参考资料:
原paper地址:https://arxiv.org/abs/1703.06211
知乎讨论地址:https://www.zhihu.com/question/57493889
csdn blog地址:http://blog.csdn.net/yaoqi_isee/article/details/65963253
Notes地址:https://medium.com/@phelixlau/notes-on-deformable-convolutional-networks-baaabbc11cf3
Abstract
由于构造卷积神经网络 (CNN) 所用的模块中几何结构是固定的,其几何变换建模的能力本质上是有限的。在我们的工作中,我们引入了两种新的模块来提高卷积神经网络 (CNN) 对变换的建模能力,即可变形卷积 (deformable convolution) 和可变形兴趣区域池化 (deformable ROI pooling)。它们都是基于在模块中对空间采样的位置信息作进一步位移调整的想法,该位移可在目标任务中学习得到,并不需要额外的监督信号。新的模块可以很方便在现有的卷积神经网络 (CNN) 中取代它们的一般版本,并能很容易进行标准反向传播端到端的训练,从而得到可变形卷积网络 (deformable convolutional network)。大量的实验验证了我们的方法在目标检测和语义分割这些复杂视觉任务上的有效性。代码地址:这里
1.Introduction
在这项工作中,我们引进了新的模块,大大增强了CNN的几何变换建模能力。首先是可变形卷积。它在标准卷积中向常规采样网格添加了2D偏移。
![Deformable Convolution Networks[译]_第1张图片](http://img.e-com-net.com/image/info10/dc11bd510e9248bc92ee5e07ab6480cd.jpg)
二是deformable RoI pooling。它在以前的RoI pooling中的常规bin partition中为每个bin添加了一个offset。类似地,从先前的特征图和RoI学习偏移,使得能够对具有不同形状的对象进行自适应部分定位。
两个模块的权值都不多。它们因为加入了偏移的学习添加了少量参数和计算。它们可以轻松集成到深CNN架构中,并通过反向传播进行端到端的训练。这种结构叫做deformable convolutional networks或deformable ConvNets.
两者原理是一样的,就是在这些卷积或者ROI采样层上,添加了位移变量,这个变量根据数据的情况学习,偏移后,相当于卷积核每个方块可伸缩的变化,从而改变了感受野的范围,感受野成了一个多边形。
2.Deformable Convolutional Networks
虽然CNN中的特征映射图和卷积核是3D tensor,但可变卷积和RoI池都在2D空间域上运行的,并且在通道维度上保持不变。
2.1Deformable Convolution
一个2D的卷积由两步组成:
1)使用框架R在输入的特征图上采样
2)将采样值与对应的权重相乘,再求和
R定义了感受野的大小和dilation。例如:
R = {(−1, −1),(−1, 0), . . . ,(0, 1),(1, 1)} 定义了3×3的内核,dilation为1
对于输出特征图y上的每个位置p0,我们有

Deformable Conv操作并没有改变卷积的计算操作,而是在卷积操作的作用区域上,加入了一个可学习的参数∆pn。对于变形的卷积,增加了一个参数,即偏移量 {∆pn|n = 1, ..., N}, where N = |R|.

然而,这样的操作引入了一个问题,即需要对不连续的位置变量求导。作者在这里借鉴了之前Spatial Transformer Network和若干Optical Flow中warp操作的想法,使用了bilinear插值将任何一个位置的输出,转换成对于feature map的插值操作。
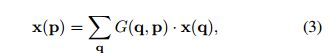

上式中的g(a, b) = max(0, 1 − |a − b|),等式3是很容易计算的,大多数的q位置G为0。
总结一下上面四个公式就是,公式1是正常的卷积计算公式,公式2是添加了偏移后的公式,然后对这个公式做线性插值变化就成了3,3的左边是原始图的位置,x(q)是卷积后的特征图,G就是需要学习的变换核。这样就可以求偏导进行梯度下降学习了。4就是这个需要学习的核的表示。
![Deformable Convolution Networks[译]_第2张图片](http://img.e-com-net.com/image/info10/25f32da68c5a4ec5b1f0b83be31e8dd0.jpg)
对于输入的一张feature map,假设原来的卷积操作是3*3的,那么为了学习offset,我们定义另外一个3*3的卷积层,输出的offset field其实就是原来feature map大小,channel数等于2(分别表示x,y方向的偏移)。这样的话,有了输入的feature map,有了和feature map一样大小的offset field,我们就可以进行deformable卷积运算。所有的参数都可以通过反向传播学习得到。
2.2 Deformable ROI Pooling
RoI池模块将任意大小的输入矩形区域转换为固定大小的特征。给定一个ROI,大小为w*h,它最后会被均匀分为K*K块,k是个自由参数。标准的ROI pooling是从输入的特征图x中生成k*k个输出特征图y.第(i,j)个块的pooling操作可以被定义为:

p0是左上方的角落块,nij是这个块内的像素值。类似的定义变形的ROI pooling,增加一个偏移量∆pij,如下定义
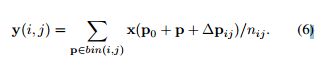
![Deformable Convolution Networks[译]_第3张图片](http://img.e-com-net.com/image/info10/a2e0d24dfa8c49848418b7cf6ef6d5d5.jpg)
2.3. Deformable ConvNets
可变卷积和RoI池模块都具有与其简单的额版本有着相同的输入和输出。因此,他们可以取代在现有的CNNs中原有的模块的位置。在训练的时候,用于偏移学习的附加conv / fc层初始化为0,他们的学习速率是现有layers的β倍(默认为β= 1)。他们的值是通过bp训练,由双线性插值运算,见公式 (3)和(4)。所得到的CNN称为deformable ConvNets。
我们可以把deformable ConvNets分成两步,一是用一个深度全卷积网络从输入的图上得到特征图,二是,用一层具有特定功能的网络从特征图中产生结果。
![Deformable Convolution Networks[译]_第4张图片](http://img.e-com-net.com/image/info10/f5d07ee32fe446be9a894ab9e9c85935.jpg)
3. Understanding Deformable ConvNets
这是建立在一个简单的想法之上的。卷积和RoI合并中的空间采样位置增加了额外的偏移量。这些偏移量是从数据中学习的,被目标驱动的。当可变形模块堆叠成多层时,复合变形的影响是深刻的。
![Deformable Convolution Networks[译]_第5张图片](http://img.e-com-net.com/image/info10/b06c5c2db8024bb191dd23e05d960bd9.jpg)
4. Experiments
作者在不同网络结构上的实验结果在文章中描述的很清楚,下面是我自己跑的作者的代码(这里):
下面是网络结构,deformable CNN 比Normal CNN多了Convoffset2D层。
![Deformable Convolution Networks[译]_第6张图片](http://img.e-com-net.com/image/info10/4dc0fd768cc54eefbd5091ca2e22434f.png)
![Deformable Convolution Networks[译]_第7张图片](http://img.e-com-net.com/image/info10/f01d4c775af14d41afb58f1b0db3925d.png)
![Deformable Convolution Networks[译]_第8张图片](http://img.e-com-net.com/image/info10/a242943575704220a988e41051fd8ca7.png)
增加Convoffset2D层并不会改变层与层之间输入与输出的shape,因此可以很容易的在现有的网络中增加offset,从而变成deformable ConvoNets,但毫无疑问会增加训练参数的数量,因为多了offset.

这是conv内部结构的代码描述(keras keras.backend=tensorflow)
![Deformable Convolution Networks[译]_第9张图片](http://img.e-com-net.com/image/info10/b2564f9bb48147229ebbba3a054e52f5.jpg)
Normal CNN测试mnist image和scaled mnist image的准确率:
Deformable CNN测试mnist image和scaled mnist image的准确率:
可以看到,Deformable CNN对scaled image有着非常大的优势
分别打印出三个deformable convnet layer
结果如下
![Deformable Convolution Networks[译]_第10张图片](http://img.e-com-net.com/image/info10/3bb21b8165d0412fb8209022c03cca1b.png)
水平有限,欢迎大佬指教~ ^_^