无序关联容器
无序关联容器(Unordered associative container)是C++11标准库中新增的类型,包括
- unordered_set
- unordered_multiset
- unordered_map
- unordered_multimap
共四种类型,它们的共同特点是
在容器内部,元素的排列是没有特定顺序的,这也正是它们被叫做“unordered container”的原因。
都是通过hast table实现的。这点我们稍后会详细介绍。
标准库中已经有了map和set,为什么还要定义unordered的map和set呢?答案还是那两个字:效率。我们知道,map和set的底层数据结构是红黑树,执行查找、插入,删除等操作的时间复杂度为O(logn);而unordered map和unordered set的底层数据为hash table,执行查找、插入和删除等操作的时间复杂度为O(1),明显要快很多,所以如果对元素的排列顺序没有要求,建议使用无序关联容器。
既然无序关联容器都是基于hash table的,那我们就有必要先了解一下C++ 11中的hash算法。
C++ 11中的hash算法
C++ 11标准对如何计算hash有明确的要求:
- hash方程应该是一个
function object,声明如下所示:
template
struct hash {
size_t operator()(T key) const noexcept;
};
对于类型为
T的参数t1和t2,如果t1 == t2,则hash;()(t1) == hash ()(t2) 对于类型为
T的参数t1和t2,如果t1 != t2,则hash的概率应近似于()(t1) == hash ()(t2) 1.0/std::numeric_limits(在我的MacBook Pro上,这个值为0.00000000000000000005.421,小数点后面19个::max() 0)。
不过,C++标准只是规定了hash方程的形式和必须满足的条件,具体到如何计算hash值,则没有要求。就libc++而言,针对不同的类型,其计算方法也不尽相同。
简单数值类型
对于简单数值类型,如bool、int、char等,libc++的hash算法也很简单:直接返回数值本身。
// header:
template struct hash; // forward declaration
// specialization for bool
template<>
struct hash : pubic unary_function {
size_t operator()(bool value) const noexcept {
return static_cast)(value);
}
};
// specialization for int
template<>
struct hash : public unary_function {
size_t operator()(int value) const noexcept {
return static_cast(value);
}
};
// specialization for char
template<>
struct hash : pubic unary_function {
size_t operator(char value) const noexcept {
return static_cast(value);
}
};
浮点数值类型
针对复杂数值类型,如float、double等,libc++提供了两种hash算法:murmur2和cityhash64:
// header:
template
struct murmur2_or_cityhash;
// use murmur2 on 32-bit system,
// because size_t is 32 bits on 32-bit system
template
struct murmur2_or_cityhash {
Size operator()(const void* key, Size len) {
// murmur2 hash算法
...
}
};
// use cityhash64 on 64-bit system,
// because size_t is 64 bits on 64-bit system
template
struct murmur2_or_cityhash {
Size operator()(const void* key, Size len) {
// cityhash64 hash算法
...
}
};
murmur2_or_cityhash::operator()接受两个参数,并不满足C++标准的要求,为了方便使用,libc++又定义了一个外敷类scalar_hash:
template
struct scalar_hash;
template
struct scalar_hash : public unary_function {
size_t operator()(T value) const {
union {
T t;
size_t a;
} _u;
_u.a = 0;
_u.t = value;
return _u.a;
}
};
template
struct scalar_hash : public unary_function {
size_t operator()(T value) const {
union{
T t;
size_t a;
} _u;
_u.t = value;
return _u.a;
}
};
template
struct scalar_hash : public unary_function {
size_t operator()(Tp value) const {
union {
Tp t;
struct {
size_t a;
size_t b;
} s;
} _u;
_u.t = value;
return murmur2_or_cityhash()(&_u, sizeof(_u));
}
};
template
struct scalar_hash : public unary_function {
size_t operator()(T value) const {
union {
T t;
struct {
size_t _a;
size_t _b;
size_t _c;
} s;
} _u;
_u.t = value;
return murmur2_or_cityhash()(&_u, sizeof(_u));
}
};
template
struct scalar_hash : public unary_function {
size_t operator()(T value) const {
union {
T t;
struct {
size_t a;
size_t b;
size_t c;
size_t d;
} s;
} _u;
_u.t = value;
return murmur2_or_cityhash()(&_u, sizeof(_u));
}
};
浮点数值类型最终的hash计算方法如下:
template <>
struct hash : public scalar_hash {
size_t operator()(float value) const
{
// -0.0 and 0.0 should return same hash
if (value == 0)
return 0;
return scalar_hash::operator()(value);
}
};
template <>
struct hash : public scalar_hash {
size_t operator()(double value) const
{
// -0.0 and 0.0 should return same hash
if (value == 0)
return 0;
return scalar_hash::operator()(value);
}
};
内置非数值类型
对于标准库中的非数值类型,比如string等,标准库也提供了hash方程:
// header:
template
struct hash >
: public unary_function, size_t> {
size_t operator()(const basic_string& val) const noexcept;
};
template
size_t hash >::operator()(
const basic_string& val) const noexcept {
return __do_string_hash(val.data(), val.data() + val.size());
}
__do_string_hash定义在文件<__string>中:
// header: <__string>
template
inline size_t __do_string_hash(Ptr p, Ptr e) {
typedef typename iterator_traits::value_type value_type;
return murmur2_or_cityhash()(p, (e-p)*sizeof(value_type));
}
自定义类型
如果你有一个类,
struct Foo {
int _i;
double _d;
std::string _s;
Foo(int i, double d, const std::string &s)
: _i(i), _d(d), _s(s) {}
};
你可以这样计算hash:
template<>
struct hash : public unary_function {
size_t operator()(const Foo& foo)const noexcept {
return murmur2_or_cityhash()
(static_cast(&foo), sizeof(Foo));
}
};
现在我们已经对hash算法有所了解,接下来我们就讲讲那些基于hash算法的容器是如何实现的。虽然C++ 11标准库中基于hash算法的容器一共有四种,但是它们的实现方式大同小异,所以我们就讲讲最典型的hash容器:unordered_map。
unordered_map
首先来看unordered_map的声明:
// file: unordered_map
template, class _Pred = equal_to<_key>,
class _Alloc = allocator > >
class unordered_map {
public:
// types
typedef _Key key_type;
typedef _Tp mapped_type;
typedef _Hash hasher;
typedef _Pred key_equal;
typedef _Alloc allocator_type;
typedef pair value_type;
typedef pair __nc_value_type;
typedef value_type& reference;
typedef const value_type& const_reference;
private:
typedef __hash_table<__value_type, __hasher, __key_equal, __allocator_type> __table;
__table __table_;
// ...
};
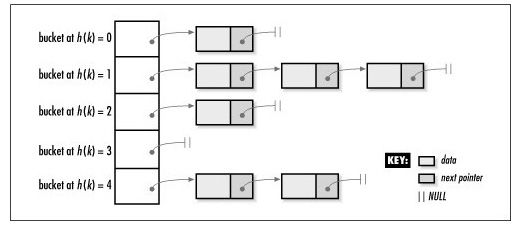
可以看到unordered_map的实现采用了Pimpl idiom,unordered_map只是个wrapper,真正的实现是在__hash_table中。要讲清楚__hash_table不是一件容易的事情,好在libc++的__hash_table从技术上讲并没有什么奇特之处,仍然采用了大家都很熟悉的bucket list形式,如下图所示:
下面正式进入__hash_table:
template
class __hash_table {
public:
typedef _Tp value_type;
typedef _Hash hasher;
typedef _Equal key_equal;
typedef _Alloc allocator_type;
private:
typedef std::allocator_traits __alloc_traits;
typedef typename __make_hash_node_types::type _NodeTypes;
public:
typedef typename _NodeTypes::__node_value_type __node_value_type;
typedef typename _NodeTypes::__container_value_type __container_value_type;
typedef typename _NodeTypes::key_type key_type;
typedef value_type& reference;
typedef const value_type& const_reference;
typedef typename __alloc_traits::pointer pointer;
typedef typename __alloc_traits::const_pointer const_pointer;
typedef typename __alloc_traits::size_type size_type;
typedef typename _NodeTypes::difference_type difference_type;
public:
// Create __node
typedef typename _NodeTypes::__node_type __node;
typedef typename std::__rebind_alloc_helper<__alloc_traits, __node>::type __node_allocator;
typedef std::allocator_traits<__node_allocator> __node_traits;
typedef typename _NodeTypes::__void_pointer __void_pointer;
typedef typename _NodeTypes::__node_pointer __node_pointer;
typedef typename _NodeTypes::__node_pointer __node_const_pointer;
typedef typename _NodeTypes::__node_base_type __first_node;
typedef typename _NodeTypes::__node_base_pointer __node_base_pointer;
typedef typename _NodeTypes::__next_pointer __next_pointer;
private:
typedef typename std::__rebind_alloc_helper<__node_traits, __next_pointer>::type __pointer_allocator;
typedef std::__bucket_list_deallocator<__pointer_allocator> __bucket_list_deleter;
typedef std::unique_ptr<__next_pointer[], __bucket_list_deleter> __bucket_list;
typedef std::allocator_traits<__pointer_allocator> __pointer_alloc_traits;
typedef typename __bucket_list_deleter::pointer __node_pointer_pointer;
// --- Member data begin ---
__bucket_list __bucket_list_;
std::pair<__first_node, __node_allocator> __p1_;
std::pair __p2_;
std::pair __p3_;
public:
size_type size() const noexcept { return __p2_.first();}
float max_load_factor() const noexcept { return __p3_.first();}
};
我们来梳理一下,每一个__hash_table都有一个__bucket_list_:
__bucket_list __bucket_list_
而__bucket_list_是一个smart pointer:
typedef typename __make_hash_node_types::type _NodeTypes;
typedef typename _NodeTypes::__next_pointer __next_pointer;
typedef std::unique_ptr<__next_pointer[], __bucket_list_deleter> __bucket_list;
这里的关键就是__make_hash_node_types:
template ::element_type>
struct __hash_node_types;
template
struct __hash_node_types<_NodePtr, __hash_node<_Tp, _VoidPtr> >
: public __hash_key_value_types<_Tp>, __hash_map_pointer_types<_Tp, _VoidPtr>{
typedef _NodePtr __node_pointer;
typedef __hash_node_base<__node_pointer> __node_base_type;
typedef typename __node_base_type::__next_pointer __next_pointer;
// ...
};
template
struct __make_hash_node_types {
typedef __hash_node<_NodeValueTp, _VoidPtr> _NodeTp;
typedef typename std::__rebind_pointer<_VoidPtr, _NodeTp>::type _NodePtr;
typedef __hash_node_types<_NodePtr> type;
};
经过这一连串让人头晕目眩的类型代换后,__bucket_list_大致可以写成:
typedef std::pair _Tp;
typedef __hash_node<_Tp, _VoidPtr>* _NodePtr;
typedef typename __hash_node_base<_NodePtr>::__next_pointer __next_pointer;
std::unique_ptr<__next_pointer[]> __bucket_list_;
__hash_node和__hash_node_base就是一切开始的地方:
// file: __hash_table
template
struct __hash_node_base {
typedef typename std::pointer_traits<_NodePtr>::element_type __node_type;
typedef __hash_node_base __first_node;
typedef typename std::__rebind_pointer<_NodePtr, __first_node>::type __node_base_pointer;
typedef _NodePtr __node_pointer;
typedef __node_base_pointer __next_pointer;
__next_pointer __next_;
};
template
struct __hash_node
: public __hash_node_base >::type> {
typedef _Tp __node_value_type;
size_t __hash_;
__node_value_type __value_;
};
纵观源代码,我们会发现90%的代码其实都是类型定义和代换,大量的typedef让人头晕目眩,真不知道这样的代码是怎样构思出来的,又是怎样测试的。
写了这么多,也仅仅是了解了__hash_table的声明而已。篇幅有限,我们不能详细讲解__hash_table具体的实现了,就挑两个方法讲一下吧:
默认构造函数
默认构造函数非常简单:
// file: __hash_table
template
inline __hash_table<_Tp, _Hash, _Equal, _Alloc>::__hash_table()
: __p2_(0), __p3(1.0f) {
}
插入元素
源代码有点复杂,不过只要看懂了__hash_table声明部分的代码,这部分代码相对来说还是比较容易的。
// file: unordered_map
pair insert(const value_type& __) {
return __table_.__insert_unique(__x);
}
// file: __hash_table
pair __insert_unique(__container_value_type&& __x) {
return __emplace_unique_key_args(_NodeType::__get_key(__x), std::move(__x));
}
template
template
pair::iterator, bool>
__hash_table<_Tp, _Hash, _Equal, _Alloc>::__emplace_unique_key_args(_Key const& __k, _Args&&... __args) {
size_t __hash = hash_function()(__k);
size_type __bc = bucket_count();
bool __inserted = false;
__next_pointer __nd;
size_t __chash;
if (__bc != 0) {
__chash = __constrain_hash(__hash, __bc);
__nd = __bucket_list_[_chash];
if (__nd != nullptr) {
for (__nd = __nd->next; __nd != nullptr && (__nd->__hash() == __hash || __constrain_hash(__nd->__hash(), __bc) == __chash);
__nd = __nd->__next_) {
if (key_eq()(__nd->__upcast()->__value, __k))
goto __done;
}
}
}
{
__node_holder __h = __construct_node_hash(__hash, std::forward<_Args>(__args)...);
if (size() + 1 > __bc * max_load_factor() || __bc == 0) {
// rehash
}
__next_pointer __pn = __bucket_list_[__chash];
if (__pn == nullptr) {
__pn = __p1_.first().__ptr();
__h->__next_ = __pn->__next_;
__pn->__next_ = __h.get()->__ptr();
__bucket_list_[__chash] = __pn;
if (__h->__next_ != nullptr)
__bucket_list_[__constrain_hash(__h->__next_->__hash(), __bc)] = __h.get()->__ptr();
}
else {
__h->__next_ = __pn->__next_;
__pn->__next_ = static_cast<__next_pointer>(__h.get());
}
__nd = static_cast<__next_pointer>(__h.release());
++size();
__inserted = true;
}
__done:
return pair(iterator(__nd), __inserted);
}
小结
对unordered_map的到此算是告一段落,至于其余三个unordered容器,它们的实现方法大同小异,就不一一赘述了。