本文根据Apache Flink 实战&进阶篇系列直播课程整理而成,由哈啰出行大数据实时平台资深开发刘博分享。通过一些简单的实际例子,从概念原理,到如何使用,再到功能的扩展,希望能够给打算使用或者已经使用的同学一些帮助。
主要的内容分为如下三个部分:
- Flink CEP概念以及使用场景。
- 如何使用Flink CEP。
- 如何扩展Flink CEP。
Flink CEP 概念以及使用场景
什么是 CEP
CEP的意思是复杂事件处理,例如:起床-->洗漱-->吃饭-->上班等一系列串联起来的事件流形成的模式称为CEP。如果发现某一次起床后没有刷牙洗脸亦或是吃饭就直接上班,就可以把这种非正常的事件流匹配出来进行分析,看看今天是不是起晚了。
下图中列出了几个例子:

- 第一个是异常行为检测的例子:假设车辆维修的场景中,当一辆车出现故障时,这辆车会被送往维修点维修,然后被重新投放到市场运行。如果这辆车被投放到市场之后还未被使用就又被报障了,那么就有可能之前的维修是无效的。
- 第二个是策略营销的例子:假设打车的场景中,用户在APP上规划了一个行程订单,如果这个行程在下单之后超过一定的时间还没有被司机接单的话,那么就需要将这个订单输出到下游做相关的策略调整。
- 第三个是运维监控的例子:通常运维会监控服务器的CPU、网络IO等指标超过阈值时产生相应的告警。但是在实际使用中,后台服务的重启、网络抖动等情况都会造成瞬间的流量毛刺,对非关键链路可以忽略这些毛刺而只对频繁发生的异常进行告警以减少误报。
Flink CEP 应用场景
- 风险控制:对用户异常行为模式进行实时检测,当一个用户发生了不该发生的行为,判定这个用户是不是有违规操作的嫌疑。
- 策略营销:用预先定义好的规则对用户的行为轨迹进行实时跟踪,对行为轨迹匹配预定义规则的用户实时发送相应策略的推广。
- 运维监控:灵活配置多指标、多依赖来实现更复杂的监控模式。
Flink CEP原理

Flink CEP内部是用NFA(非确定有限自动机)来实现的,由点和边组成的一个状态图,以一个初始状态作为起点,经过一系列的中间状态,达到终态。点分为起始状态、中间状态、最终状态三种,边分为take、ignore、proceed三种。
- take:必须存在一个条件判断,当到来的消息满足take边条件判断时,把这个消息放入结果集,将状态转移到下一状态。
- ignore:当消息到来时,可以忽略这个消息,将状态自旋在当前不变,是一个自己到自己的状态转移。
- proceed:又叫做状态的空转移,当前状态可以不依赖于消息到来而直接转移到下一状态。举个例子,当用户购买商品时,如果购买前有一个咨询客服的行为,需要把咨询客服行为和购买行为两个消息一起放到结果集中向下游输出;如果购买前没有咨询客服的行为,只需把购买行为放到结果集中向下游输出就可以了。 也就是说,如果有咨询客服的行为,就存在咨询客服状态的上的消息保存,如果没有咨询客服的行为,就不存在咨询客服状态的上的消息保存,咨询客服状态是由一条proceed边和下游的购买状态相连。
下面以一个打车的例子来展示状态是如何流转的,规则见下图所示。

以乘客制定行程作为开始,匹配乘客的下单事件,如果这个订单超时还没有被司机接单的话,就把行程事件和下单事件作为结果集往下游输出。
假如消息到来顺序为:行程-->其他-->下单-->其他。
状态流转如下:
1、开始时状态处于行程状态,即等待用户制定行程。

2、当收到行程事件时,匹配行程状态的条件,把行程事件放到结果集中,通过take边将状态往下转移到下单状态。

3、由于下单状态上有一条ignore边,所以可以忽略收到的其他事件,直到收到下单事件时将其匹配,放入结果集中,并且将当前状态往下转移到超时未接单状态。这时候结果集当中有两个事件:制定行程事件和下单事件。


4、超时未接单状态时,如果来了一些其他事件,同样可以被ignore边忽略,直到超时事件的触发,将状态往下转移到最终状态,这时候整个模式匹配成功,最终将结果集中的制定行程事件和下单事件输出到下游。

上面是一个匹配成功的例子,如果是不成功的例子会怎么样?
假如当状态处于超时未接单状态时,收到了一个接单事件,那么就不符合超时未被接单的触发条件,此时整个模式匹配失败,之前放入结果集中的行程事件和下单事件会被清理。

Flink CEP程序开发
本节将详细介绍Flink CEP的程序结构以及API。
Flink CEP 程序结构
主要分为两部分:定义事件模式和匹配结果处理。
官方示例如下:

程序结构分为三部分:首先需要定义一个模式(Pattern),即第2行代码所示,接着把定义好的模式绑定在DataStream上(第25行),最后就可以在具有CEP功能的DataStream上将匹配的结果进行处理(第27行)。
下面对关键部分做详细讲解:
定义模式:上面示例中,分为了三步,首先匹配一个ID为42的事件,接着匹配一个体积大于等于10的事件,最后等待收到一个name等于end的事件。
匹配结果输出:此部分,需要重点注意select函数(第30行,注:本文基于Flink 1.7版本)里边的Map类型的pattern参数,Key是一个pattern的name,它的取值是模式定义中的Begin节点start,或者是接下来next里面的middle,或者是第三个步骤的end。后面的map中的value是每一步发生的匹配事件。因在每一步中是可以使用循环属性的,可以匹配发生多次,所以map中的value是匹配发生多次的所有事件的一个集合。
Flink CEP构成

上图中,蓝色方框代表的是一个个单独的模式;浅黄色的椭圆代表的是这个模式上可以添加的属性,包括模式可以发生的循环次数,或者这个模式是贪婪的还是可选的;橘色的椭圆代表的是模式间的关系,定义了多个模式之间是怎么样串联起来的。通过定义模式,添加相应的属性,将多个模式串联起来三步,就可以构成了一个完整的Flink CEP程序。
定义模式
下面是示例代码:

定义模式主要有如下5个部分组成:
pattern:前一个模式
next/followedBy/...:开始一个新的模式
start:模式名称
where:模式的内容
filter:核心处理逻辑
模式的属性
接下来介绍一下怎样设置模式的属性。模式的属性主要分为循环属性和可选属性。
循环属性可以定义模式匹配发生固定次数(times),匹配发生一次以上(oneOrMore),匹配发生多次以上。(timesOrMore)。
可选属性可以设置模式是贪婪的(greedy),即匹配最长的串,或设置为可选的(optional),有则匹配,无则忽略。
模式的有效期
由于模式的匹配事件存放在状态中进行管理,所以需要设置一个全局的有效期(within)。 若不指定有效期,匹配事件会一直保存在状态中不会被清除。至于有效期能开多大,要依据具体使用场景和数据量来衡量,关键要看匹配的事件有多少,随着匹配的事件增多,新到达的消息遍历之前的匹配事件会增加CPU、内存的消耗,并且随着状态变大,数据倾斜也会越来越严重。
模式间的联系
主要分为三种:严格连续性(next/notNext),宽松连续性(followedBy/notFollowedBy),和非确定宽松连续性(followedByAny)。
三种模式匹配的差别见下表所示:

总结如下:
- 严格连续性:需要消息的顺序到达与模式完全一致。
- 宽松连续性:允许忽略不匹配的事件。
- 非确定宽松连性:不仅可以忽略不匹配的事件,也可以忽略已经匹配的事件。
多模式组合
除了前面提到的模式定义和模式间的联系,还可以把相连的多个模式组合在一起看成一个模式组,类似于视图,可以在这个模式视图上进行相关操作。
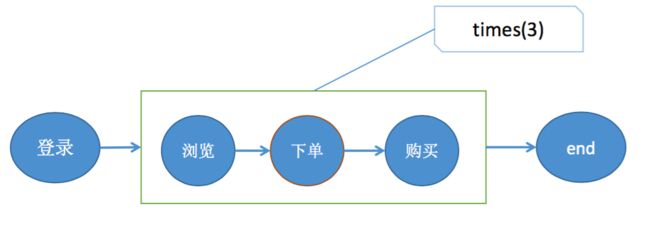
上图这个例子里面,首先匹配了一个登录事件,然后接下来匹配浏览,下单,购买这三个事件反复发生三次的用户。
如果没有模式组的话,代码里面浏览,下单,购买要写三次。有了模式组,只需把浏览,下单,购买这三个事件当做一个模式组,把相应的属性加上times(3)就可以了。
处理结果
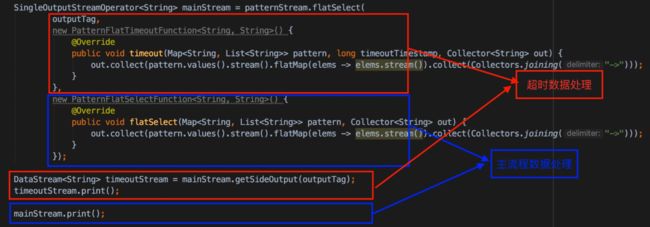
处理匹配的结果主要有四个接口: PatternFlatSelectFunction,PatternSelectFunction,PatternFlatTimeoutFunction和PatternTimeoutFunction。
从名字上可以看出,输出可以分为两类:select和flatSelect指定输出一条还是多条,timeoutFunction和不带timeout的Function指定可不可以对超时事件进行旁路输出。
下图是输出的综合示例代码:
状态存储优化
当一个事件到来时,如果这个事件同时符合多个输出的结果集,那么这个事件是如何保存的?
Flink CEP通过Dewey计数法在多个结果集共享同一个事件副本,以实现对事件副本进行资源共享。

Flink CEP的扩展
本章主要介绍一些Flink CEP的扩展,讲述如何做到超时机制的精确管理,以及规则的动态加载与更新。
超时触发机制扩展
原生Flink CEP中超时触发的功能可以通过within+outputtag结合来实现,但是在复杂的场景下处理存在问题,如下图所示,在下单事件后还有一个预付款事件,想要得到下单并且预付款后超时未被接单的订单,该如何表示呢?

参照下单后超时未被接单的做法,把下单并且预付款后超时未被接单规则表示为下单.followedBy(预付款).followedBy(接单).within(time),那么这样实现会存在问题吗?
这种做法的计算结果是会存在脏数据的,因为这个规则不仅匹配到了下单并且预付款后超时未被接单的订单(想要的结果),同样还匹配到了只有下单行为后超时未被接单的订单(脏数据,没有预付款)。原因是因为超时within是控制在整个规则上,而不是某一个状态节点上,所以不论当前的状态是处在哪个状态节点,超时后都会被旁路输出。
那么就需要考虑能否通过时间来直接对状态转移做到精确的控制,而不是通过规则超时这种曲线救国的方式。 于是乎,在通过消息触发状态的转移之外,需要增加通过时间触发状态的转移的支持。要实现此功能,需要在原来的状态以及状态转移中,增加时间属性的概念。如下图所示,通过wait算子来得到waiting状态,然后在waiting状态上设置一个十秒的时间属性以定义一个十秒的时间窗口。

wait算子对应NFA中的ignore状态,将在没有到达时间窗口结束时间时自旋,在ComputationState中记录wait的开始时间,在NFA的doProcess中,将到来的数据与waiting状态处理,如果到了waiting的结束时间,则进行状态转移。
上图中红色方框中为waiting状态设置了两条ignore边:
1.waitingStatus.addIgnore(lastSink,waitingCondition),waitingCondition中的逻辑是获取当前的时间(支持事件时间),判断有没有超过设置的waiting阈值,如果超过就把状态向后转移。
2.waitingStatus.addIgnore(waitingCondition),waitingCondition中如果未达到设置的waiting阈值,就会自旋在当前的waiting状态不变。
规则动态注入
线上运行的CEP中肯定经常遇到规则变更的情况,如果每次变更时都将任务重启、重新发布是非常不优雅的。尤其在营销或者风控这种对实时性要求比较高的场景,如果规则窗口过长(一两个星期),状态过大,就会导致重启时间延长,期间就会造成一些想要处理的异常行为不能及时发现。
那么要怎么样做到规则的动态更新和加载呢?

梳理一下整体架构,Flink CEP是运行在Flink Job里的,而规则库是放在外部存储中的。首先,需要在运行的Job中能及时发现外部存储中规则的变化,即需要在Job中提供访问外部库的能力。 其次,需要将规则库中变更的规则动态加载到CEP中,即把外部规则的描述解析成Flink CEP所能识别的pattern结构体。最后,把生成的pattern转化成NFA,替换历史NFA,这样对新到来的消息,就会使用新的规则进行匹配。
下图就是一个支持将外部规则动态注入、更新的接口。

这个接口里面主要实现了四个方法:
- initialize:初始化方法,进行外部库连接的初始化。
- inject:和外部数据库交互的主要方法,监听外部库变化,获取最新的规则并通过Groovy动态加载,返回pattern。
- getPeriod:设置轮巡周期,在一些比较简单的实时性要求不高的场景,可以采用轮巡的方式,定期对外部数据库进行检测。
- getNfaKeySelector:和动态更新无关,用来支持一个流对应多个规则组。
历史匹配结果清理
新规则动态加载到Flink CEP的Job中,替换掉原来的NFA之后,还需要对历史匹配的结果集进行清理。在AbstractKeyedCEPPatternOperator中实现刷新NFA,注意,历史状态是否需要清理和业务相关:
- 修改的逻辑对规则中事件的匹配没有影响,保留历史结果集中的状态。
- 修改的逻辑影响到了之前匹配的部分,需要将之前匹配的结果集中的状态数据清除,防止错误的输出。


总结
使用Flink CEP,熟知其原理是很重要的,特别是NFA的状态转移流程,然后再去看源码中的状态图的构建就会很清晰了。
本文作者:巴蜀真人
原文链接
本文为阿里云内容,未经允许不得转载。