本人水平有限,如果有错误的地方,希望各位大神能够不吝赐教,及时指正。
按照惯例,喝水不忘掘井人,首先要感谢发明人工神经网络的那些前辈。其次,也要感谢Sean的引领,把我带入这一行,否则,光靠我自己摸索,会花去更多的时间、精力。最后,要感谢无数的人,那些对我的思考方式产生影响的人。
现在每掌握一种新的算法,心情都是喜忧参半,喜的是,技多不压身,又多了一个解决问题的手段,忧的是,这手段来钱快么?好像不能指望其预测股价啊。
在神经网络模型中,需要用到导数的概念,如果还不是太了解导数(偏导、链式法则),这里给出以下几种办法:
1、先行补导数的知识
2、跳过相关推导过程
3、请我喝一杯咖啡,我把半桶水的功力全部传授给你
4、硬着头皮看下推导
5、或许我可能会稍微解释一下
那个有关神经的生物图,我就不再画了,应该每个人都有一个印象了,主要还是画画技术不过关,但是计算机领域神经网络的结构图还是要画的。
(感觉画图不太适合自己,为了节省时间,部分线条采用手工绘制,图画只能将就将就了)
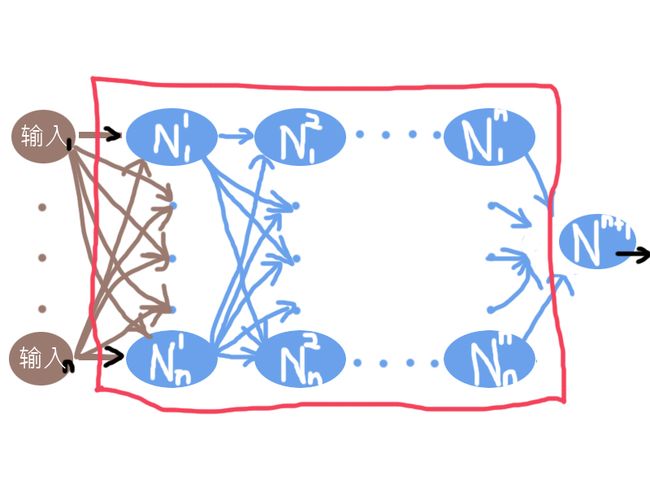
(大概也只有灵魂画手才能画出这样的图了吧,希望拙劣的图片不会影响文字的讲解)
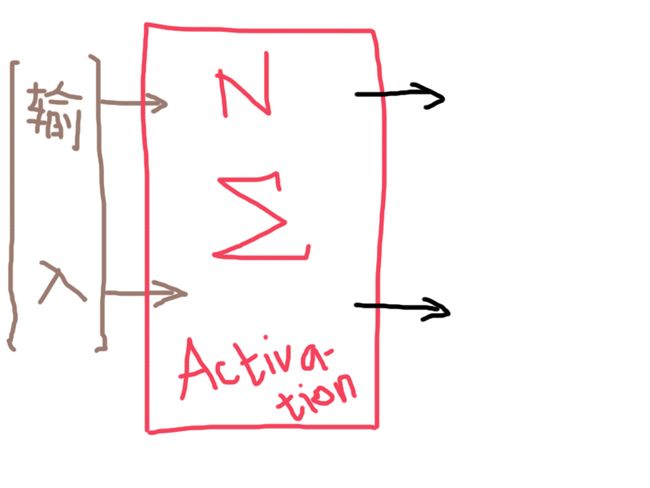
当然,最右边的蓝色椭圆N,也可以有多个。
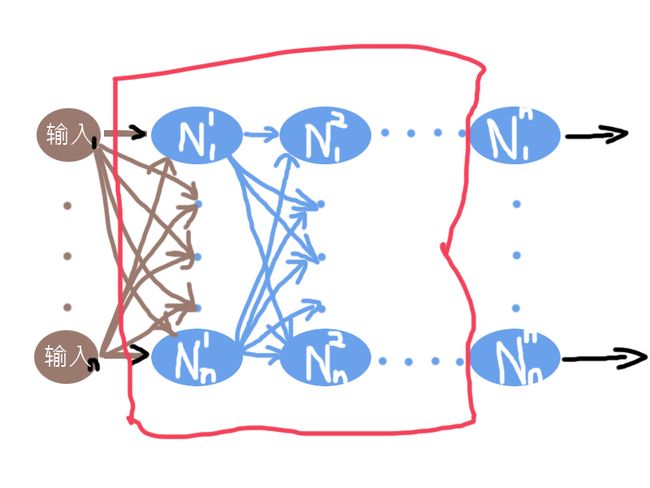
聪明的你,看图应该可以猜到了,既然最右的蓝色椭圆N可以有多个,那就意味着,神经网络模型既可以用来作为二分类,也可以用来作为多分类,而且它是非线性回归的。
在继续下去之前,有些地方需要解释一下,蓝色椭圆中,N的右上角的字符,表示N所在的列数,N右下角的字符,表示它是该列的第几个N;每一根褐色和蓝色的手绘线条,都代表了相应的权重。最右边的黑色箭头,代表着输出;红色的框框表示,框内的都是隐藏层,很明显,除了第一层的输入以及最后一层的那个N之外,其余都属于隐藏层。
(题外话,另一个同样是我个人觉得有必要再说明一下的是:采用“输入”、“权重”这样的字眼是不是有点那啥.... 没错,我完全可以用x, w,甚至一些希腊字母来代替,但是,你们应该发现了,我这里使用了'N',仅仅是它是“Neural”的首字母缩写,其它的相关文章,可能这里会使用其它的代号,这正是数学美丽的地方,也是容易让人产生错觉的地方,从小到大我们习惯接受了X,X是变量,但是变量不一定就是X,完全可以用B、i、n、H、a、o,这些来表示变量,甚至一些稀奇古怪的符号,比如五角星,或者这里的N+右上角的字符,甚至我也可以就用Binhao来做变量,你可以把Binhao看作一个单独的变量,也可以把它理解为之前B、i、n、H、a、o,6个变量的乘积,放在这里作为输入,同理,权重也可以出现五花八门的表现形式,以致于,我们经常会产生错觉,在看不同作者的文章时,经常会问自己“他讲的和我想的是同一个事物么?”“我之前大概学的是假的吧?”,所以我们应该明白,这些都是数学的变幻,其本质是相通的。)
继续,这里的每一个蓝色的椭圆里的N会干些什么呢?它就是每一个连接到它的输入乘以权重的总和,再作为另一个被称之为Activation函数的输入。这里,我们先不讨论Activation函数又是什么,暂且认为它是一个关于N的函数,那么,每一个N具体至少包括以下两个步骤:
(1). z = ∑wx(1....n)
(2). y = f(z)
[限于键盘输入的限制,也是为了节省时间,这里的w(权重),x(输入)其实是代表了向量,因为从图里就能看到了,一串的输入和一串的权重]
接下去的问题是,这样得到的z是不是可以直接作为参数给f()然后activation传递到下一层了呢?不行,我们还需要给它设置一个阈值,假设,就叫作T吧,那就是z要减去T,如果这个相减结果大于0,才能输出。你可能会问为什么,为什么要来一个阈值,ok,我们现在讨论的是神经网络,就是人工模拟大脑神经的活动,实际上真实的神经被激活需要脉冲达到一定的电位,也就是临界阈值,然后才会对累积的外界信号做出响应进行传递。(T也就是R代码实现时的“Bias Terms”偏差项,也可以看作y=wx + b的b(w、x是向量)。所以你看,代号并不重要,理清本质比较关键)
其实,我们不需要为这个T而烦恼,数学很美丽,而且会变幻,我们早就遇到过,我可以完全把T也看作一个恒定的输入,它的权重是-1,这样一来,z=∑wx 其实下标就是从0开始 z=∑wx (0...n) 【再次说明,限于键盘输入的限制,也是为了节省时间,你们应该能理解其实它真正是什么样子的。这正好也印证了之前提到的,不要拘泥于公式的表象用了什么变量和展现形式】我们最终要对模型进行训练,就是不断调整所有这些权重(包括这个阈值)和隐藏层数,最后达到比较理想的效果。
是时候来讨论一波Activation函数了。为什么需要Activation函数,首先,模仿神经,累积的能量达到临界阈值需要被激活,其次,Sean已经给我们解释过了,没有激活函数的话,就完完全全是线性的了,那么中间一大堆隐藏层就显得毫无意义,所以需要一个Activation函数来加入非线性的元素。那么,我们需要什么样的Activation函数?它必须得非线性,而且我们希望它能把数据映射到0-1之间,这样可以应用到概率上,进行分类。(Sean其实已经给我们讲了好几个Activation函数了)
先来看看,假设我们之前没有采用数学技巧把T给变幻了,Activation函数会是怎样的:
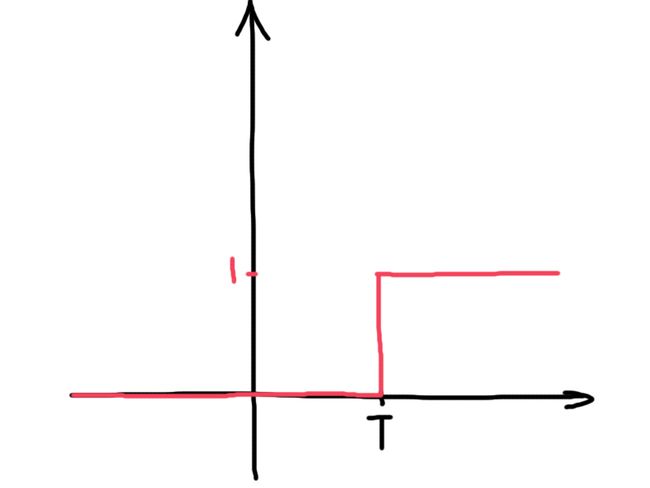
大致是这样的,在遇到T(大于T)之前,不会被激活,所以一直是0,遇到T之后,开始被激活,变为1。
再来看看,我们采用数学技巧,把T变幻了之后,Activation函数又是怎么样的:
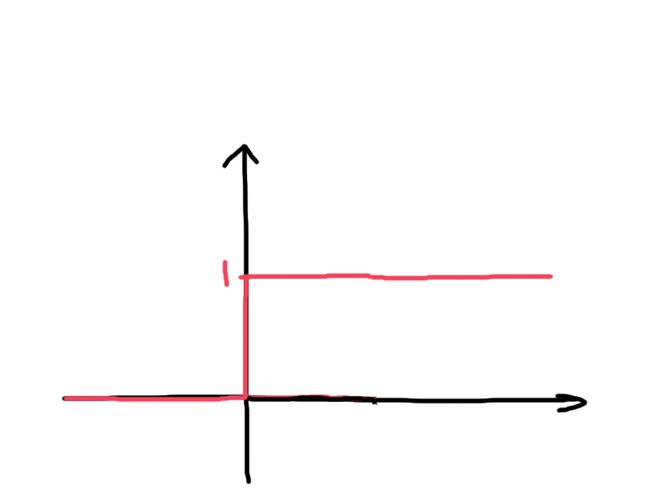
T被作为一个恒定输入,权重为-1,提前被减掉了。
看起来不错,数值都被映射到了0-1之间,那它就是我们要的Activation函数了么?不,不是。理由很简单,本文开头,已经提到了,神经网络需要用到导数知识,而导数的一个先决条件是,在包含求导的这一点的某区间内,函数曲线必须是连续的,平滑的。这个显然不是。
既然要连续,平滑,于是我们找到了它(Sigmoid函数):
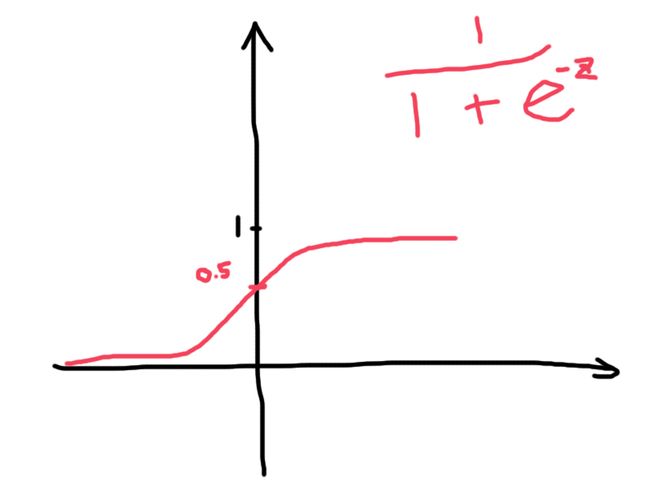
就是它了。(当然别的也是可以的,Sean都已经提到过)
看看还有什么遗漏的,哦,对,那些个隐藏层,既然它们叫做隐藏层,那就真的可以把它们看作是黑盒子,所以,简化下图-1和图-2,得到下图:
难看是难看了一点,将就一下吧。但不影响接下去的重点。
从神经网络角度,我们简单地把输出看作是:y = f(w,x) 输出y是向量w和x的函数(键盘输入限制,不画那根箭头了,但是心里要清楚,这是向量)
而实际的结果则是:a = g(x) 实际值a是输入x的函数(x是向量,理由同上)。
写到这里,你应该已经明白了,判断一个神经网络模型训练结果好坏,其实就是 1/2 * [(a - y)^2]的值要最小。这里1/2没有其它意义,纯碎是数学便利,求导方便。这个1/2 * [(a - y)^2]的图像是个凸函数,求最小值即可,也就是切线斜率为0的点。
但是,Sean曾经告诉过我们,从山顶下坡到最低点的例子了,所以,我打算求个最大值,也就是从山脚爬坡到最高点,所以这个函数要变一下:
-1/2 * [(a - y)^2],加了个负号,则求最小值就变为求最大值了。凸函数变凹函数了。梯度下降改为梯度上升。
在这之前,先补充讲解一下等高线图。因为我还没办法展示多维平面的山坡图,所以等高线图就是一个不错的备选。遐想一下从山顶俯瞰一座山,看到的应该是如下的图:
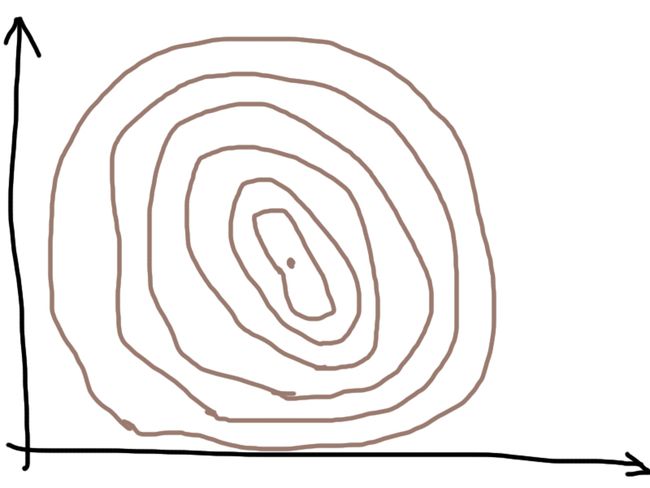
越里面的圆,表示的高度越高,最高的高度在最中间的圆心,每个圆上的所有点的高度都是相同的。
假设最开始随机的几个权限w,在靠近外围的圆,那我所要做的就是调整w,使它往高处走。令 p = -1/2 * [(a - y)^2]
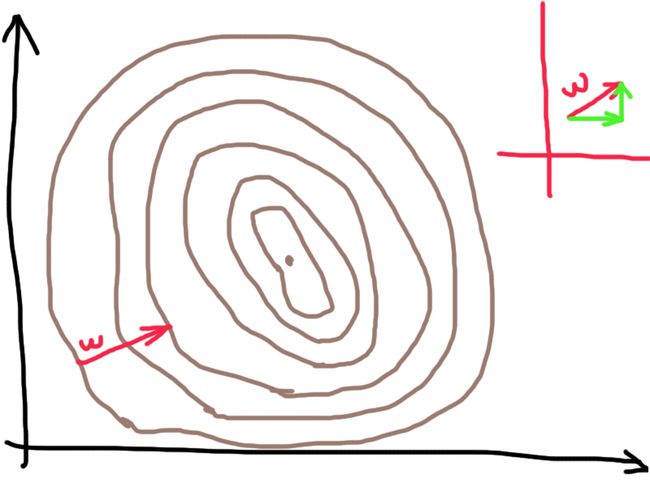
根据导数和向量的知识,我们可以知道,delta w = 步长 *(p对横向数值的求导 * 横向的单位向量 + p对纵向数值的求导 * 纵向的单位向量)
步长可以看作希腊字母lamda,是为了控制权重w不要变化得太快,这个是我们自己可以设置的值。
那至于接下去该怎么求得这个最优权重呢?它和哪些因素有关呢?不妨从最简单的一个单一输入神经网络模型入手。
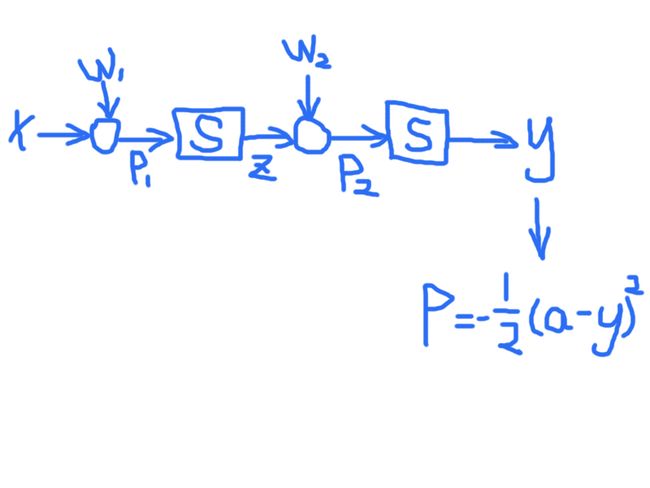
x是输入,w1,w2是权重,p1,p2是爬坡中途某个阶段的输出,S是Sigmoid函数。
现在我们要利用链式法则求P的偏导数。
【简单讲下链式法则:
s = 1/2 * gt^2,物理学的重力加速度g,在这里可以看作常数,那么唯一的变量就是t了,对t求导应该都会,gt。假设 t又等于x^2,现在我要求s对x求导,那么就是在s对t求导的基础上,再乘以t对x的求导(即x^2的导数),就是gt*2x(当然这个例子不太好,直接1/2 * gx^4也能求导,但是主要是体会下链式求导的规则)。同理,图中P对y求导,即-(a-y) * (-1) = (a-y),减法的导数等于分别求导再减法,a是实际值常数,导数为0,y对自己的导数是1。】
ΔP/Δw2 = ΔP/Δy * Δy/Δw2 = (a-y) * Δy/Δp2 * Δp2/Δw2 = (a-y) * Δy/Δp2 * z
【p2,我们知道,就是z乘以权重w2,所以p2对w2求偏导,就是 z的导数乘以w2 + z乘以w2的导数(乘法导数规则),z是常数导数为0,w2的导数是1,所以和等于z。什么是偏导?偏导的求法其实和导数的求法是一样的,只不过多了一点,这里对w2求偏导,那么w2以外的都看作是常数。】
ΔP/Δw1 = ΔP/Δy * Δy/Δw1 = (a-y) * Δy/Δp2 * Δp2/Δw1
= (a-y) * Δy/Δp2 * Δp2/Δz *Δz/Δw1 = (a-y) * Δy/Δp2 * w2 *Δz/Δw1
= (a-y) * Δy/Δp2 * w2 * Δz/Δp1 * Δp1/Δw1
= (a-y) * Δy/Δp2 * w2 * Δz/Δp1 * x
现在来看一下分别对w1和w2求偏导后的公式,Δy/Δp2 ,Δz/Δp1 这两个的导数我们还不得而知,可是我们还有图-9,不是么?p2是y的输入,p1是z的输入,y是p2经过Sigmoid后的输出,
z是p1经过Sigmoid后的输出,所以Δy/Δp2 ,Δz/Δp1其实就是求Sigmoid的导数。
那就来对Sigmoid求导:
1/(1 + e^(-α)) 【图-5里,e的指数使用了z,但是这里为了避免混淆,所以改用希腊字母α。同时再次表明,数学公式变量是随便可以展现的,关键在于其核心思想】
也就等于 (1 + e^(-α))^(-1)
根据链式法则:= [-(1 + e^(-α) )^(-2)] * e^(-α) * (-1) = e^(-α) / (1 + e^(-a))^2
接下去还是画图吧,不然有点眼花缭乱。图虽然丑了点,但便于直观。
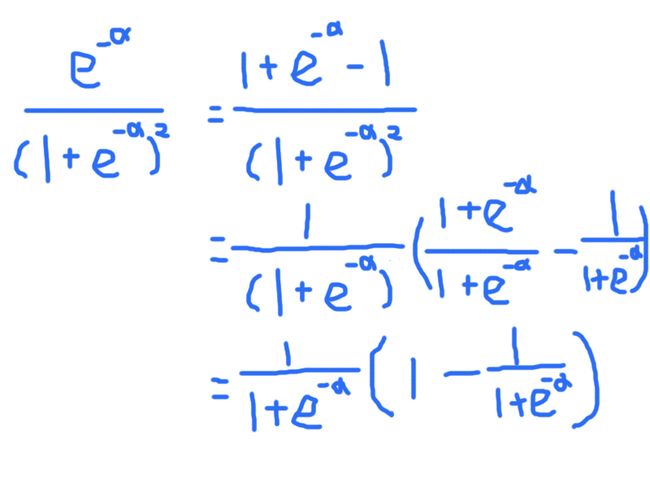
根据图-10继续运算的结果,Sigmoid函数 S = 1/(1 + e^(-α)), 求导的结果,S*(1-S)。
再回过头去看,Δy/Δp2 ,Δz/Δp1其实分别是y*(1-y),z*(1-z)。
所以:
ΔP/Δw2 = (a-y) * y*(1-y) * z
ΔP/Δw1 = (a-y) * y*(1-y) * w2 * z*(1-z) * x
从公式看出,w2依赖于邻近的y和z,而w1除了依赖于邻近的x、y和z之外,还依赖于w2。
即便我们有N多个层的神经元,每个权重只依赖于它相邻的值以及上一层(我们这个例子,w2在w1之前)的权重。这就是反向神经网络传播。我们刚刚从右端推导到了左端。根据最终结果,首先推算出最邻近的w值,再算出下一列的w值,然后一列一列追溯上去,直到最末端,而且每一列的计算量差不多是相同的,不会有很大差别。
【说句题外话,在N多个算法中,我们已经看到很多类似的技巧,比如阈值替代,凹凸函数求极值,决策规则,概率....等等。包括这个,“一个变量的状态只和它相邻的数值有关联”,很容易让我想起马尔科夫模型,这就给我了一个启发,很多算法可以试着找出它们技巧的关键点,联合起来学习】
神经网络模型的训练,会存在过拟合的问题,因为它其实类似于曲线拟合。但曲线拟合可以有其它很多种方式,所以,有一种观点我是非常认同,并没有哪一个特别神奇的算法(包括后面可能继续写到的SVM算法)。在面对不同的问题时,重要的是如何将原始数据转换成输入向量,来有效反应问题本质,这个我觉得才是最难的。Sean即便把他那套预测股价走势的算法告诉我,我也肯定不会超越他,因为将原始数据转换成输入向量这一点,至少在股票问题上,我肯定是完败的。
本人水平有限,如果有错误的地方,希望各位大神能够不吝赐教,及时指正。
抛砖引玉,献丑,献丑。