“
Apache Kylin是首个完全由中国团队设计开发,并贡献到Apache软件基金会(ASF)的顶级项目,开源一年左右的时间,已经在国内国际多个公司被采用作为大数据分析平台的关键组成部分,拥有大量用户案例。
魅族大数据平台架构师赵天烁在 8月13日的【创客168】第7期:大数据平台架构及应用实践 和 9月22日的第三届互联网应用技术峰会上 进行了“大数据多维分析引擎在魅族的实践”的分享。
Apache Kylin 近日获得授权分享这则案例,希望对您有所帮助。
在此感谢赵天烁先生的精彩分享。
分享人:赵天烁
珠海魅族科技有限公司,魅族大数据平台架构师,先后在多个创业团队负责数据平台体系的搭建,后进入阿里数据应用团队,负责自助分析平台等多个核心数据应用设计实现。目前专注在大数据、云计算领域,探索二者的结合之道,从而更好的发挥数据的价值。
Kylin这匹神兽在大数据圈儿内已经逐渐成为一个无法忽视的存在,它让你能够通过标准SQL(ANSI SQL子集)在一个100亿+记录的表中进行多维分析查询,并且结果能够在秒级返回,这一特性让它成为很多开放式,高并发量数据分析服务的上佳选择,今天就让我们来一探究竟,看看Kylin是如何做到以上这些特性的,还有魅族自己的应用场景、平台化思路和一些部署运维上的经验。
这里还是要推荐下小编的大数据学习QQ裙:532218147,不管你是小白还是大牛,小编我都欢迎,不定期分享干货,包括小编自己整理的一份2018最新的大数据资料和0基础入门教程,欢迎初学和进阶中的小伙伴。在不忙的时间我会给解答
关于 Apache Kylin
Extreme OLAP Engine for Big Data
Apache Kylin 是一个开源的分布式分析引擎,为Hadoop等大型分布式数据平台之上的超大规模数据集提供通过标准SQL查询及多维分析(OLAP)的功能,提供亚秒级的交互式分析能力。
Apache Kylin 架构
空间换时间

Apache Kylin 基本原理
Layer Cubing

Fast Cubing

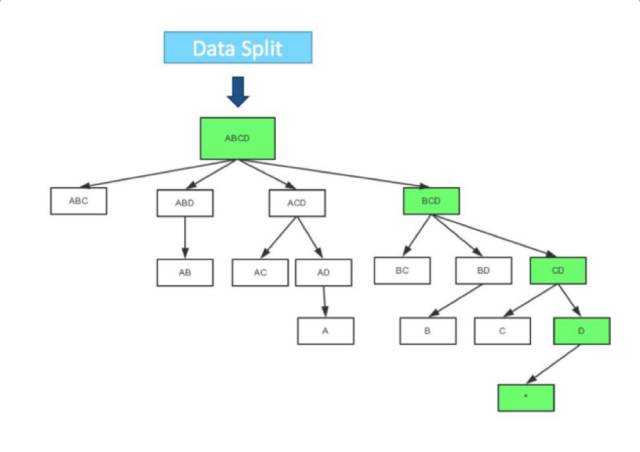
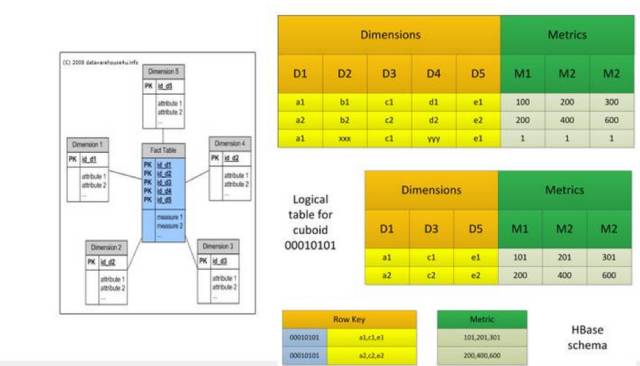
How to Store Cube Data
Query Engine
Kylin Explain Plan

Web UI
REST API

最新特性
可扩展插件式架构
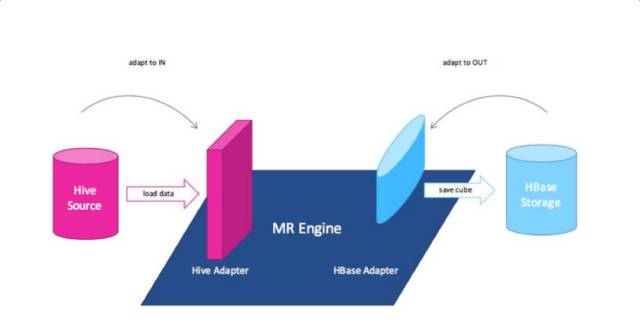

可扩展架构将Kylin的三大依赖(数据源、Cube引擎、存储引擎)彻底解耦。Kylin将不再直接依赖于Hadoop/HBase/Hive,而是把Kylin作为一个可扩展的平台暴露抽象接口,具体的实现以插件的方式指定所用的数据源、引擎和存储。
Parallel Scan

Streaming Cubing
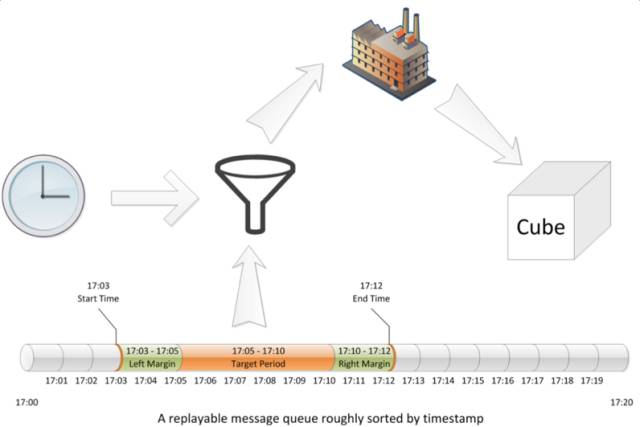
其他重要新特性
- 支持精确的Distinct计数(所有数据类型);
- 支持针对不同的Project设置不同的MR job运行队列;
- Top N指标支持多列Group By;
- 主动监测OOM,将堆栈中的Cuboid缓存到本地磁盘;
- 查询明细数据(RAW MEASURE);
- 支持Hive视图作为Lookup 表。
业界案例
京东@云海 JCloud

Why Kylin?
- 平台体系完善,成熟度高,部署简单,易用;
- 在高并发访问下保持不错的性能,随着数据量和维度组合的增长,性能衰减也不会特别明显;
- Cube模型的合理设计,可以减少人工配置 ETLjob的数量;
- 可以在数据准确度、存储空间、性能之间灵活调整,找到最适合需求场景的平衡点;
- 标准SQL语法+JDBC/ODBC驱动可以很方便的和现有系统做集成;
- 社区活跃,有Kyligence这样的商业公司在背后推动。
Key Feature和“坑”
- 支持Offset;
- 支持已定义范围内,Group By维度自由组合;
- 维度可以作为Where条件过滤;
- Order By 可以是维度或指标;
- 支持Join(仅限于事实表和Lookup Table,Lookup Table可以多个);
- Top N只支持Sum类型的指标;
- 日期增量数据Where条件最好包含日期范围,不然HBase Scan会超时。
应用场景特征
- 数据量大,同时对查询性能有需求;
- 数据实时性要求不高(目前最高到小时级更新);
- 维度组合和查询条件组合在可预见的范围内;
- 数据总量大,但条件扫描范围不会太大的;
- 不适合需要大范围模糊搜索排序的场景(类似Search)。
魅族的部署模式
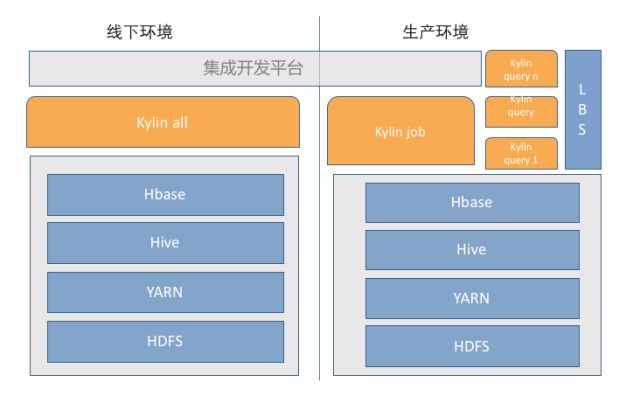
魅族应用案例
- 单个Cube最大维度9个,数据量6亿,存储空间600G;
- 一个基数千万级维度;
- 1个基数百万级维度;
- 其他维度基数在10w以内。
查询场景:
select max(xxx),min(xxx),cout(distinct xxx),count(1),dimension1,dimension2, from T where
partition_date>=xxxxx and partition_date<=xxxxx and
(其他维度的随机参数组合)
order by count(1) desc limit 20 offset 100
性能:
- 平均响应时间50%在1s以内,30%在2s以内,10%在5秒以内;
- 少量大范围扫描的SQL时间在10秒左右;
- 以上性能是不命中Cache的首次查询,Kylin自带内存Ehcache。
魅族Cube优化实践
优化前
- Cube原始记录 6亿(一个月数据 );
- Build后的Cube Size 1.9T ;
- 单次查询扫描一周数据,HBase频繁超时,Region Server经常被拖死,平均响应时间近30s。
活用Aggregation Groups
http://kylin.apache.org/blog/2016/02/18/new-aggregation-group/
- 将使用场景进行分组,对应不同的Group;
- 大基数维度创建单独的Group,尽量确认需求,收缩条件组合范围,Include中只包含相关的维度;
- 低基数的维度可以单独建立一个Group,加上必选条件维度,把低基数的维度都设置成Mandatory,这样维度组合出现时kylin会灵活进行内存内二次聚合,但因为这些维度基数都不大,对性能不会影响太多;
- 二选一或多选一的条件维度不要包含在统一个Group(比如崩溃时间和上传时间);
- 同时有好几个大基数Group的话可以考虑每个Group单独建一个Cube(避免Cube膨胀,Row Key结构也更合理)。
kylin.query.mem.budget
Rowkey
- 有日期分区字段的,可以将日期转成只包含变化范围的数字:
比如原始格式是字符串的2016-07-15 12:31:25,只保留一个月的数据,同时查询是按天维度Group By 不关心小时分钟可以把日期转成yyMMdd ,160715,这样可以极大的降低维度基数;
- 基数小的维度在前面;
- 低基数的维度尽量用Dict编码(100w以内)。
层级维度/派生维度
http://kylin.apache.org/docs15/howto/howto_optimize_cubes.html
优化效果
- Cube Build后大小降低到500G上下;
- 50%的查询性能在2s以内;
- Cube Build时间缩短30%。
平台集成
对接集成开发平台

常见问题
Q1 - 对mdx支持情况如何?
现在不支持MDX查询,查询入口是SQL,像Saiku这种基于MDX的操作,社区已经有人贡献了Mondrian Jar包,可以将Saiku 前台提供的MDX转换为SQL,再通过JDBC Jar发送到Kylin Server,不过功能上有所限制,Left Join, Top N, Count Distinct支持受限。
Q2 - 麒麟针对出来T级别的数据,每日制作cube大约话费多久时间?
具体Cube构建时间视不同情况而定,具体取决于Dimension数量及不同组合情况、Cardinality大小、源数据大小、Cube优化程度、集群计算能力等因素。在一些案例中,在一个Shared Cluster构建数十GB的数据只需要几十分钟。建议大家在实际环境先进行测试,寻找可以对Cube进行优化的点。此外,一般来说,Cube的增量构建可以在ETL完成后由系统自动触发,往往这个时间和分析师做数据分析是错峰的。
Q3 - 如何向Kylin提交代码?
将修改的代码用Git Format-Patch做成Patch文件,然后Attache在对应的Jira上,Kylin Committer会来Review,没有问题的话会Merge到开发分支。
Q4 - 如果数据是在Elastic Search,Kylin的支持如何?
目前还不支持直接从ES抽取数据,需要先导出到Hive再做Cube Build;有兴趣的同学可以基于Kylin 1.5的Plugin架构实现一个ES的Data Source。
Q5 - 工作的比较好的前端拖拽控件有什么?
目前应该是Tableau支持较好,Saiku支持不是很好,有些场景如Left Join, Count Distinct, Top N支持不是很好,用户是可以基于API开发自己的拖拽页面的。
Q6 - 对多并发支持表现如何?
Kylin和其他MPP架构技术想必一大优势就在高并发。一台Kylin的Query Server就支持几十到上百的QPS (取决于查询的复杂度,机器的配置等因素),而且 Kylin支持良性的水平扩展,即增多Kylin Server和HBase节点就可迅速增大并发。
Q7 - Kylin可以整合Spark Machine Learning和Spark SQL吗?
基于前面讲到的可插拔架构,是可以整合的。
Q8 - 跟其它工具对比,有没有考虑Cube的构建时间?因为人家是实时计算的,你是预计算的,这从机理上是不一样的。
Kylin跟其它MPP架构的技术在查询性能的对比,时间里是不含Cube构建的时间的,所以从某种意义上来讲这样的对比是有些不公平。但是,从用户角度来看,分析师和最终用户只关心查询性能,而Kylin用预计算能大大提高查询速度,这正是用户所需要的!
Q9 - Kylin ODBC 驱动程序有示例代码?
目前代码在Master分支,欢迎大家加入社区一起贡献。
Q10 - 4亿数据有点少,麒麟有没有做过相关的Benchmark ,在百亿级别数据,十个纬度的情况下,表现如何?
来自社区的测试数据,在一个近280亿条原始数据的Cube(26TB)上,90%的查询在5秒内完成。
Q11 - 数据量翻倍的话,空间使用会做指数级增长么?
通常Cube的增长与原数据的增长基本一致,即原数据翻倍,Cube也翻倍,或者更小一些, 而非指数增长。