https://juejin.im/post/5ae283c4f265da0b886d2323#comment
LeNet5:(5层)
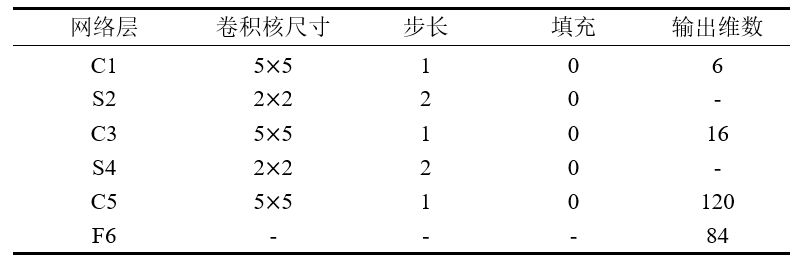
将BP算法应用到神经网络中,手写数字体识别问题
AlexNet:(2012)(7层)(参数量增大,模型复杂)
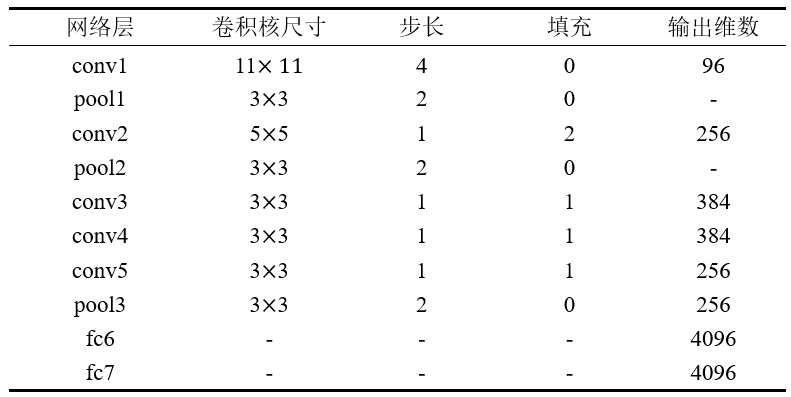
1、数据增强(水平翻转、随机裁剪、平移变换、颜色光照变换)
2、DropOut:防止过拟合,加快网络训练,有模型集成的效果
3、引入ReLU激活函数,而避免或抑制网络训练时的梯度消失现象,网络模型的收敛速度会相对稳定
4、 Local Response Normalization:Local Response Normalization要硬翻译的话是局部响应归一化,简称LRN,实际就是利用临近的数据做归一化。这个策略贡献了1.2%的Top-5错误率。
5、 Overlapping Pooling:Overlapping的意思是有重叠,即Pooling的步长比Pooling Kernel的对应边要小。这个策略贡献了0.3%的Top-5错误率。 (这里的pool层是3*3,stride=2)
6、多GPU并行
ZFNet:(7层)主要贡献在于在一定程度上解释了卷积神经网络为什么有效,以及如何提高网络的性能(参数量和AlexNet类似)
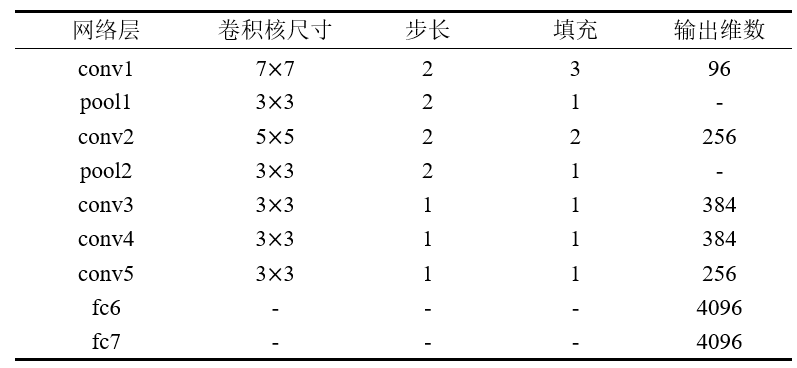
1、使用了反卷积网络,可视化了特征图。通过特征图证明了浅层网络学习到了图像的边缘、颜色和纹理特征,高层网络学习到了图像的抽象特征;
2、根据特征可视化,提出AlexNet第一个卷积层卷积核太大,导致提取到的特征模糊;
3、通过几组遮挡实验,对比分析找出了图像的关键部位;
4、论证了更深的网络模型,具有更好的性能。
VGG:(参数量增大)
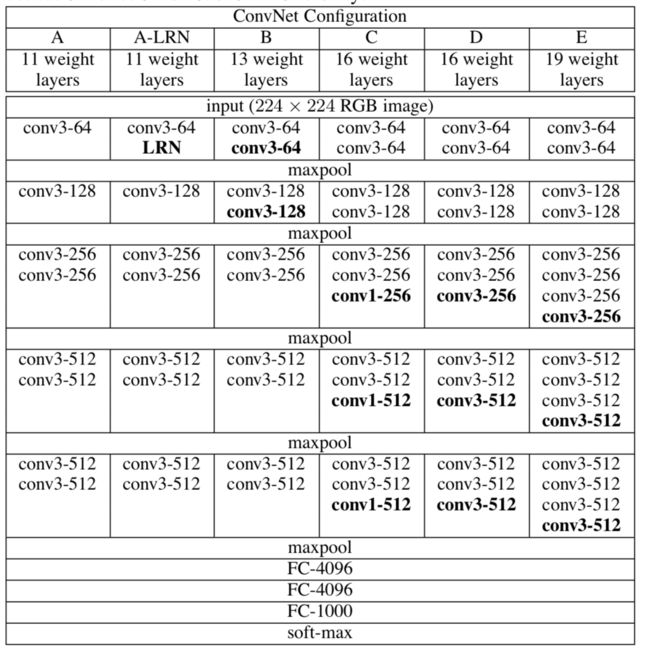
通过反复堆叠3*3的卷积层和2*2的池化层,VGG16构建了较深层次的网络结构,整个网络的卷积核使用了一致的3*3的尺寸,最大池化层尺寸也一致为2*2。
1、Vgg16有16层网络,AlexNet只有8层;
2、在训练和测试时使用了多尺度做数据增强。
3、使用3*3代替5*5的卷积核
Network in Network(NIN)的启发,NIN有两个贡献:
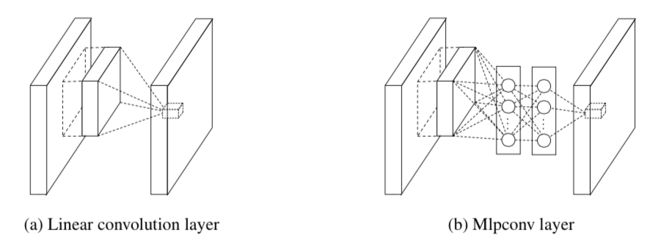
1、提出多层感知卷积层:使用卷积层后加上多层感知机,增强网络提取特征的能力。普通的卷积层和多层感知卷积层的结构图如图所示,Mlpconv相当于在一般的卷积层后加了一个1*1的卷积层;
2、提出了全局平均池化替代全连接层,从上文计算的LeNet5,AlexNet网络各层的参数数量发现,全连接层具有大量的参数。使用全局平均池化替代全连接层,能很大程度减少参数空间,便于加深网络,还能防止过拟合。
https://blog.csdn.net/hejin_some/article/details/78636586
GoogleNet:(相比于vgg,层数更深,但是参数量却降低)
进一步增加了网络模型的深度和宽度,但是单纯的在VGG16的基础上增加网络的宽度深度会带来以下缺陷:
1、过多的参数容易引起过拟合;
2、层数的加深,容易引起梯度消失现象。
特点:
1、多头梯度回传
2、增加宽度
3、全连接层之前,做mean-pooling(细节与整体信息的权衡),卷积到全连接层
inception后的聚合是concat操作
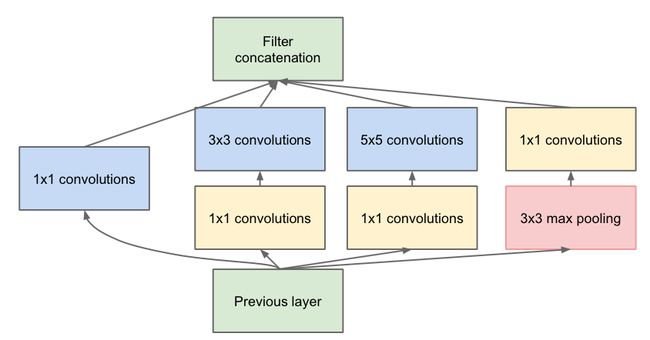
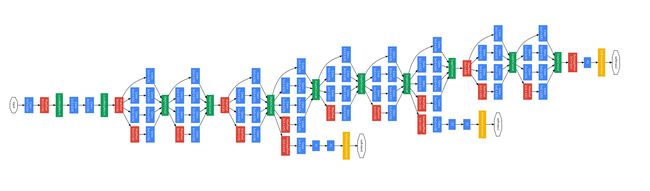
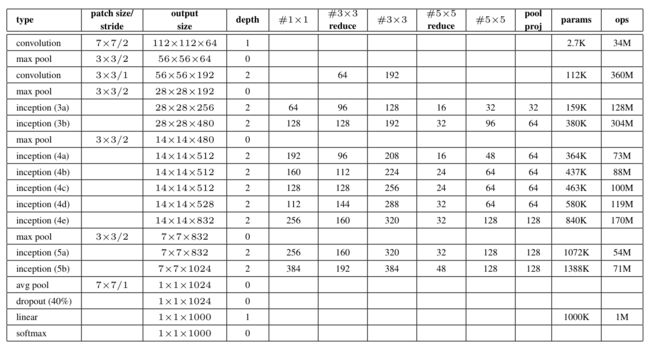
v2:
contributions:
1、两个3*3的卷积代替5*5的大卷积,在降低参数的同时建立了更多的非线性变换,使得 CNN 对特征的学习能力更强
两个3*3能够代替5*5的原因:
(1)感受野相同
(2)在具有同样感受野的情况,2个3*3 的卷积核,增加了网络深度,且经过两次非线性变换,具有更好的特征学习能力
(3)2个3*3卷积核,减少参数量
2、 提出Batch Normalization
v3:
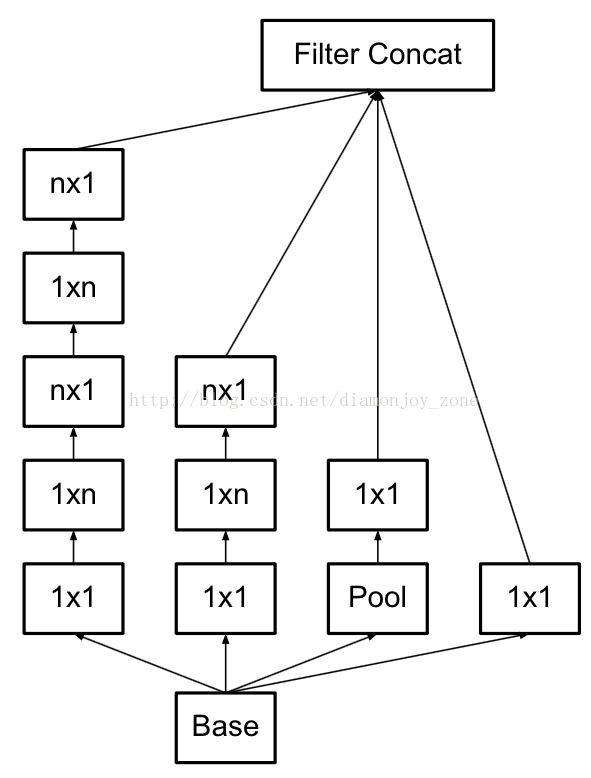
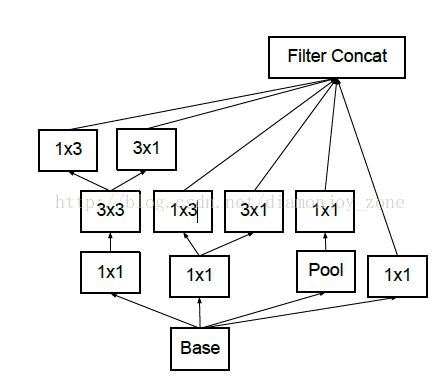
1、是引入了 Factorization into small convolutions 的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如将7´7卷积拆成1´7卷积和7´1卷积,或者将3´3卷积拆成1´3卷积和3´1卷积,如上图所示。一方面节约了大量参数,加速运算并减轻了过拟合(比将7´7卷积拆成1´7卷积和7´1卷积,比拆成3个3´3卷积更节约参数),同时增加了一层非线性扩展模型表达能力。论文中指出,这种非对称的卷积结构拆分,其结果比对称地拆为几个相同的小卷积核效果更明显,可以处理更多、更丰富的空间特征,增加特征多样性。
能够用1*3和3*1代替3*3的原因:
假如是两个高斯核,是完全等价的。如果不是的话,也可以近似等价。此外,还可以降低参数量。
2、另一方面,Inception V3 优化了 Inception Module 的结构,现在 Inception Module 有35´35、17´17和8´8三种不同结构。这些 Inception Module 只在网络的后部出现,前部还是普通的卷积层。并且 Inception V3 除了在 Inception Module 中使用分支,还在分支中使用了分支(8´8的结构中),可以说是Network In Network In Network。
v4:
引入skip connection。
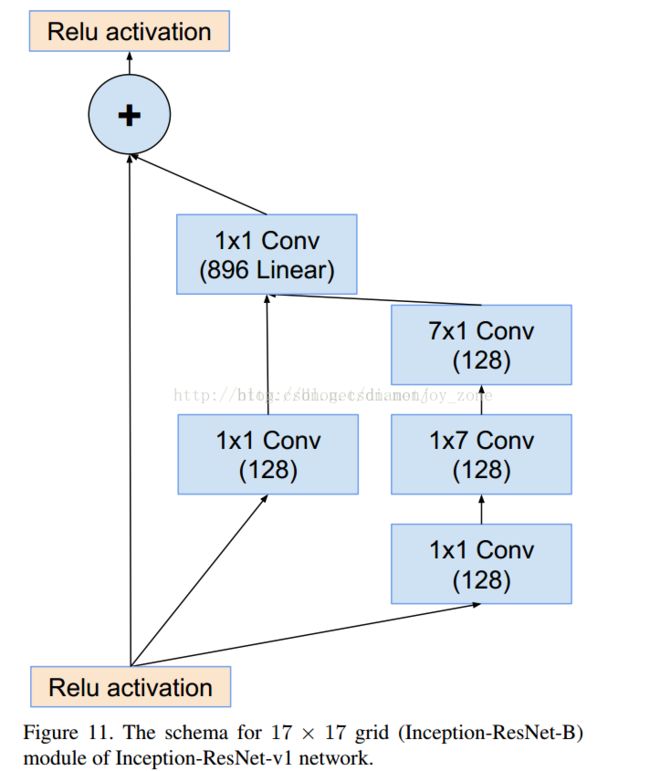
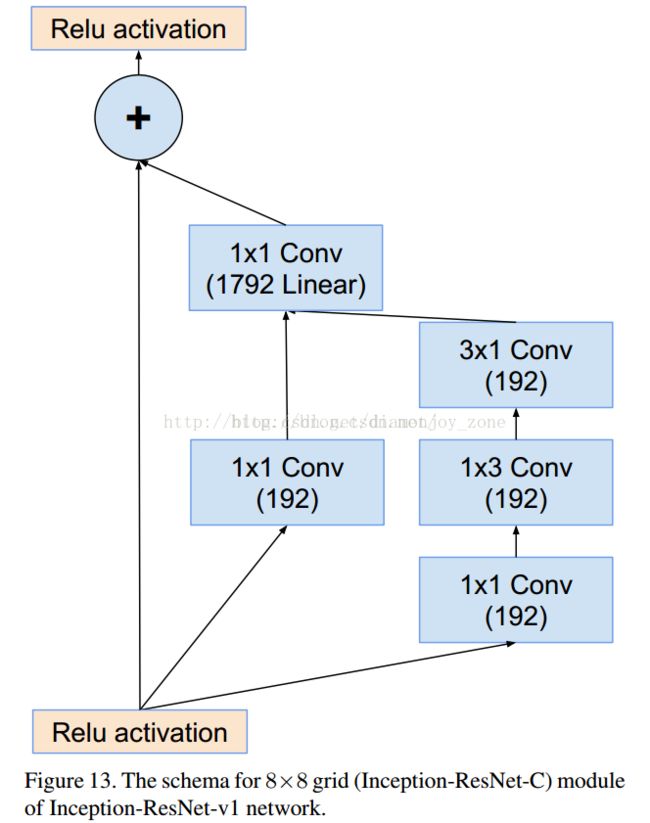
ResNet:
模型的直接加深引入的退化问题,网络不能够训练
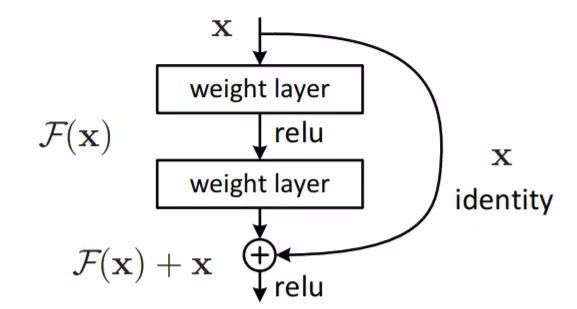
1、反复增加原始信号,而且有利于梯度的反向传播(网络深度加深时,会出现梯度消失)
2、残差,输出与输入的差异,element-wise的加叠
3、bootleNeck:减少计算量
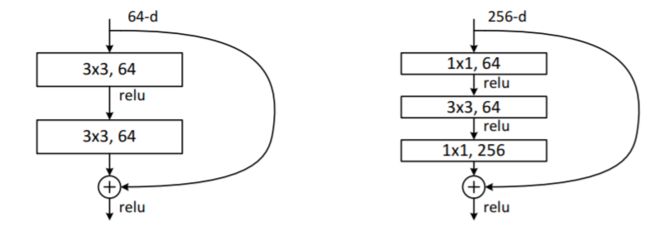
4、虚线连接:增加深度 (维度不一致时)
short connect 三种方式:
- 使用恒等映射,如果residual block的输入输出维度不一致,对增加的维度用0来填充;
- 在block输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致;
- 对于所有的block均使用线性投影。
5、计算量小(想比于同级别的vgg19)
RexNet-v2:
v2的结构与v1的区别如下:
v2比v1好的原因:
1)反向传播基本符合假设,信息传递无阻碍;
2)BN层作为pre-activation,起到了正则化的作用;
ResNeXt:
https://www.jianshu.com/p/7478ce41e46b
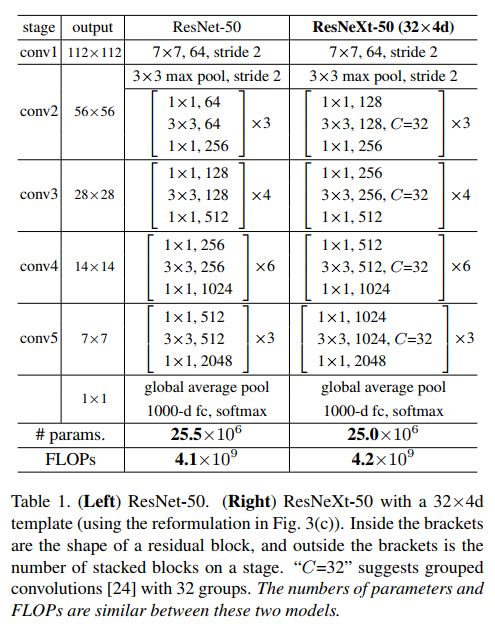

ResNeXt网络结果的变形如上图
上面图中显示了三种ResNeXt网络模块的变形。它们在数学计算上是完全等价的,而第三种包含有Group convolution操作的正是最终ResNeXt网络所采用的操作。
DenseNet: (CVPR2017)(参数和计算比resnet更好,性能更优)
https://www.jianshu.com/p/7478ce41e46b
https://www.leiphone.com/news/201708/0MNOwwfvWiAu43WO.html

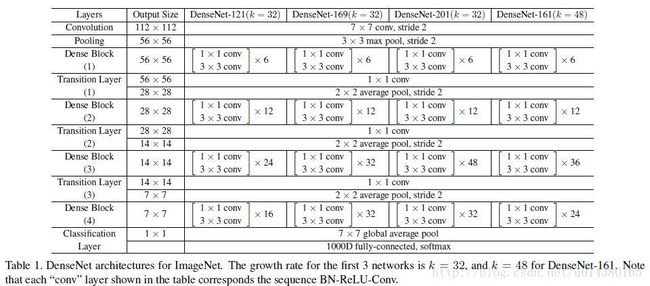
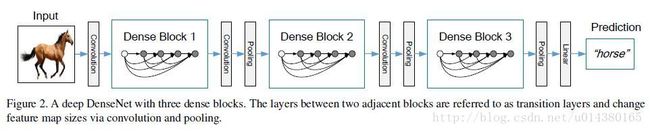
启发:
作者提出的随机深度网络(Deep networks with stochastic depth),就是在ResNet的基础上,随机drop一些层,可以显著提高泛化性能。
1、网络并不一定要是一个递进层级结构
2、drop层,不影响收敛和预测结果,说明结构存在冗余
https://www.jianshu.com/p/8a117f639eef
https://www.leiphone.com/news/201708/0MNOwwfvWiAu43WO.html
1,减轻了消失梯度(梯度消失)
2,加强了特征的传递
3,更有效地利用了特征
4,一定程度上较少了参数数量
5、文中还用到dropout操作来随机减少分支,避免过拟合
- dense net 能够减少feature的个数,源于原来的网络结构是递进氏的,不能重复提取特征,所以需要更多的features,一次提取尽可能多的特征。但是现在是密集连接,每一层都能看到前面的所有层,所以可以减少feature的个数,在需要的时候从前面的特征中学习。
- 密集连接后,采用concat操作聚合
- 最后是global average pooling,后接分类的全连接。
SENet:(加入SE 的模块,参数量和计算量基本没有增加)(CVPR2018)
https://www.jianshu.com/p/7244f64250a8
1、做通道信息的整合,之前都是做空间的(关注于卷积核的设计)
3个步骤:
1、squeeze:使用global average pooling作为Squeeze操作。
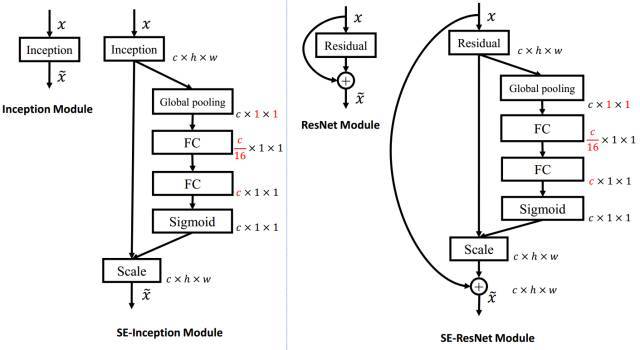
2、Excitation:紧接着两个Fully Connected 层组成一个Bottleneck结构去建模通道间的相关性,并输出和输入特征同样数目的权重。我们首先将特征维度降低到输入的1/16,然后经过ReLu激活后再通过一个Fully Connected 层升回到原来的维度。这样做比直接用一个Fully Connected层的好处在于:
1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;
2)极大地减少了参数量和计算量。然后通过一个Sigmoid的门获得0~1之间归一化的权重,
3、Reweight:通过一个Scale的操作来将归一化后的权重加权到每个通道的特征上。
SE-ResNet:
在Addition前对分支上Residual的特征进行了特征重标定。如果对Addition后主支上的特征进行重标定,由于在主干上存在0~1的scale操作,在网络较深BP优化时就会在靠近输入层容易出现梯度消散的情况,导致模型难以优化。
轻量化神经网络结构:
SqueezeNet、 MobileNet、 ShuffleNet、Xception(Xception 并不是真正意义上的轻量化模型,只是其借鉴 depth-wise convolution,而 depth-wise convolution 又是上述几个轻量化模型的关键点)
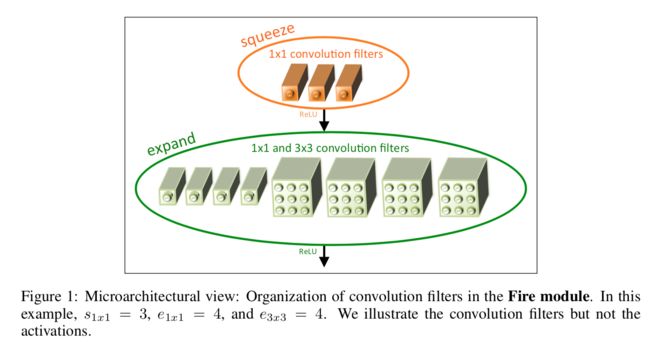
SqueezeNet:
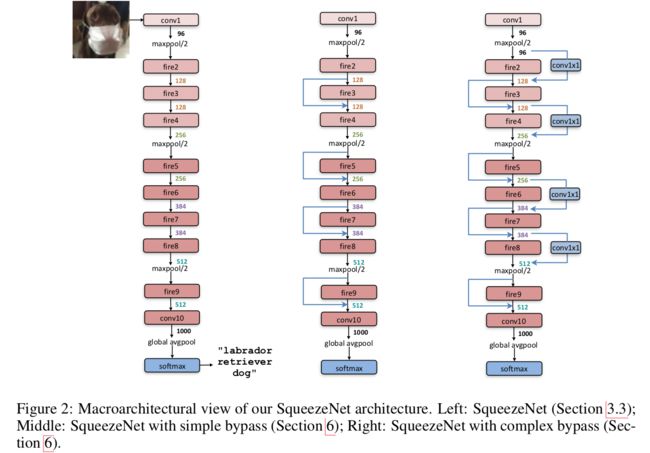
最主要的是fire module结构,fire module 包含两部分:squeeze 层+expand 层
- squeeze 层,就是 1*1 卷积
-
Expand 层分别用 1*1 和 3*3 卷积,然后 concat
 屏幕快照 2019-08-26 上午11.49.23.png
屏幕快照 2019-08-26 上午11.49.23.png
 屏幕快照 2019-08-26 上午11.52.05.png
屏幕快照 2019-08-26 上午11.52.05.png
小结:
1 Fire module 与 GoogLeNet 思想类似,采用 1*1 卷积对 feature map 的维数进行「压缩」,从而达到减少权值参数的目的;
2 采用与 VGG 类似的思想——堆叠的使用卷积,这里堆叠的使用 Fire module,SqueezeNet 与 GoogLeNet 和 VGG 的关系很大!
3、最终参数进行了压缩。才小于0.5M,并非网络本身参数就这么小。
MobileNetV1:
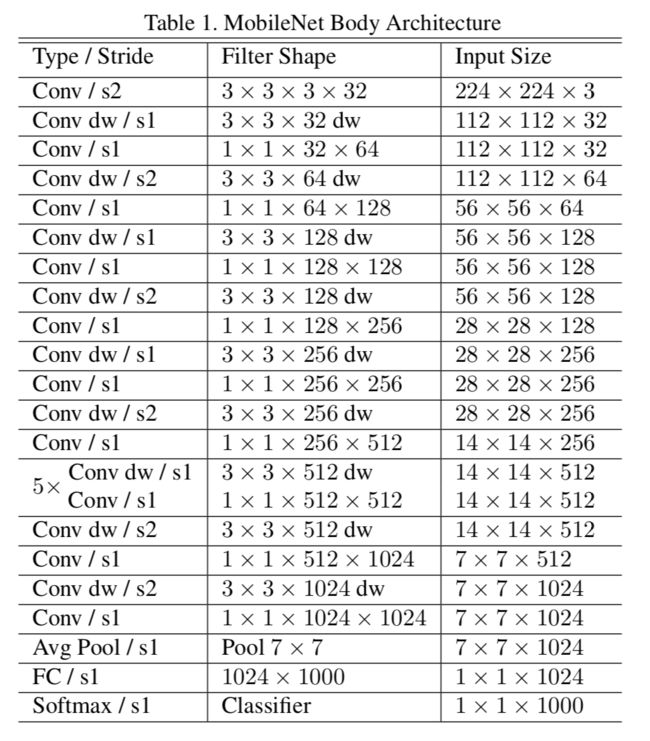
主要是采用深度可分离卷积的思想(并非原创,而是借鉴),两阶段,depthwise conv 和point conv(1*1卷积)
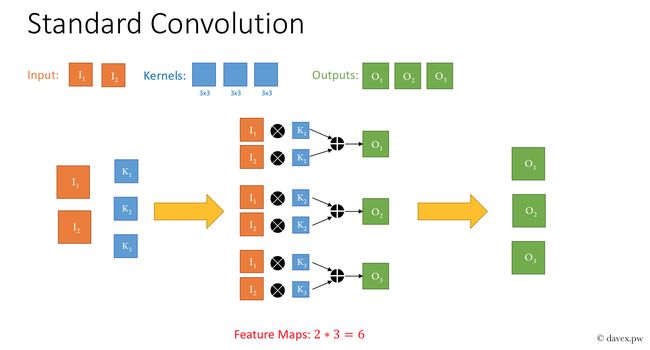
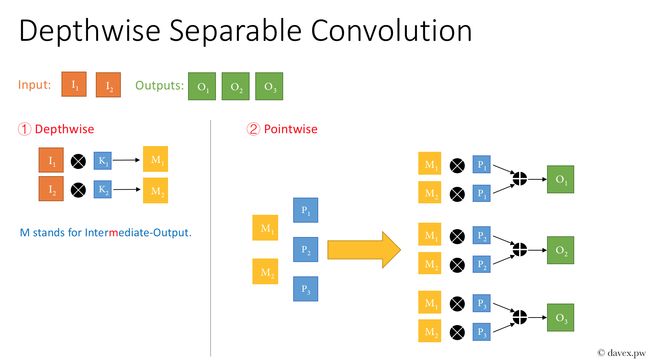
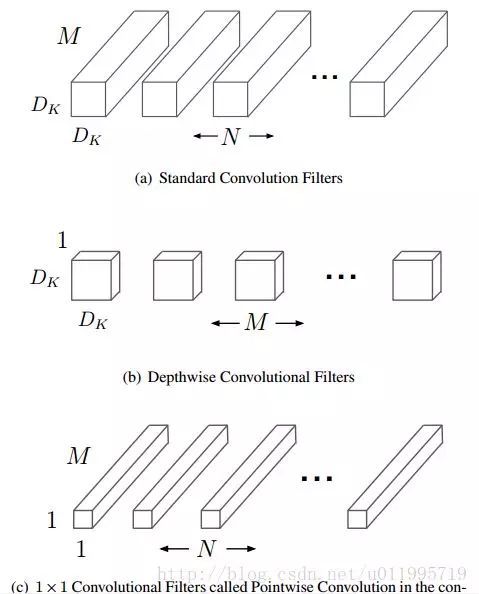
1. 核心思想是采用 depth-wise convolution 操作,在相同的权值参数数量的情况下,相较于 standard convolution 操作,可以减少数倍的计算量,从而达到提升网络运算速度的目的。
2. depth-wise convolution 的思想非首创,借鉴于 2014 年一篇博士论文:《L. Sifre. Rigid-motion scattering for image classification. hD thesis, Ph. D. thesis, 2014》
3. 采用 depth-wise convolution 会有一个问题,就是导致「信息流通不畅」,即输出的 feature map 仅包含输入的 feature map 的一部分,在这里,MobileNet 采用了 point-wise convolution 解决这个问题。在后来,ShuffleNet 采用同样的思想对网络进行改进,只不过把 point-wise convolution 换成了 channel shuffle
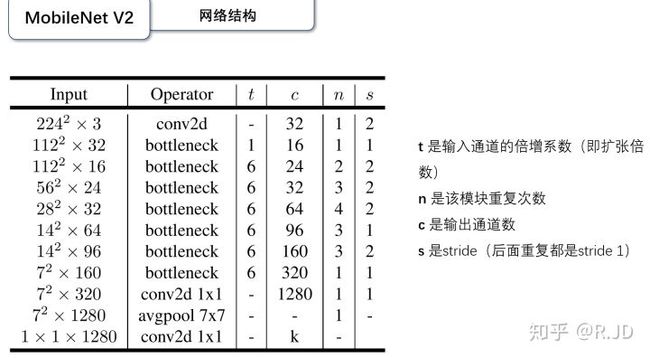
MobileNetV2:
创新点:
1、将ReLU替换成线性激活函数。将结构最后的RELU替换为线性激活函数。
2、DWConv,通道较少,表达能力有限,所以在进行DWConv之前,通过1*1卷积升维。

3、MobileNetV1中的整体结构与VGG类似,所以像resnet引入shortcut结构。
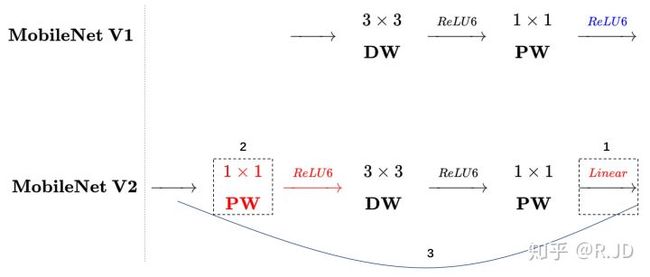
对比MobileNetV2与ResNet结构:
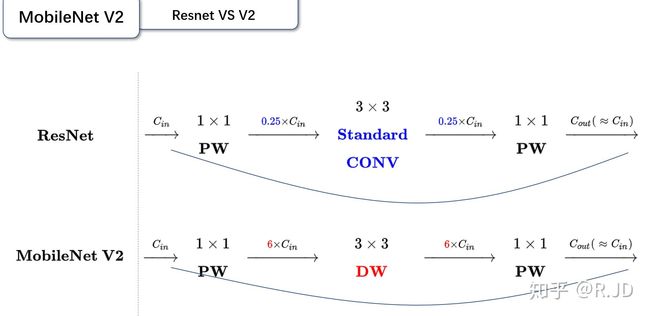
可以发现,都采用了 1×1 -> 3 ×3 -> 1 × 1 的模式,以及都使用Shortcut结构。但是不同点呢:
- ResNet 先降维 (0.25倍)、卷积、再升维。
- MobileNetV2 则是 先升维 (6倍)、卷积、再降维
v2的block结构为:
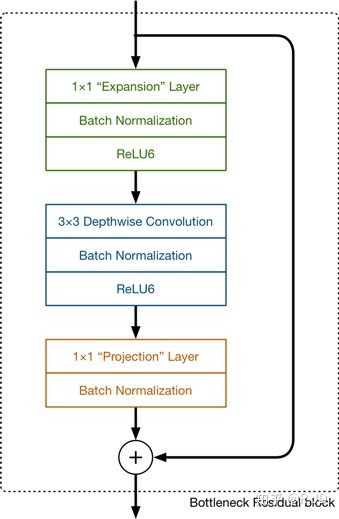
v1与v2结构对比:
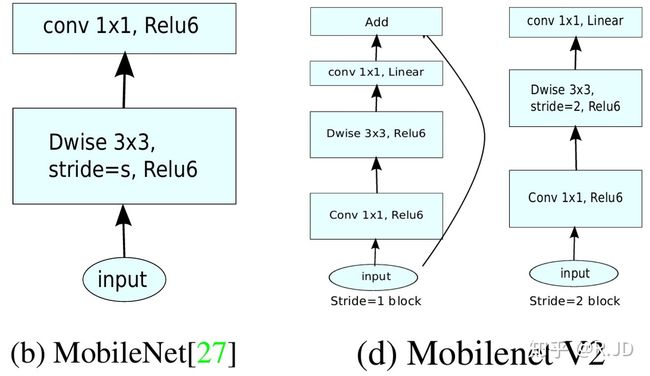
MobileNetV3:
0.网络的架构基于NAS实现的MnasNet(效果比MobileNetV2好)
1.引入MobileNetV1的深度可分离卷积
2.引入MobileNetV2的具有线性瓶颈的倒残差结构
3.引入基于squeeze and excitation结构的轻量级注意力模型(SE)
4.使用了一种新的激活函数h-swish(x)
5.网络结构搜索中,结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt
6.修改了MobileNetV2网络端部最后阶段
mobilenet详细参考:
https://zhuanlan.zhihu.com/p/70703846
ShuffleNet:
https://blog.csdn.net/u011974639/article/details/79200559
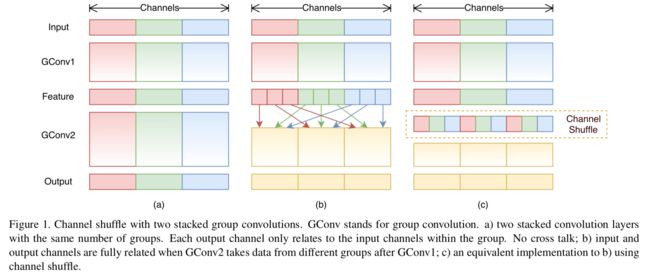
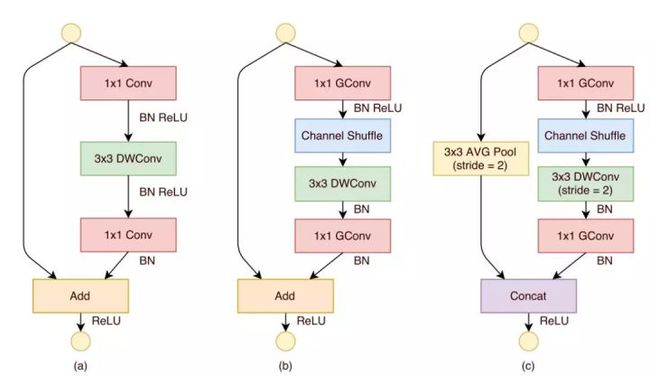
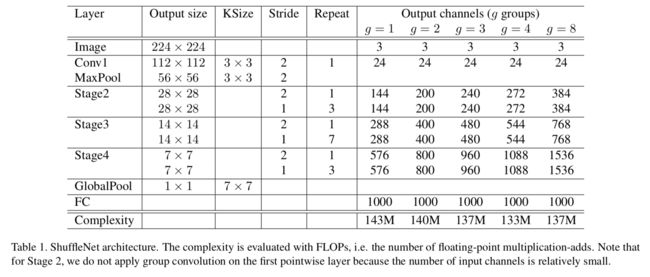
创新:
1. 利用 group convolution 和 channel shuffle 这两个操作来设计卷积神经网络模型, 以减少模型使用的参数数量。
2、与 MobileNet 一样采用了 depth-wise convolution,但是针对 depth-wise convolution 带来的副作用——「信息流通不畅」,ShuffleNet 采用了一个 channel shuffle 操作来解决。
3、 在网络拓扑方面,ShuffleNet 采用的是 resnet 的思想,而 mobielnet 采用的是 VGG 的思想,SqueezeNet 也是采用 VGG 的堆叠思想
Xception:(inception-v3的改进,参数量没有减少太多,精度略有提升)
Xception 结构如下图所示,共计 36 层分为 Entry flow;Middle flow;Exit flow。
Entry flow 包含 8 个 conv;Middle flow 包含 3*8 =24 个 conv;Exit flow 包含 4 个 conv,所以 Xception 共计 36 层。
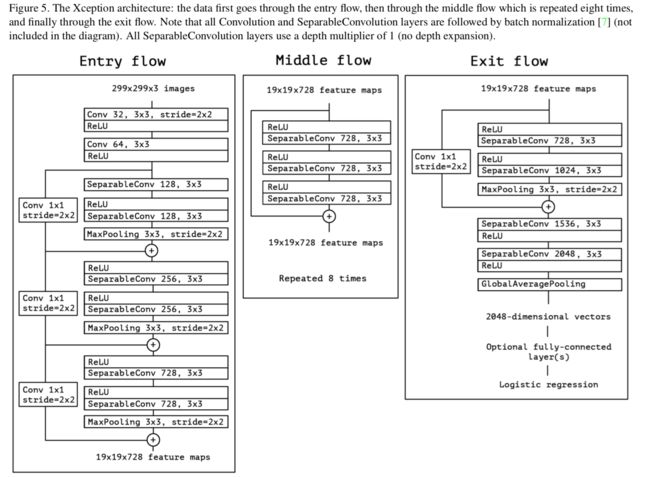
https://www.jianshu.com/p/470a1de97487
https://www.jianshu.com/p/4708a09c4352
Xception是google在inception之后提出的对inceptionV3的另一种改进,主要采用depthwise separable convolution来替换原来的inception v3中的卷积操作。
创新:
1. 借鉴(非采用)depth-wise convolution 改进 Inception V3
简单理解就是说,卷积的时候要将通道的卷积与空间的卷积进行分离,这样会比较好。(没有理论证明,只有实验证明,就当它是定理,接受就好了,现在大多数神经网络的论文都这样。
第一个:原版 Depth-wise convolution,先逐通道卷积,再 1x1 卷积; 而 Xception 是反过来,先 1x1 卷积,再逐通道卷积;
第二个:原版 Depth-wise convolution 的两个卷积之间是不带激活函数的,而 Xception 在经过 1x1 卷积之后会带上一个 Relu 的非线性激活函数;
对比轻量化网络:
轻量化策略:

- 这么一看就发现,轻量化主要得益于 depth-wise convolution,因此大家可以考虑采用 depth-wise convolution 来设计自己的轻量化网络,但是要注意「信息流通不畅问题」。
- 解决「信息流通不畅」的问题,MobileNet 采用了 point-wise convolution,ShuffleNet 采用的是 channel shuffle。MobileNet 相较于 ShuffleNet 使用了更多的卷积,计算量和参数量上是劣势,但是增加了非线性层数,理论上特征更抽象,更高级了;ShuffleNet 则省去 point-wise convolution,采用 channel shuffle,简单明了,省去卷积步骤,减少了参数量。