Exception as e: 72 pass 73 # 解析为etree格式 74 dom = etree.HTML(rsp.text) 75 # 使用xpath语法找到信息块 76 lis = dom.xpath('//div[@class="content__list--item--main"]') 77 # 存放当前页抓取的数据 78 page_data = [] 79 # 遍历每一条信息 80 for li in lis: 81 # 如果有信息不全的,就跳过 82 try: 83 line = parse_data(li) 84 except Exception as e: 85 continue 86 print(line) 87 # 添加到数据集合中 88 page_data.append(line) 89 return page_data 90 91 92 # 生成楼层热度图 93 def to_bar(attr, values): 94 # 生成楼层图 95 bar = Bar('楼层热度图', width=1200) 96 # 设置图表参数 97 kwargs = dict( 98 name='房屋楼层', 99 x_axis=attr, 100 y_axis=values, 101 bar_category_gap=4 102 ) 103 bar.add(**kwargs) 104 # 生成图网页文件 105 bar.render('楼层热度图.html') 106 107 108 # 生成地图 109 def to_map(attr, values): 110 map = Map("泉州地图数值", width=1200, height=600) 111 # 设置图表参数 112 kwargs = dict( 113 maptype="泉州", 114 is_visualmap=True, 115 is_label_show=True, 116 visual_text_color="#000" 117 ) 118 map.add( 119 "", attr, values, 120 **kwargs 121 ) 122 # 生成图网页文件 123 map.render('泉州地图数值.html') 124 125 126 # 生成词云图 127 def to_wordcloud(attr, values): 128 # 初始化词云图 129 wordcloud = WordCloud(width=800, height=500) 130 131 wordcloud.add("", attr, values, 132 word_size_range=[20, 100]) 133 # 生成图网页文件 134 wordcloud.render('房型词云图.html') 135 136 137 # 生成价格比例图 138 def to_pie(attr, value): 139 pie = Pie("价格比例图", title_pos='center', height=600) 140 # 设置图标参数 141 kwargs = dict( 142 radius=(40, 75), 143 label_text_color=None, 144 is_label_show=True, 145 legend_orient='vertical', 146 legend_pos='left' 147 ) 148 pie.add("", attr, value, 149 **kwargs) 150 # 生成图网页文件 151 pie.render('价格比例图.html') 152 153 154 # 价格排名前10小区 155 def to_bar_top_10(attr, value, name): 156 # 设置柱状图的主标题 157 bar = Bar(name, "") 158 # 设置图表参数 159 bar.add( 160 "价格", attr, value, 161 mark_line=["average"], 162 bar_category_gap=40, 163 mark_point=["max", "min"], 164 xaxis_rotate=20, 165 yaxis_rotate=20 166 ) 167 # 生成本地文件(默认为.html文件) 168 bar.render(name + '.html') 169 170 171 # 可视化处理 172 def huatu(): 173 # 开始可视化处理 174 print("开始可视化处理") 175 # 使用pandas读取excel文件 176 df = pd.read_excel('泉州链家数据.xlsx') 177 # 处理楼层数据,去除中文,保留数值 178 df['floor'] = df['floor'].str.extract(r'(\d+)', expand=False) 179 # 将字符串改为整型 180 floor = [] 181 for f in df['floor']: 182 if f == f: 183 floor.append(int(f)) 184 else: 185 floor.append(1) 186 df['floor'] = floor 187 # 按楼层分组 188 df_floor = df.groupby(df['floor']) 189 # 获取分组后的数据 190 floor_size = df_floor.size() 191 # 排序 192 floor_size.sort_index() 193 # 转为list列表 194 attr = list(floor_size.keys()) 195 value = floor_size.values 196 # 生成bar图 197 to_bar(attr, value) 198 199 # 地区图 200 # 格式化地区信息 201 county = [] 202 for c in df['county']: 203 if '市' in c: 204 county.append(c) 205 continue 206 if '区' not in c: 207 c += '区' 208 county.append(c) 209 df['county'] = county 210 # 按楼层分组 211 df_county = df.groupby(df['county']) 212 # 获取分组后的数据 213 county_size = df_county.size() 214 value = county_size.values 215 # 转换为数值类型 216 int_value = [] 217 for val in value: 218 int_value.append(int(val)) 219 # 获取所有的区 220 attr = list(county_size.keys()) 221 # 生成图 222 to_map(attr, value) 223 224 # 词云图 225 # 按房型分组 226 df_room = df.groupby(df['room']) 227 room_size = df_room.size() 228 # 词云图的词语 229 name_list = list(room_size.keys()) 230 # 词云图词语对应的词频数量 231 value_list = room_size.values 232 # 生成图 233 to_wordcloud(name_list, value_list) 234 235 # 饼图 236 fanwei = [] 237 label = [] 238 for x in range(0, 8000, 1000): 239 fanwei.append(x) 240 if x > 0: 241 label.append(str(x - 1000) + '-' + str(x)) 242 # 分组统计价格比例 243 # 分组区间 244 fenzu = pd.cut(df['price'].values, fanwei, right=False) 245 246 pin_shu = fenzu.value_counts() 247 # 区间对应的个数 248 y = pin_shu.values 249 # 生成图 250 to_pie(label, y) 251 252 # 价格排名 253 label = [] 254 values = [] 255 # 根据价格排序 256 df_sort = df.sort_values(by="price", ascending=False) 257 # 取前10条数据 258 for x in range(0, 10): 259 # 从dataframe从取数据 260 line = df_sort.iloc[x] 261 label.append(line['address']) 262 values.append(line['price']) 263 # 生成图 264 to_bar_top_10(label, values, "价格高价前10") 265 266 # 价格排名 267 label = [] 268 values = [] 269 # 根据价格排序 270 df_sort = df.sort_values(by="price", ascending=True) 271 # 取前10条数据 272 for x in range(0, 10): 273 # 从dataframe从取数据 274 line = df_sort.iloc[x] 275 label.append(line['address']) 276 values.append(line['price']) 277 # 生成图 278 to_bar_top_10(label, values, "价格低价前10") 279 280 281 def get_area(): 282 # 请求区县地址 283 url = 'https://quanzhou.lianjia.com/zufang/' 284 # 循环请求,直到正确请求到数据才退出 285 while True: 286 try: 287 rsp = requests.get(url=url, headers=headers) 288 break 289 except Exception as e: 290 pass 291 dom = etree.HTML(rsp.text) 292 293 # 获取当前城市的区县信息 294 ul = dom.xpath('//ul[@data-target="area"]')[0] 295 lis = ul.xpath('./li') 296 # 删除第一个,例如不限 297 del lis[0] 298 # 存储区县信息 299 areas = [] 300 for li in lis: 301 # 获取区名称 302 dist_a = li.xpath('./a')[0] 303 dist_name = dist_a.xpath('./text()')[0] 304 dist_name = dist_name.strip() 305 # 获取区对应的连接 306 dist_href = dist_a.xpath('./@href')[0] 307 dist_href = dist_href[0].strip() 308 309 # 拼接地址 310 dist_href = root_url + dist_href 311 # 添加到列表中 312 areas.append({ 313 'dist_name': dist_name, 314 'dist_href': dist_href 315 }) 316 317 return areas 318 319 320 def get_area_data(area): 321 # 每次从第一页开始抓取 322 now_page = 1 323 # 存放区县数据 324 area_data = [] 325 # 获取区县链接 326 area_url = area['dist_href'] 327 while True: 328 print('当前{}页'.format(now_page)) 329 # 要抓取的目标地址 330 url = area_url + 'pg{}/'.format(now_page) 331 # 循环请求,直到正确请求到数据才退出 332 while True: 333 try: 334 rsp = requests.get(url=url, headers=headers) 335 break 336 except Exception as e: 337 pass 338 339 # 抓取每一页的信息 340 page_data = get_page(url) 341 for page in page_data: 342 area_data.append(page) 343 # 正则匹配看是否有总页数 344 patt = r'data-totalPage=(\d+) ' 345 sea_res = re.search(patt, rsp.text, re.S) 346 # 判断是否能匹配到数据 347 if sea_res: 348 # 获取总页数 349 page_num = int(sea_res.group(1)) 350 # 判断是否还有下一页 351 if now_page >= page_num: 352 break 353 else: 354 now_page += 1 355 else: 356 break 357 return area_data 358 359 360 def spider(): 361 # 创建excel 362 xls = openpyxl.Workbook() 363 # 激活sheet 364 sheet = xls.active 365 # 先加入标题信息 366 title = ['type', 'county', 'address', 'area', 'orientation', 'room', 'floor', 'price'] 367 # 添加列头 368 sheet.append(title) 369 print("开始爬虫抓取") 370 # 获取区县信息 371 area_list = get_area() 372 # 遍历每一个区县 373 for area in area_list: 374 print('当前抓取区:', area['dist_name']) 375 # 获取区县下的房屋信息 376 area_data = get_area_data(area) 377 # 遍历每一页结果 378 for data in area_data: 379 # 添加到excel中 380 sheet.append(data) 381 # 保存excel文件 382 xls.save('泉州链家数据.xlsx') 383 print("数据抓取完成") 384 385 386 def start(): 387 # 开始爬虫 388 # spider() 389 # 开始可视化 390 huatu() 391 print("全部完成") 392 393 394 root_url = 'https://quanzhou.lianjia.com' 395 # 定义请求头,伪装成浏览器 396 headers = { 397 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 398 'Accept-Language': 'zh,en-US;q=0.9,en;q=0.8,zh-TW;q=0.7,zh-CN;q=0.6', 399 'Host': 'quanzhou.lianjia.com', 400 'Upgrade-Insecure-Requests': '1', 401 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' 402 } 403 # 开始运行 404 start()
四、结论(10分)
1、经过对主题数据的分析与可视化,可以得到哪些结论?
泉州租房信息,价格1000-2000的信息最多,说明需求最多
租房信息房型最热门的是1室1厅一卫,18层和32层的房屋偏多,租房一般是城区,县里很少,城区里丰泽区的信息最多
2、对本次程序设计任务完成的情况做一个简单的小结
首先通过本次程序设计任务,实在太不容易了,查阅了大量资料,翻了很多书上的例子,最终完成,本人首先在编程上学习到了很多知识,学习了几个库的用法,继续加油。