import tensorflow as tf
import numpy as np
x_data = np.random.rand(100).astype(np.float32)
y_data = 0.1*x_data+0.3
首先创建随机的100个数据x_data
目标函数y_data =0.1*x_data+0.3
这里0.1为Weight,0.3为biases
#create tensorflow structure start
Weights = tf.Variable(tf.random_uniform([1],-1.0,1.0))
biases = tf.Variable(tf.zeros([1]))
利用tensorflow预设一个随机的Weights和biases,Weights范围在-1到1,biases初始化为一位的0
y = Weights*x_data+biases
模拟出目标的函数
loss = tf.reduce_mean(tf.square(y-y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
loss为预测出的y与y_data的误差
optimizer是tensorflow自带的优化器,这里选择的是GradientDescentOptimizer
训练时对误差进行最优优化
init = tf.global_variables_initializer()
初始化模型参数
session = tf.Session()
session.run(init)
for setp in range(201):
session.run(train)
if setp % 20 == 0:
print(setp,session.run(Weights),session.run(biases))
session.close()
这里实例化会话,然后加载初始化后的模型,训练200次,每隔20次打印一下当前的Weights和biases,结果可以看出,已经相当接近目标函数的Weights和biases
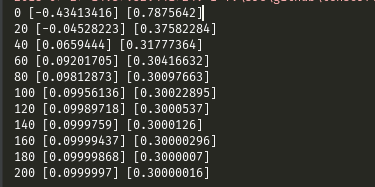
image.png