ffmpeg是一个非常有用的命令行程序,它可以用来转码媒体文件。它是领先的多媒体框架FFmpeg的一部分,其有很多功能,比如解码、编码、转码、混流、分离、转化为流、过滤以及播放几乎所有的由人和机器创建的媒体文件。
在这个框架中包含有各种工具,每一个用于完成特定的功能。例如,ffserver能够将多媒体文件转化为用于实时广播的流,ffprobe用于分析多媒体流,ffplay可以当作一个简易的媒体播放器,ffmpeg则能够转换多媒体文件格式。
FFMPEG从功能上划分为几个模块,分别为核心工具(libutils)、媒体格式(libavformat)、编解码(libavcodec)、设备(libavdevice)和后处理(libavfilter, libswscale, libpostproc),分别负责提供公用的功能函数、实现多媒体文件的读包和写包、完成音视频的编解码、管理音视频设备的操作以及进行音视频后处理。
libavutil是一个包含简化编程功能的库,其中包括随机数生成器,数据结构,数学代码,核心多媒体工具等更多东西。
libavcodec是一个包含音频/视频解码器和编码器的库。
libavformat是一个包含了多媒体格式的分离器和混流器的库。
libavdevice是一个包含输入输出设备的库,用于捕捉和渲染很多来自常用的多媒体输入/输出软件框架的数据,包括Video4Linux,Video4Linux2,VfW和ALSA。
libavfilter是一个包含媒体过滤器的库。AVFilter可以给视音频添加各种滤镜效果。可以给视频添加水印,给YUV数据加特效。
libswscale是一个用于执行高度优化的图像缩放和颜色空间/像素格式转换操作的库。
libswresample是一个用于执行高度优化的音频重采样,重新矩阵和取样格式转换操作的库。
在视频解码前,先了解以下几个基本的概念:
编解码器(CODEC):能够进行视频和音频压缩(CO)与解压缩(DEC),是视频编解码的核心部分。
容器/多媒体文件(Container/File):没有了解视频的编解码之前,总是错误的认为平常下载的电影的文件的后缀(avi,mkv,rmvb等)就是视频的编码方式。事实上,刚才提到的几种文件的后缀
并不是视频的编码方式,只是其封装的方式。一个视频文件通常有视频数据、音频数据以及字幕等,封装的格式决定这些数据在文件中是如何的存放的,封装在一起音频、视频等数据组成的多媒体文件,也可以叫做容器(其中包含了视音频数据)。所以,只看多媒体文件的后缀名是难以知道视音频的编码方式的。
流数据 Stream,例如视频流(Video Stream),音频流(Audio Stream)。流中的数据元素被称为帧Frame。一个多媒体文件包含有多个流(视频流 video stream,音频流 audio stream,字幕等);流是一种抽象的概念,表示一连串的数据元素;
流中的数据元素称为帧Frame。
FFMPEG视频解码流程:
通常来说,FFmpeg的视频解码过程有以下几个步骤:
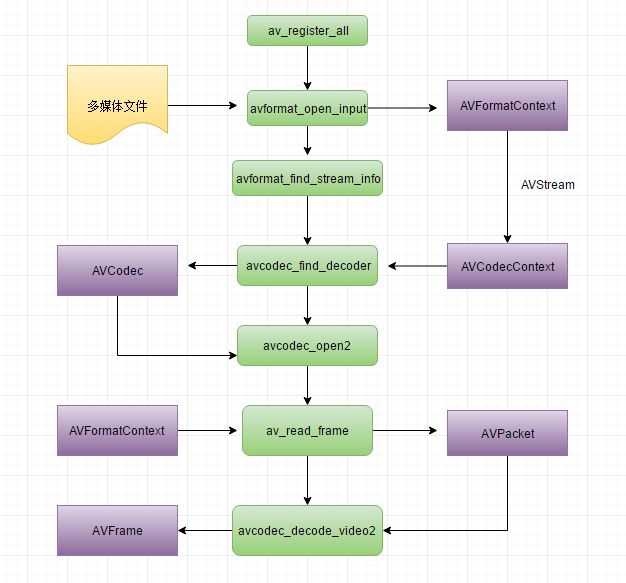
1. 注册所有容器格式及其对应的CODEC: av_register_all()
2. 打开文件: av_open_input_file()
3. 从文件中提取流信息: av_find_stream_info()
4. 穷举所有的流,查找其中种类为CODEC_TYPE_VIDEO的视频流video stream
5. 查找对应的解码器: avcodec_find_decoder()
6. 打开编解码器: avcodec_open2()
7. 为解码帧分配内存: avcodec_alloc_frame()
8. 不停地从码流中提取出帧数据到Packet中: av_read_frame()
9. 判断帧的类型,对于视频帧调用: avcodec_decode_video2()
10. 解码完后,释放解码器: avcodec_close()
11. 关闭输入文件: avformat_close_input_file()
解码过程的具体说明
注册
av_register_all该函数注册支持的所有的文件格式(容器)及其对应的CODEC,只需要调用一次,故一般放在main函数中。也可以注册某个特定的容器格式,但通常来说不需要这么做。-
打开文件
avformat_open_input该函数读取文件的头信息,并将其信息保存到AVFormatContext结构体中。其调用如下AVFormatContext* pFormatCtx = nullptr; avformat_open_input(&pFormatCtx, filenName, nullptr, nullptr)
第一个参数是AVFormatContext结构体的指针,第二个参数为文件路径;第三个参数用来设定输入文件的格式,如果设为null,将自动检测文件格式;第四个参数用来填充AVFormatContext一些字段以及Demuxer的private选项。
AVFormatContext包含有较多的码流信息参数,通常由avformat_open_input创建并填充关键字段。
-
获取必要的CODEC参数
avformat_open_input通过解析多媒体文件或流的头信息及其他的辅助数据,能够获取到足够多的关于文件、流和CODEC的信息,并将这些信息填充到AVFormatContext结构体中。但任何一种多媒体格式(容器)提供的信息都是有限的,而且不同的多媒体制作软件对头信息的设置也不尽相同,在制作多媒体文件的时候难免会引入一些错误。也就是说,仅仅通过avformat_open_input并不能保证能够获取所需要的信息,所以一般要使用avformat_find_stream_info(AVFormatContext *ic, AVDictionary **options) avformat_find_stream_info主要用来获取必要的CODEC参数,设置到ic->streams[i]->codec。
在解码的过程中,首先要获取到各个stream所对应的CODEC类型和id,CODEC的类型和id是两个枚举值,其定义如下:
enum AVMediaType {
AVMEDIA_TYPE_UNKNOWN = -1,
AVMEDIA_TYPE_VIDEO,
AVMEDIA_TYPE_AUDIO,
AVMEDIA_TYPE_DATA,
AVMEDIA_TYPE_SUBTITLE,
AVMEDIA_TYPE_ATTACHMENT,
AVMEDIA_TYPE_NB
};
enum CodecID {
CODEC_ID_NONE, /* video codecs */
CODEC_ID_MPEG1VIDEO,
CODEC_ID_MPEG2VIDEO, ///< preferred ID for MPEG-1/2 video decoding
CODEC_ID_MPEG2VIDEO_XVMC,
CODEC_ID_H261,
CODEC_ID_H263,
...
}
通常,如果多媒体文件具有完整而正确的头信息,通过avformat_open_input即可用获得这两个参数。
-
打开解码器
经过上面的步骤,已经将文件格式信息读取到了AVFormatContext中,要打开流数据相应的CODEC需要经过下面几个步骤
找到视频流 video stream
一个多媒体文件包含有多个原始流,例如 movie.mkv这个多媒体文件可能包含下面的流数据原始流 1 h.264 video 原始流 2 aac audio for Chinese 原始流 3 aac audio for English 原始流 4 Chinese Subtitle 原始流 5 English Subtitle
要解码视频,首先要在AVFormatContext包含的多个流中找到CODEC类型为AVMEDIA_TYPE_VIDEO,代码如下:
//查找视频流 video stream
int videoStream = -1;
for (int i = 0; i < pFormatCtx->nb_streams; i++)
{
if (pFormatCtx->streams[i]->codec->codec_type == AVMEDIA_TYPE_VIDEO)
{
videoStream = i;
break;
}
}
if (videoStream == -1)
return -1; // 没有找到视频流video stream
结构体AVFormatContext中的streams字段是一个AVStream指针的数组,包含了文件所有流的描述,上述上述代码在该数组中查找CODEC类型为
AVMEDIA_TYPE_VIDEO的流的下标。
根据codec_id找到相应的CODEC,并打开结构体AVCodecContext描述了CODEC上下文,包含了众多CODEC所需要的参数信息。
AVCodecContext* pCodecCtxOrg = nullptr;
AVCodec* pCodec = nullptr;
pCodecCtxOrg = pFormatCtx->streams[videoStream]->codec; // codec context
// 找到video stream的 decoder
pCodec = avcodec_find_decoder(pCodecCtxOrg->codec_id);
// open codec
if (avcodec_open2(pCodecCtxOrg , pCodec, nullptr) < 0)
return -1; // Could open codec
上述代码,首先通过codec_id找到相应的CODEC,然后调用avcodec_open2打开相应的CODEC。
-
读取数据帧并解码
已经有了相应的解码器,下面的工作就是将数据从流中读出,并解码为没有压缩的原始数据AVPacket packet; while (av_read_frame(pFormatCtx, &packet) >= 0) { if (packet.stream_index == videoStream) { int frameFinished = 0; avcodec_decode_video2(pCodecCtx, pFrame, &frameFinished, &packet); if (frameFinished) { doSomething(); } } }
上述代码调用av_read_frame将数据从流中读取数据到packet中,并调用avcodec_decode_video2对读取的数据进行解码。
-
关闭
需要关闭avformat_open_input打开的输入流,avcodec_open2打开的CODECavcodec_close(pCodecCtxOrg); avformat_close_input(&pFormatCtx);
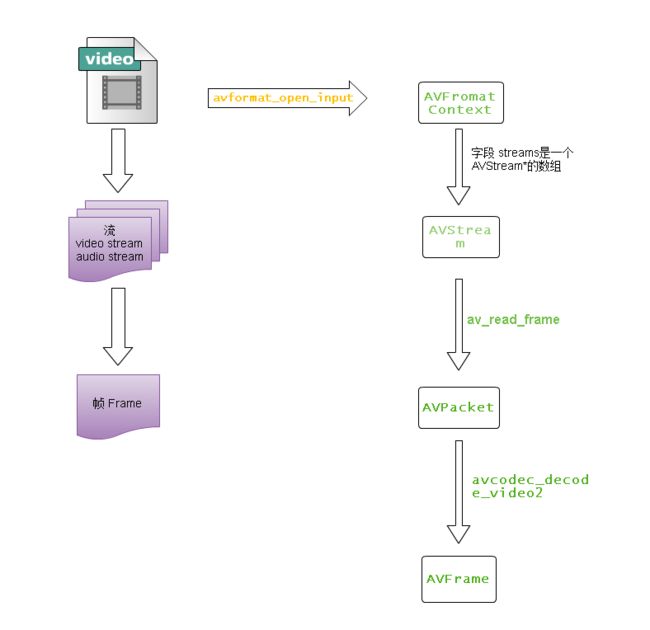
也就是说多媒体文件中,主要有两种数据:流Stream 及其数据元素 帧Frame,在FFmpeg自然有与这两种数据相对应的抽象:AVStream和AVPacket。
使用FFmpeg的解码,数据的传递过程可归纳如下:
调用avformat_open_input打开流,将信息填充到AVFormatContext中
调用av_read_frame从流中读取数据帧到 AVPacket,AVPacket保存仍然是未解码的数据。
调用avcodec_decode_video2将AVPacket的数据解码,并将解码后的数据填充到AVFrame中,AVFrame中保存的是解码后的原始数据。
结构体的存储空间的分配与释放
FFmpeg并没有垃圾回收机制,所分配的空间都需要自己维护。而由于视频处理过程中数据量是非常大,对于动态内存的使用更要谨慎。
本小节主要介绍解码过程使用到的结构体存储空间的分配与释放。
AVFormatContext 在FFmpeg中有很重要的作用,描述一个多媒体文件的构成及其基本信息,存放了视频编解码过程中的大部分信息。通常该结构体由avformat_open_input分配存储空间,在最后调用avformat_input_close关闭。
AVStream 描述一个媒体流,在解码的过程中,作为AVFormatContext的一个字段存在,不需要单独的处理。
AVpacket 用来存放解码之前的数据,它只是一个容器,其data成员指向实际的数据缓冲区,在解码的过程中可有av_read_frame创建和填充AVPacket中的数据缓冲区,
当数据缓冲区不再使用的时候可以调用av_free_apcket释放这块缓冲区。
AVFrame 存放从AVPacket中解码出来的原始数据,其必须通过av_frame_alloc来创建,通过av_frame_free来释放。和AVPacket类似,AVFrame中也有一块数据缓存空间,在调用av_frame_alloc的时候并不会为这块缓存区域分配空间,需要使用其他的方法。在解码的过程使用了两个AVFrame,这两个AVFrame分配缓存空间的方法也不相同
一个AVFrame用来存放从AVPacket中解码出来的原始数据,这个AVFrame的数据缓存空间通过调avcodec_decode_video分配和填充。
另一个AVFrame用来存放将解码出来的原始数据变换为需要的数据格式(例如RGB,RGBA)的数据,这个AVFrame需要手动的分配数据缓存空间。代码如下:
AVFrame *pFrameYUV;
pFrameYUV = av_frame_alloc();
// 手动为 pFrameYUV分配数据缓存空间
int numBytes = avpicture_get_size(AV_PIX_FMT_YUV420P,pCodecCtx->widht,pCodecCtx->width);
uint8_t *buffer = (uint8_t*)av_malloc(numBytes * sizeof(uint8_t));
// 将分配的数据缓存空间和AVFrame关联起来
avpicture_fill((AVPicture *)pFrameYUV, buffer, AV_PIX_FMT_YUV420P,pCodecCtx->width, pCodecCtx->height)
首先计算需要缓存空间大小,调用av_malloc分配缓存空间,最后调用avpicture_fill将分配的缓存空间和AVFrame关联起来。
调用av_frame_free来释放AVFrame,该函数不止释放AVFrame本身的空间,还会释放掉包含在其内的其他对象动态申请的空间,例如上面的缓存空间。
av_malloc和av_free,FFmpeg并没有提供垃圾回收机制,所有的内存管理都要手动进行。av_malloc只是在申请内存空间的时候会考虑到内存对齐(2字节,4字节对齐),
其申请的空间要调用av_free释放。
调用的函数
av_register_all 这个函数不用多说了,注册库所支持的容器格式及其对应的CODEC。
avformat_open_input 打开多媒体文件流,并读取文件的头,将读取到的信息填充到AVFormatContext结构体中。在使用结束后,要调用avformat_close_input关闭打开的流
avformat_find_stream_info 上面提到,avformat_open_input只是读取文件的头来得到多媒体文件的信息,但是有些文件没有文件头或者文件头的格式不正确,这就造成只调用
avformat_open_input可能得不到解码所需要的必要信息,需要调用avformat_find_stream_info进一步得到流的信息。
通过上面的三个函数已经获取了对多媒体文件进行解码的所需要信息,下面要做的就是根据这些信息得到相应的解码器。
结构体AVCodecContext描述了编解码器的上下文信息,包含了流中所使用的关于编解码器的所有信息,可以通过 AVFormatContext->AVStream->AVCodecContext来得到,在有了AVCodecContext后,可以通过codec_id来找到相应的解码器,具体代码如下:
AVCodec* pCodec = nullptr;
pCodecCtxOrg = pFormatCtx->streams[videoStream]->codec; // codec context
// 找到video stream的 decoder
pCodec = avcodec_find_decoder(pCodecCtxOrg->codec_id);
avcodec_find_decoder 可以通过codec_id或者名称来找到相应的解码器,返回值是一个AVCodec的指针。
avcodec_open2 打开相应的编解码器
av_read_frame 从流中读取数据帧暂存到AVPacket中
avcodec_decode_video2 从AVPacket中解码数据到AVFrame中
经过以上的过程,AVFrame中的数据缓存中存放的就是解码后的原始数据了。整个流程梳理如下:
(1)RGB转换成YUV
Y = 0.299R + 0.587G + 0.114B
U = 0.567(B - Y)
V = 0.713(R - Y)
值得注意的是,Y值范围为[0, 1.0]、UV值范围都是[-0.5, 0.5],在Accelerate框架的vImage_CVUtilities.h有描述。
(2)YUV转换成RGB
R = Y + 1.402V
G = Y - 0.344U - 0.714V
B = Y + 1.772U
视音频技术主要包含以下几点:封装技术,视频压缩编码技术以及音频压缩编码技术。如果考虑到网络传输的话,还包括流媒体协议技术。
视频播放器播放一个互联网上的视频文件,需要经过以下几个步骤:解协议,解封装,解码视音频,视音频同步。
解协议的作用,就是将流媒体协议的数据,解析为标准的相应的封装格式数据。视音频在网络上传播的时候,常常采用各种流媒体协议,例如HTTP,RTMP,或是MMS等等。这些协议在传输视音频数据的同时,也会传输一些信令数据。这些信令数据包括对播放的控制(播放,暂停,停止),或者对网络状态的描述等。解协议的过程中会去除掉信令数据而只保留视音频数据。例如,采用RTMP协议传输的数据,经过解协议操作后,输出FLV格式的数据。
解封装的作用,就是将输入的封装格式的数据,分离成为音频流压缩编码数据和视频流压缩编码数据。封装格式种类很多,例如MP4,MKV,RMVB,TS,FLV,AVI等等,它的作用就是将已经压缩编码的视频数据和音频数据按照一定的格式放到一起。例如,FLV格式的数据,经过解封装操作后,输出H.264编码的视频码流和AAC编码的音频码流。
解码的作用,就是将视频/音频压缩编码数据,解码成为非压缩的视频/音频原始数据。音频的压缩编码标准包含AAC,MP3,AC-3等等,视频的压缩编码标准则包含H.264,MPEG2,VC-1等等。解码是整个系统中最重要也是最复杂的一个环节。通过解码,压缩编码的视频数据输出成为非压缩的颜色数据,例如YUV420P,RGB等等;压缩编码的音频数据输出成为非压缩的音频抽样数据,例如PCM数据。
视音频同步的作用,就是根据解封装模块处理过程中获取到的参数信息,同步解码出来的视频和音频数据,并将视频音频数据送至系统的显卡和声卡播放出来。
一般来说,视频同步指的是视频和音频同步,也就是说播放的声音要和当前显示的画面保持一致。想象以下,看一部电影的时候只看到人物嘴动没有声音传出;或者画面是激烈的战斗场景,而声音不是枪炮声却是人物说话的声音,这是非常差的一种体验。
在视频流和音频流中已包含了其以怎样的速度播放的相关数据,视频的帧率(Frame Rate)指示视频一秒显示的帧数(图像数);音频的采样率(Sample Rate)表示音频一秒播放的样本(Sample)的个数。可以使用以上数据通过简单的计算得到其在某一Frame(Sample)的播放时间,以这样的速度音频和视频各自播放互不影响,在理想条件下,其应该是同步的,不会出现偏差。但,理想条件是什么大家都懂得。如果用上面那种简单的计算方式,慢慢的就会出现音视频不同步的情况。要不是视频播放快了,要么是音频播放快了,很难准确的同步。这就需要一种随着时间会线性增长的量,视频和音频的播放速度都以该量为标准,播放快了就减慢播放速度;播放快了就加快播放的速度。所以呢,视频和音频的同步实际上是一个动态的过程,同步是暂时的,不同步则是常态。以选择的播放速度量为标准,快的等待慢的,慢的则加快速度,是一个你等我赶的过程。
播放速度标准量的的选择一般来说有以下三种:
将视频同步到音频上,就是以音频的播放速度为基准来同步视频。视频比音频播放慢了,加快其播放速度;快了,则延迟播放。
将音频同步到视频上,就是以视频的播放速度为基准来同步音频。
将视频和音频同步外部的时钟上,选择一个外部时钟为基准,视频和音频的播放速度都以该时钟为标准。
DTS和PTS
上面提到,视频和音频的同步过程是一个你等我赶的过程,快了则等待,慢了就加快速度。这就需要一个量来判断(和选择基准比较),到底是播放的快了还是慢了,或者正以同步的速度播放。在视音频流中的包中都含有DTS和PTS,就是这样的量(准确来说是PTS)。DTS,Decoding Time Stamp,解码时间戳,告诉解码器packet的解码顺序;PTS,Presentation Time Stamp,显示时间戳,指示从packet中解码出来的数据的显示顺序。
视音频都是顺序播放的,其解码的顺序不应该就是其播放的顺序么,为啥还要有DTS和PTS之分呢。对于音频来说,DTS和PTS是相同的,也就是其解码的顺序和解码的顺序是相同的,但对于视频来说情况就有些不同了。
视频的编码要比音频复杂一些,特别的是预测编码是视频编码的基本工具,这就会造成视频的DTS和PTS的不同。这样视频编码后会有三种不同类型的帧:
I帧 关键帧,包含了一帧的完整数据,解码时只需要本帧的数据,不需要参考其他帧。
P帧 P是向前搜索,该帧的数据不完全的,解码时需要参考其前一帧的数据。
B帧 B是双向搜索,解码这种类型的帧是最复杂,不但需要参考其一帧的数据,还需要其后一帧的数据。
I帧的解码是最简单的,只需要本帧的数据;P帧也不是很复杂,值需要缓存上一帧的数据即可,总体来说都是线性,其解码顺序和显示顺序是一致的。B帧就比较复杂了,需要前后两帧的顺序,并且不是线性的,也是造成了DTS和PTS的不同的“元凶”,也是在解码后有可能得不到完整Frame的原因。(更多I,B,P帧的信息可参考)
假如一个视频序列,要这样显示I B B P,但是需要在B帧之前得到P帧的信息,因此帧可能以这样的顺序来存储I P B B,这样其解码顺序和显示的顺序就不同了,这也是DTS和PTS同时存在的原因。DTS指示解码顺序,PTS指示显示顺序。所以流中可以是这样的:
Stream : I P B B
DTS 1 2 3 4
PTS 1 4 2 3
通常来说只有在流中含有B帧的时候,PTS和DTS才会不同。