【Chapter 4】 NumPy基础:数组和矢量计算
使用 Python 进行科学计算:NumPy入门
NumPy本身并没有提供多么高级的数据分析功能,理解NumPy数组以及面向数组的计算将有助于你更加高效地使用诸如pandas之类的工具。
对于大部分数据分析应用而言,我最关注的功能主要集中在:
- 用于数据整理和清理、子集构造和过滤、转换等快速的矢量化数组运算。
- 常用的数组算法,如排序、唯一化、集合运算等。
- 高效的描述统计和数据聚合/摘要运算。
- 用于异构数据集的合并/连接运算的数据对齐和关系型数据运算。
- 将条件逻辑表述为数组表达式(而不是带有if-elif-else分支的循环)。
- 数据的分组运算(聚合、转换、函数应用等)。。
虽然NumPy提供了通用的数值数据处理的计算基础,但大多数读者可能还是想将pandas作为统计和分析工作的基础,尤其是处理表格数据时。pandas还提供了一些NumPy所没有的更加领域特定的功能,如时间序列处理等。
NumPy之于数值计算特别重要的原因之一,是因为它可以高效处理大数组的数据。这是因为:
- NumPy是在一个连续的内存块中存储数据,独立于其他Python内置对象。NumPy的C语言编写的算法库可以操作内存,而不必进行类型检查或其它前期工作。比起Python的内置序列,NumPy数组使用的内存更少。
- NumPy可以在整个数组上执行复杂的计算,而不需要Python的for循环。
要搞明白具体的性能差距,考察一个包含一百万整数的数组,和一个等价的Python列表:
In [7]: import numpy as np
In [8]: my_arr = np.arange(1000000)
In [9]: my_list = list(range(1000000))
各个序列分别乘以2:
In [10]: %time for _ in range(10): my_arr2 = my_arr * 2
CPU times: user 20 ms, sys: 50 ms, total: 70 ms
Wall time: 72.4 ms
In [11]: %time for _ in range(10): my_list2 = [x * 2 for x in my_list]
CPU times: user 760 ms, sys: 290 ms, total: 1.05 s
Wall time: 1.05 s
基于NumPy的算法要比纯Python快10到100倍(甚至更快),并且使用的内存更少。
4.1 NumPy的ndarray:一种多维数组对象
NumPy最重要的一个特点就是其N维数组对象(即ndarray),该对象是一个快速而灵活的大数据集容器。你可以利用这种数组对整块数据执行一些数学运算,其语法跟标量元素之间的运算一样。
要明白Python是如何利用与标量值类似的语法进行批次计算,我先引入NumPy,然后生成一个包含随机数据的小数组:
import numpy as np
data = np.random.randn(2,3)
data
Out[210]:
array([[-1.08335704, 0.10430985, 0.1606809 ],
[ 1.34537474, -1.19032319, -1.14856331]])
#进行计算
data * 10
Out[212]:
array([[-10.8335704 , 1.04309853, 1.60680899],
[ 13.45374739, -11.90323192, -11.48563308]])
data + data
Out[213]:
array([[-2.16671408, 0.20861971, 0.3213618 ],
[ 2.69074948, -2.38064638, -2.29712662]])
第一个例子中,所有的元素都乘以10。第二个例子中,每个元素都与自身相加。
笔记:在本章及全书中,我会使用标准的NumPy惯用法
import numpy as np。你当然也可以在代码中使用from numpy import *,但不建议这么做。numpy的命名空间很大,包含许多函数,其中一些的名字与Python的内置函数重名(比如min和max)。
ndarray是一个通用的同构数据多维容器,也就是说,其中的所有元素必须是相同类型的。每个数组都有一个数组的形状(shape)是指它有多少行和列 和一个dtype(一个用于说明数组数据类型的对象):
In [214]: data.shape
Out[214]: (2, 3)
In [215]: data.dtype
Out[215]: dtype('float64')
本章将会介绍NumPy数组的基本用法,这对于本书后面各章的理解基本够用。虽然大多数数据分析工作不需要深入理解NumPy,但是精通面向数组的编程和思维方式是成为Python科学计算牛人的一大关键步骤。
笔记:当你在本书中看到“数组”、“NumPy数组”、"ndarray"时,基本上都指的是同一样东西,即ndarray对象。
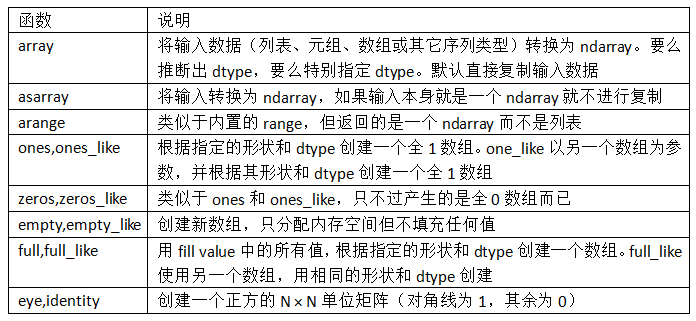
Greating ndarrays (创建n维数组)
创建数组最简单的办法就是使用array函数。它接受一切序列型的对象(包括其他数组),然后产生一个新的含有传入数据的NumPy数组。以一个列表的转换为例:
In [219]: data1 = [6,7.5,8,0,1]
In [220]: arr1=np.array(data)
In [221]: arr1
Out[221]: array([6. , 7.5, 8. , 0. , 1. ])
嵌套序列能被转换为多维数组:
data2 = [[1, 2, 3, 4], [5, 6, 7, 8]]
arr2 = np.array(data2)
arr2
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
因为data2是一个list of lists, 所以arr2维度为2。我们能用ndim和shape属性来确认一下:
#'ndim' 属性是指数组有多少维
In [25]: arr2.ndim
Out[25]: 2
In [26]: arr2.shape
Out[26]: (2, 4)
除np.array之外,还有一些函数也可以新建数组。比如,zeros和ones分别可以创建指定长度或形状的全0或全1数组。empty可以创建一个没有任何具体值的数组。要用这些方法创建多维数组,只需传入一个表示形状的元组即可:
In [223]: np.zeros(10)
Out[223]: array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
In [224]: np.zeros((3,6))
Out[224]:
array([[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]])
In [225]: np.empty((2,3,2))
Out[225]:
array([[[8.38955552e-312, 3.16202013e-322],
[0.00000000e+000, 0.00000000e+000],
[0.00000000e+000, 4.42436408e-062]],
[[2.58453781e-057, 2.37900058e+184],
[1.86386951e+160, 3.40558559e+175],
[3.40609302e-057, 6.28850449e-066]]])
注意:认为np.empty会返回全0数组的想法是不安全的。很多情况下(如前所示),它返回的都是一些未初始化的垃圾值。
arange是Python内置函数range的数组版:
np.arange(15)
Out[227]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
2. ndarray的数据类型
dtype(数据类型)是一个特殊的对象,它含有ndarray将一块内存解释为特定数据类型所需的信息:
arr1 = np.array([1,2,3],dtype=np.float64)
array2 = np.array([1,2,3],dtype=np.int32)
arr1.dtype
Out[232]: dtype('float64')
array2.dtype
Out[234]: dtype('int32')
#用astype把string里的数字变为实际的数字:
In [236]: numeric_strings = np.array(['1.25', '-9.6', '42'], dtype=np.string_)
...: numeric_strings
...:
Out[236]: array([b'1.25', b'-9.6', b'42'], dtype='|S4')
In [237]: numeric_strings.astype(float)
Out[237]: array([ 1.25, -9.6 , 42. ])
要十分注意numpy.string_类型,这种类型的长度是固定的,所以可能会直接截取部分输入而不给警告。
如果转换(casting)失败的话,会给出一个ValueError提示。
数组的dtype还有另一个属性:
In [240]: int_array = np.arange(10)
In [241]: calibers = np.array([.22, .270, .357, .380, .44, .50], dtype=np.float64)
In [242]: int_array.astype(calibers.dtype)
Out[242]: array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
还可以利用类型的缩写,比如u4就代表unit32:
empty_unit32 = np.empty(8, dtype='u4')
empty_unit32
array([0, 0, 0, 0, 0, 0, 0, 0], dtype=uint32)
记住,astype总是会返回一个新的数组
笔记:记不住这些NumPy的dtype也没关系,新手更是如此。通常只需要知道你所处理的数据的大致类型是浮点数、复数、整数、布尔值、字符串,还是普通的Python对象即可。当你需要控制数据在内存和磁盘中的存储方式时(尤其是对大数据集),那就得了解如何控制存储类型。
3. NumPy数组的运算
数组很重要,因为它使你不用编写循环即可对数据执行批量运算。NumPy用户称其为矢量化(vectorization)。任何两个大小相等的数组之间的运算,都是element-wise(点对点):
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
arr
Out[245]:
array([[1., 2., 3.],
[4., 5., 6.]])
arr * arr
Out[246]:
array([[ 1., 4., 9.],
[16., 25., 36.]])
arr - arr
Out[247]:
array([[0., 0., 0.],
[0., 0., 0.]])
数组与标量的算术运算会将标量值传播到各个元素:
In [55]: 1 / arr
Out[55]:
array([[ 1. , 0.5 , 0.3333],
[ 0.25 , 0.2 , 0.1667]])
In [56]: arr ** 0.5
Out[56]:
array([[ 1. , 1.4142, 1.7321],
[ 2. , 2.2361, 2.4495]])
大小相同的数组之间的比较会生成布尔值数组:
In [57]: arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])
In [58]: arr2
Out[58]:
array([[ 0., 4., 1.],
[ 7., 2., 12.]])
In [59]: arr2 > arr
Out[59]:
array([[False, True, False],
[ True, False, True]], dtype=bool)
4. Basic Indexing and Slicing(基本的索引和切片)
NumPy数组的索引是一个内容丰富的主题,因为选取数据子集或单个元素的方式有很多。一维数组很简单。从表面上看,它们跟Python列表的功能差不多:
In [60]: arr = np.arange(10)
In [61]: arr
Out[61]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [62]: arr[5]
Out[62]: 5
In [63]: arr[5:8]
Out[63]: array([5, 6, 7])
In [64]: arr[5:8] = 12
In [65]: arr
Out[65]: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
这里把12赋给arr[5:8],其实用到了broadcasted(我觉得应该翻译为广式转变)。这里有一个比较重要的概念需要区分,python内建的list与numpy的array有个明显的区别,这里array的切片后的结果只是一个views(视图),用来代表原有array对应的元素,而不是创建了一个新的array。但list里的切片是产生了一个新的list:
arr
Out[65]: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
arr_slice = arr[5:8]
arr_slice
array([12, 12, 12])
#如果我们改变arr_slice的值,会反映在原始的数组arr上:
arr_slice[1] = 12345
arr
array([ 0, 1, 2, 3, 4, 12, 12345, 12, 8, 9])
#[:]这个赋值给所有元素:
arr_slice[:] = 64
arr
array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
之所以这样设计是出于性能和内存的考虑,毕竟如果总是复制数据的话,会很影响运算时间。当然如果想要复制,可以使用copy()方法,比如arr[5:8].copy()
在一个二维数组里,单一的索引指代的是一维的数组:
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
arr2d[2]
Out[252]: array([7, 8, 9])
有两种方式可以访问单一元素:
Out[252]: array([7, 8, 9])
arr2d[0][2]
Out[253]: 3
arr2d[0,2]
Out[254]: 3
对于多维数组,如果省略后面的索引,返回的将是一个低纬度的多维数组。比如下面一个2 x 2 x 3数组:
arr3d = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
arr3d
Out[267]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
arr3d[0]是一个2x3数组:
arr3d[0]
Out[265]:
array([[1, 2, 3],
[4, 5, 6]])
标量和数组都能赋给arr3d[0]:
old_values = arr3d[0].copy()
arr3d[0] = 42
arr3d
Out[268]:
array([[[42, 42, 42],
[42, 42, 42]],
[[ 7, 8, 9],
[10, 11, 12]]])
arr3d[0] = old_values
arr3d
Out[269]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
arr3d[1, 0]会给你一个(1, 0)的一维数组:
arr3d[1,0]
Out[270]: array([7, 8, 9])
上面的一步等于下面的两步:
x = arr3d[1]
x
Out[271]:
array([[ 7, 8, 9],
[10, 11, 12]])
x[0]
Out[272]: array([7, 8, 9])
一定要牢记这些切片后返回的数组都是views
Indexing with slices(用切片索引)
一维的话和python里的list没什么差别, 二维的话,数组的切片有点不同:
arr2d[:2]
Out[274]:
array([[1, 2, 3],
[4, 5, 6]])
arr2d
Out[275]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
可以看到,切片是沿着axis 0(行)来处理的。所以,数组中的切片,是要沿着设置的axis来处理的。我们可以把arr2d[:2]理解为“选中arr2d的前两行”。
当然,给定多个索引后,也可以使用复数切片
arr2d
Out[276]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
arr2d[:2,1:]# 前两行,第二列之后
Out[277]:
array([[2, 3],
[5, 6]])
记住,选中的是array view。通过混合整数和切片,能做低维切片。比如,我们选中第二行的前两列:
arr2d[1,:2]
Out[278]: array([4, 5])
#选中第三列的前两行:
arr2d[:2, 2]
Out[279]: array([3, 6])
#冒号表示提取整个axis(轴):
arr2d[:, :1]
Out[280]:
array([[1],
[4],
[7]])

自然,对切片表达式的赋值操作也会被扩散到整个选区:
arr2d[:2,1:] = 0
arr2d
Out[283]:
array([[1, 0, 0],
[4, 0, 0],
[7, 8, 9]])
5. 布尔型索引
假设我们的数组数据里有一些重复。这里我们用numpy.random里的randn函数来随机生成一些离散数据:
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
names
Out[285]: array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='假设每个名字都对应data数组中的一行,而我们想要选出对应于名字"Bob"的所有行。跟算术运算一样,数组的比较运算(如==)也是矢量化的。因此,对names和字符串"Bob"的比较运算将会产生一个布尔型数组:
names == 'Bob'
Out[290]: array([ True, False, False, True, False, False, False])
#这个布尔型数组可用于数组索引:
data[names == 'Bob']
Out[292]:
array([[ 0.79464532, 1.82956019, -0.72248023, -0.95578708],
[-0.88922371, -1.11102412, 0.00290218, 0.49031693]])
注意:布尔数组和data数组的长度要一样。
我们可以选中names=='Bob'的行,然后索引了列:
data[names == 'Bob', 2:]
Out[293]:
array([[-0.72248023, -0.95578708],
[ 0.00290218, 0.49031693]])
data[names == 'Bob', 3]
Out[294]: array([-0.95578708, 0.49031693])
选中除了'Bob'外的所有行,可以用!=或者~:
names != 'Bob'
Out[296]: array([False, True, True, False, True, True, True])
要选择除"Bob"以外的其他值,既可以使用不等于符号(!=),也可以通过~对条件进行否定:
In [106]: names != 'Bob'
Out[106]: array([False, True, True, False, True, True, True], dtype=bool)
In [107]: data[~(names == 'Bob')]
Out[107]:
array([[ 1.0072, -1.2962, 0.275 , 0.2289],
[ 1.3529, 0.8864, -2.0016, -0.3718],
[ 3.2489, -1.0212, -0.5771, 0.1241],
[ 0.3026, 0.5238, 0.0009, 1.3438],
[-0.7135, -0.8312, -2.3702, -1.8608]])
~操作符用来反转条件很好用:
In [108]: cond = names == 'Bob'
In [109]: data[~cond]
Out[109]:
array([[ 1.0072, -1.2962, 0.275 , 0.2289],
[ 1.3529, 0.8864, -2.0016, -0.3718],
[ 3.2489, -1.0212, -0.5771, 0.1241],
[ 0.3026, 0.5238, 0.0009, 1.3438],
[-0.7135, -0.8312, -2.3702, -1.8608]])
选取这三个名字中的两个需要组合应用多个布尔条件,使用&(和)、|(或)之类的布尔算术运算符即可:
In [110]: mask = (names == 'Bob') | (names == 'Will')
In [111]: mask
Out[111]: array([ True, False, True, True, True, False, False], dtype=bool)
In [112]: data[mask]
Out[112]:
array([[ 0.0929, 0.2817, 0.769 , 1.2464],
[ 1.3529, 0.8864, -2.0016, -0.3718],
[ 1.669 , -0.4386, -0.5397, 0.477 ],
[ 3.2489, -1.0212, -0.5771, 0.1241]])
通过布尔型索引选取数组中的数据,将总是创建数据的副本,即使返回一模一样的数组也是如此。
注意:Python关键字and和or在布尔型数组中无效。要使用&与|。
通过布尔型数组设置值是一种经常用到的手段。为了将data中的所有负值都设置为0,我们只需:
In [113]: data[data < 0] = 0
In [114]: data
Out[114]:
array([[ 0.0929, 0.2817, 0.769 , 1.2464],
[ 1.0072, 0. , 0.275 , 0.2289],
[ 1.3529, 0.8864, 0. , 0. ],
[ 1.669 , 0. , 0. , 0.477 ],
[ 3.2489, 0. , 0. , 0.1241],
[ 0.3026, 0.5238, 0.0009, 1.3438],
[ 0. , 0. , 0. , 0. ]])
通过一维布尔数组设置整行或列的值也很简单:
In [115]: data[names != 'Joe'] = 7
In [116]: data
Out[116]:
array([[ 7. , 7. , 7. , 7. ],
[ 1.0072, 0. , 0.275 , 0.2289],
[ 7. , 7. , 7. , 7. ],
[ 7. , 7. , 7. , 7. ],
[ 7. , 7. , 7. , 7. ],
[ 0.3026, 0.5238, 0.0009, 1.3438],
[ 0. , 0. , 0. , 0. ]])
后面会看到,这类二维数据的操作也可以用pandas方便的来做。
6. Fancy Indexing(花式索引)
通过整数数组来索引。假设我们有一个8 x 4的数组:
arr = np.empty((8,4))
for i in range(8):
arr[i] = i
arr
Out[303]:
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
为了以特定顺序选取行子集,只需传入一个用于指定顺序的整数列表或ndarray即可:
arr[[4,3,0,6]]
Out[305]:
array([[4., 4., 4., 4.],
[3., 3., 3., 3.],
[0., 0., 0., 0.],
[6., 6., 6., 6.]])
这段代码确实达到我们的要求了!使用负数索引将会从末尾开始选取行:
arr[[-3,-5,-7]]
Out[306]:
array([[5., 5., 5., 5.],
[3., 3., 3., 3.],
[1., 1., 1., 1.]])
一次传入多个索引数组会有一点特别。它返回的是一个一维数组,其中的元素对应各个索引元组:
arr = np.arange(32).reshape((8,4))
arr
Out[309]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
arr[[1,5,7,2],[0,3,1,2]]
Out[310]: array([ 4, 23, 29, 10])
7. 数组转置和轴交换
转置也是返回一个view,而不是新建一个数组。有两种方式,一个是transpose方法,一个是T属性:
arr = np.arange(15).reshape((3,5))
arr
Out[312]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
arr.T
Out[313]:
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])
做矩阵计算的时候,这个功能很常用,计算矩阵乘法的时候,用np.dot:
In [129]: arr = np.random.randn(6, 3)
In [130]: arr
Out[130]:
array([[-0.8608, 0.5601, -1.2659],
[ 0.1198, -1.0635, 0.3329],
[-2.3594, -0.1995, -1.542 ],
[-0.9707, -1.307 , 0.2863],
[ 0.378 , -0.7539, 0.3313],
[ 1.3497, 0.0699, 0.2467]])
In [131]: np.dot(arr.T, arr)
Out[131]:
array([[ 9.2291, 0.9394, 4.948 ],
[ 0.9394, 3.7662, -1.3622],
[ 4.948 , -1.3622, 4.3437]])
对于高维数组,transpose需要得到一个由轴编号组成的元组才能对这些轴进行转置(比较费脑子):
In [132]: arr = np.arange(16).reshape((2, 2, 4))
In [133]: arr
Out[133]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
In [134]: arr.transpose((1, 0, 2))
Out[134]:
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])
这里,第一个轴被换成了第二个,第二个轴被换成了第一个,最后一个轴不变。
简单的转置可以使用.T,它其实就是进行轴对换而已。ndarray还有一个swapaxes方法,它需要接受一对轴编号:
In [135]: arr
Out[135]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
In [136]: arr.swapaxes(1, 2)
Out[136]:
array([[[ 0, 4],
[ 1, 5],
[ 2, 6],
[ 3, 7]],
[[ 8, 12],
[ 9, 13],
[10, 14],
[11, 15]]])
swapaxes也是返回源数据的视图(不会进行任何复制操作)。
4.2 通用函数:快速的元素级数组函数
通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数。你可以将其看做简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。
许多ufunc都是简单的元素级变体,如sqrt和exp:
In [137]: arr = np.arange(10)
In [138]: arr
Out[138]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [139]: np.sqrt(arr)
Out[139]:
array([ 0. , 1. , 1.4142, 1.7321, 2. , 2.2361, 2.4495,
2.6458, 2.8284, 3. ])
In [140]: np.exp(arr)
Out[140]:
array([ 1. , 2.7183, 7.3891, 20.0855, 54.5982,
148.4132, 403.4288, 1096.6332, 2980.958 , 8103.0839])
这些都是一元(unary)ufunc。另外一些(如add或maximum)接受2个数组(因此也叫二元(binary)ufunc),并返回一个结果数组:
In [141]: x = np.random.randn(8)
In [142]: y = np.random.randn(8)
In [143]: x
Out[143]:
array([-0.0119, 1.0048, 1.3272, -0.9193, -1.5491, 0.0222, 0.7584,
-0.6605])
In [144]: y
Out[144]:
array([ 0.8626, -0.01 , 0.05 , 0.6702, 0.853 , -0.9559, -0.0235,
-2.3042])
In [145]: np.maximum(x, y)
Out[145]:
array([ 0.8626, 1.0048, 1.3272, 0.6702, 0.853 , 0.0222, 0.7584,
-0.6605])
这里,numpy.maximum计算了x和y中元素级别最大的元素。
虽然并不常见,但有些ufunc的确可以返回多个数组。modf就是一个例子,它是Python内置函数divmod的矢量化版本,它会返回浮点数数组的小数和整数部分:
In [146]: arr = np.random.randn(7) * 5
In [147]: arr
Out[147]: array([-3.2623, -6.0915, -6.663 , 5.3731, 3.6182, 3.45 , 5.0077])
In [148]: remainder, whole_part = np.modf(arr)
In [149]: remainder
Out[149]: array([-0.2623, -0.0915, -0.663 , 0.3731,
0.6182, 0.45 , 0.0077])
In [150]: whole_part
Out[150]: array([-3., -6., -6., 5., 3., 3., 5.])
Ufuncs可以接受一个out可选参数,这样就能在数组原地进行操作:
In [151]: arr
Out[151]: array([-3.2623, -6.0915, -6.663 , 5.3731, 3.6182, 3.45 , 5.0077])
In [152]: np.sqrt(arr)
Out[152]: array([ nan, nan, nan, 2.318 , 1.9022, 1.8574, 2.2378])
In [153]: np.sqrt(arr, arr)
Out[153]: array([ nan, nan, nan, 2.318 , 1.9022, 1.8574, 2.2378])
In [154]: arr
Out[154]: array([ nan, nan, nan, 2.318 , 1.9022, 1.8574, 2.2378])
表4-3和表4-4分别列出了一些一元和二元ufunc。





有兴趣的了解一下,我上次看过这些函数就直接复制浏览一遍就过了。