进入麻瓜编程用python学爬虫第一周第二课的练习题了,自己鼓捣了半天,无解,最后可耻的看了答案:恍然大悟后发现自己没有真正领会标签后面的描述的真正意思。
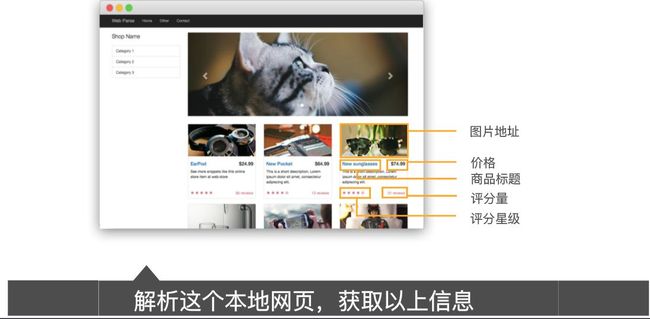
爬取本地网页信息
我的代码:
from bs4 import BeautifulSoup
with open('/home/steven/Downloads/Plan-for-combating-master/week1/1_2/1_2answer_of_homework/1_2_homework_required/index.html','r') as wb_data:
Soup = BeautifulSoup(wb_data,'lxml')
images = Soup.select('body > div > div > div.col-md-9 > div > div > div > img')
prices = Soup.select('body > div > div > div.col-md-9 > div > div > div > div.caption > h4.pull-right')
titles = Soup.select('body > div > div > div.col-md-9 > div > div > div > div.caption > h4 > a')
reviews = Soup.select('body > div > div > div.col-md-9 > div > div > div > div.ratings > p.pull-right')
stars = Soup.select('div.col-sm-4 > div > div > p:nth-of-type(2)')
for image,price,title,review,star in zip(images,prices,titles,reviews,stars):
data= {
'image': image.get('src'),
'price': price.get_text(),
'title': title.get_text(),
'review': review.get_text(),
'star': len(star.find_all('span',class_='glyphicon glyphicon-star'))
}
print(data)
这行代码stars = Soup.select('div.col-sm-4 > div > div > p:nth-of-type(2)') 是这道题的关键点之一。
在检查模式中选中随便选中一个星星后copy css selector后得到的路径类似为:div.col-sm-4:nth-child(1) > div:nth-child(1) > div:nth-child(3) > p:nth-child(2) > span:nth-child(1);
为符合程序语法,将nth-child替换为nth-of-type,并去掉前几个标签后面的位置描述得到了:div.col-sm-4 > div > div > p:nth-of-type(2) > span:nth-of-type(1);
根据题目要求,要统计有多少个星星,应该在span的上一级,也就是搜索到他的父级p标签,因此去掉最后一级路径,得到:div.col-sm-4 > div > div > p:nth-of-type(2) ;
这里出现关键中的关键点:究竟要不要保留p标签后的位置描述信息:nth-of-type(2) ? 这里实际上是考察了对路径的位置描述的实际理解。因为原网页中div标签下实际上有两个p标签,其一为
65 reviews
,它的css selector路径是div.col-sm-4:nth-child(1) > div:nth-child(1) > div:nth-child(3) > p:nth-child(1)。回到问题,如果去掉了p标签后的位置描述信息,那么得到的内容实际上包含其他p标签内的信息,造成对待统计项的干扰。因此最终要保留p标签后的位置信息,即使用div.col-sm-4 > div > div > p:nth-of-type(2)作为路径。
接着来到第二个关键点:如何使用过滤过的信息,统计星星的个数。
- 实际上我通过阅读beatuifulsoup在线文档中的find_all部分,已经尝试过使用'star': star.find_all('span',class_='glyphicon glyphicon-star')的功能,但是我的思维还停留在使用for循环来累加得出个数的阶段,看到答案中漂亮的用len功能直接统计了find_all功能得到的列表中的元素个数,我决定先记住这个牛的不行不行的功能。
看一下程序运行结果:
/usr/bin/python3.5 "/home/steven/Downloads/Plan-for-combating-master/week1/1_2/1_2answer_of_homework/1.2 new.py"
{'title': 'EarPod', 'price': '$24.99', 'review': '65 reviews', 'image': 'img/pic_0000_073a9256d9624c92a05dc680fc28865f.jpg', 'star': 5}
{'title': 'New Pocket', 'price': '$64.99', 'review': '12 reviews', 'image': 'img/pic_0005_828148335519990171_c234285520ff.jpg', 'star': 4}
{'title': 'New sunglasses', 'price': '$74.99', 'review': '31 reviews', 'image': 'img/pic_0006_949802399717918904_339a16e02268.jpg', 'star': 4}
{'title': 'Art Cup', 'price': '$84.99', 'review': '6 reviews', 'image': 'img/pic_0008_975641865984412951_ade7a767cfc8.jpg', 'star': 3}
{'title': 'iphone gamepad', 'price': '$94.99', 'review': '18 reviews', 'image': 'img/pic_0001_160243060888837960_1c3bcd26f5fe.jpg', 'star': 4}
{'title': 'Best Bed', 'price': '$214.5', 'review': '18 reviews', 'image': 'img/pic_0002_556261037783915561_bf22b24b9e4e.jpg', 'star': 4}
{'title': 'iWatch', 'price': '$500', 'review': '35 reviews', 'image': 'img/pic_0011_1032030741401174813_4e43d182fce7.jpg', 'star': 4}
{'title': 'Park tickets', 'price': '$15.5', 'review': '8 reviews', 'image': 'img/pic_0010_1027323963916688311_09cc2d7648d9.jpg', 'star': 4}
Process finished with exit code 0
总结:
- 每一个简洁的统计背后都是一个大坑......
- 拷贝css selector得到的路径里,标签后面的位置描述信息并非没有用,它描述了父级标签下特定的一组标签;
- find_all功能得到的是一个列表,使用len功能可以直接统计列表元素的个数。