使用工具:pycharm
使用模块:xlml
核心(xpath的运用)
前言:
在一天的嘈杂之后,
总想着找一片净土,
放归难以安放的漂泊心。
人生有时真的很累,
有时也会想着,
在一个孤独的夜晚,
趁着夜色正浓,
期望寻到一部契合自己心情的电影,
就那么静静看着,
忘掉身边的枷锁。
可残酷的现实总是不期而遇,
制片方层出不穷的炒作手段,
总是将一部烂到极点的电影,
包装到五光十色。
今天就为大家打开新世界的大门,
利用Python爬取猫眼top100经典老电影,
我们一起怀念那些逝去的青春。
一、打开猫眼top100网页
印入眼帘还是那部霸王别姬,

图片.png
个人非常喜欢张国荣,
荣粉们都喜欢称呼他“哥哥”,
如今哥哥却早已不在,
哥哥,如今在那边是否安好?

5c947eea70b99ffd66e42350da272b0.png
好啦,不提这些伤心事了,
右击鼠标<检查>或按F12打开抓包工具,
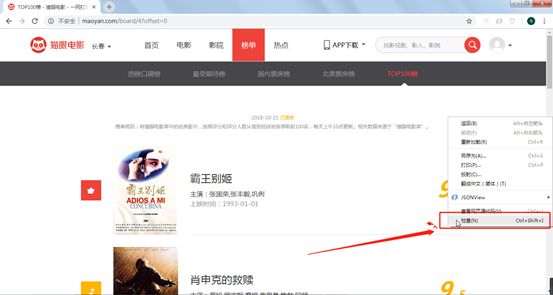
图片.png
二、分析网页并编码
1、 url

图片.png

图片.png
第一页url: http://maoyan.com/board/4?offset=0
第二页url: http://maoyan.com/board/4?offset=10
第三页url: http://maoyan.com/board/4?offset=20
我们找到规律,
每个网页的url加10,
因此我们可以利用循环,
爬取10页,最终爬取100部经典老电影。
# -*- coding:utf-8 -*-
#引入所需模块
import requests
from requests.exceptions import RequestException
from lxml import etree
for i in range(10):
print('第{}页'.format(i + 1))
url = 'http://maoyan.com/board/4?offset={}'.format(i * 10)
headers = {'User-Agent': 'Mozilla/5.0'}
#发送请求并得到响应
response = requests.get(url=url,headers=headers)
#输出响应的文本
print(response.text)

图片.png
2、 每页的电影
上面我们提到本文的重点是xpath,
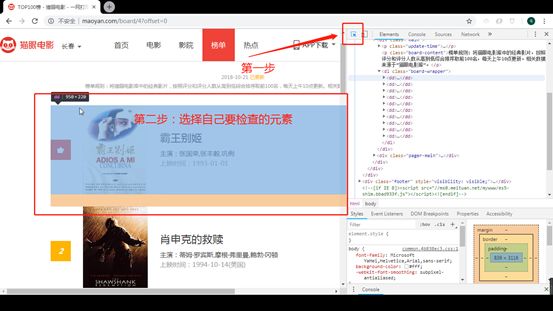
图片.png

图片.png
第一部电影xpath:// [@id="app"]/div/div/div[1]/dl/dd[1]
第二部电影xpath://[@id="app"]/div/div/div[1]/dl/dd[2]
第三部电影xpath://*[@id="app"]/div/div/div[1]/dl/dd[3]
只有dd[]中的数字不一样,
到时候我们只要把dd后面的[我是数字]去掉,
就可以把这一页的电影全部爬下来,
并生成一个list。
# -*- coding:utf-8 -*-
#引入所需模块
import requests
from requests.exceptions import RequestException
from lxml import etree
for i in range(10):
print('第{}页'.format(i + 1))
url = 'http://maoyan.com/board/4?offset={}'.format(i * 10)
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url=url,headers=headers).text
#用etree.HTML解析网页
page = etree.HTML(response)
#利用xpath获取电影
movies = page.xpath('//*[@id="app"]/div/div/div[1]/dl/dd')
print(movies)

图片.png
3、 电影信息
电影爬到了,
电影信息还会远吗?
与上面两步的操作一样,
以电影标题的xpath为例。
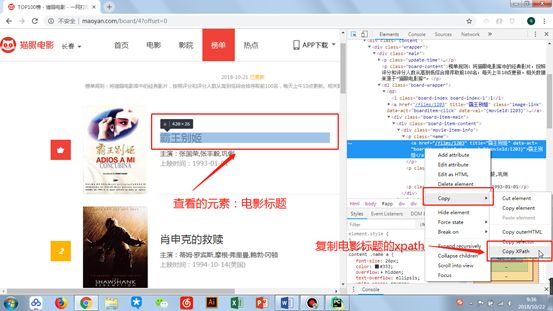
图片.png
第一部电影标题:// [@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[1]/p[1]/a
第一部电影主演://[@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[1]/p[2]
第一部电影时间:// [@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[1]/p[3]
第一部电影得分:
整数部分://[@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[2]/p/i[1]
小数部分:// [@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[2]/p/i[2]
可以看到:
第一部电影://[@id="app"]/div/div/div[1]/dl/dd[1]
电影信息://*[@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[1]/p[1]/a
二者的重复部分在爬取电影信息时用“.”代替,
例如:’. /div/div/div[1]/p[1]/a’
# -*- coding:utf-8 -*-
#引入所需模块
import requests
from requests.exceptions import RequestException
from lxml import etree
for i in range(10):
print('第{}页'.format(i + 1))
url = 'http://maoyan.com/board/4?offset={}'.format(i * 10)
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url=url,headers=headers).text
page = etree.HTML(response)
movies = page.xpath('//*[@id="app"]/div/div/div[1]/dl/dd')
#利用循环获取movies中的每部电影
for i in range(10):
#获取电影的信息
#[0]是对list类型数据的操作,取出list中的第一个元素
movie_title = movies[i].xpath('./div/div/div[1]/p[1]/a/text()')[0]
#.stript()表示去除数据中的空格、换行等
movie_author = movies[i].xpath('./div/div/div[1]/p[2]/text()')[0].strip()
movie_time = movies[i].xpath('./div/div/div[1]/p[3]/text()')[0].strip()
movie_score_integer = movies[i].xpath('./div/div/div[2]/p/i[1]/text()')[0]
movie_score_fraction = movies[i].xpath('./div/div/div[2]/p/i[2]/text()')[0]
#输出打印电影信息
print('{} {} {} {} '.format(movie_title, movie_author, movie_time, movie_score_integer + movie_score_fraction))
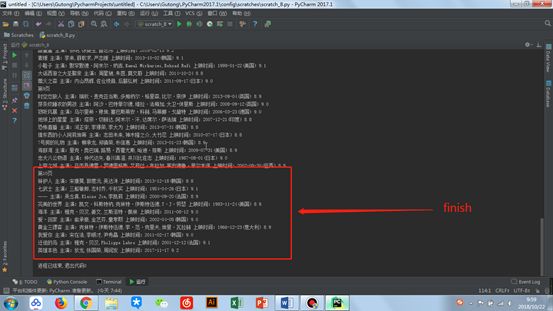
图片.png
4、 保存到本地
保存的部分就比较简单了,
两行代码搞定。
#在d盘创建一个movies.txt文件
with open(r'd:\movies.txt', 'a', encoding='utf8') as f:
f.write()
# -*- coding:utf-8 -*-
#引入所需模块
import requests
from requests.exceptions import RequestException
from lxml import etree
for i in range(10):
print('第{}页'.format(i + 1))
url = 'http://maoyan.com/board/4?offset={}'.format(i * 10)
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url=url,headers=headers).text
page = etree.HTML(response)
movies = page.xpath('//*[@id="app"]/div/div/div[1]/dl/dd')
#在d盘创建一个movies.txt文件
with open(r'd:\movies.txt', 'a', encoding='utf8') as f:
for i in range(10):
movie_title = movies[i].xpath('./div/div/div[1]/p[1]/a/text()')[0]
movie_author = movies[i].xpath('./div/div/div[1]/p[2]/text()')[0].strip()
movie_time = movies[i].xpath('./div/div/div[1]/p[3]/text()')[0].strip()
movie_score_integer = movies[i].xpath('./div/div/div[2]/p/i[1]/text()')[0]
movie_score_fraction = movies[i].xpath('./div/div/div[2]/p/i[2]/text()')[0]
f.write('{} {} {} {} '.format(movie_title, movie_author, movie_time, movie_score_integer + movie_score_fraction))
三、优化代码
完整代码如下:
# -*- coding:utf-8 -*-
#引入所需模块
import requests
from requests.exceptions import RequestException
from lxml import etree
def get_one_page(url,headers):
try:
response = requests.get(url=url,headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_and_save(html):
page = etree.HTML(html)
movies = page.xpath('//*[@id="app"]/div/div/div[1]/dl/dd')
with open (r'd:\movies.txt','a',encoding='utf8') as f:
for i in range(10):
movie_title = movies[i].xpath('./div/div/div[1]/p[1]/a/text()')[0]
movie_author = movies[i].xpath('./div/div/div[1]/p[2]/text()')[0].strip()
movie_time = movies[i].xpath('./div/div/div[1]/p[3]/text()')[0].strip()
movie_score_integer = movies[i].xpath('./div/div/div[2]/p/i[1]/text()')[0]
movie_score_fraction = movies[i].xpath('./div/div/div[2]/p/i[2]/text()')[0]
f.write('{} {} {} {} \n'.format(movie_title, movie_author, movie_time, movie_score_integer + movie_score_fraction))
def main():
for i in range(10):
print('第{}页'.format(i+1))
url = 'http://maoyan.com/board/4?offset={}'.format(i*10)
headers = {'User-Agent':'Mozilla/5.0'}
html = get_one_page(url,headers)
parse = parse_and_save(html)
if __name__ == '__main__':
main()
硬广<个人公众号:此地古同>