本文主要讲解tensorflow的API结构与入门,包含内容如下:
1. Tensorflow的安装;
2. Tensorflow的编程模式;
3. Tensorflow的Tensor,Op与Graph,Session的理解;
4. Tensorflow的编程应用;
1.Tensorflow的安装与官方文档
1.1.Tensorflow的安装
1.1.1.Tensorflow的常见版本
(from versions: 0.12.1, 1.0.0, 1.1.0rc0, 1.1.0rc1, 1.1.0rc2, 1.1.0, 1.2.0rc0, 1.2.0rc1, 1.2.0rc2, 1.2.0, 1.2.1, 1.3.0rc0, 1.3.0rc1, 1.3.0rc2, 1.3.0, 1.4.0rc0, 1.4.0rc1, 1.4.0, 1.4.1, 1.5.0rc0, 1.5.0rc1, 1.5.0, 1.5.1, 1.6.0rc0, 1.6.0rc1, 1.6.0, 1.7.0rc0, 1.7.0rc1, 1.7.0, 1.7.1, 1.8.0rc0, 1.8.0rc1, 1.8.0, 1.9.0rc0, 1.9.0rc1, 1.9.0rc2, 1.9.0, 1.10.0rc0, 1.10.0rc1, 1.10.0, 1.10.1, 1.11.0rc0, 1.11.0, 1.12.0rc0, 1.12.0rc1, 1.12.0rc2, 1.12.0, 1.12.2, 1.13.0rc0, 1.13.0rc1, 1.13.0rc2, 1.13.1, 2.0.0a0)
1.1.2.安装指令
pip install tensorflow
- 更新安装
pip install tensorflow -U
- 使用代理镜像安装
pip install tensorflow==2.0 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
- 其他的镜像
-
http://pypi.douban.com/simple/豆瓣 -
http://mirrors.aliyun.com/pypi/simple/阿里 -
http://pypi.hustunique.com/simple/华中理工大学 -
http://pypi.sdutlinux.org/simple/山东理工大学 -
http://pypi.mirrors.ustc.edu.cn/simple/中国科学技术大学 -
https://pypi.tuna.tsinghua.edu.cn/simple清华
-
1.1.3.tensorflow的版本验证
import tensorflow as tf
tf.__version__
'1.13.1'
1.2.Tensorflow的官方文档
1.2.1.站点
-
中文站点
http://www.tensorfly.cn
-
英文站点
https://tensorflow.google.cn
1.2.2.API 参考
https://tensorflow.google.cn/api_docs/python/tf
1.2.3.教程
https://tensorflow.google.cn/overview
1.2.4.说明
- 本文档就是基于教程 ,结合神经网络基础知识而写成。
2.Tensorflow编程模式
2.1.Tensorflow API结构
- Tensorflow的API结构可以说明如下
-
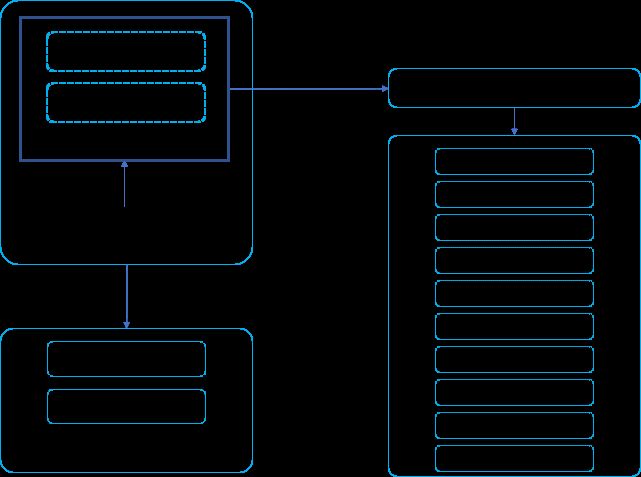 Tensorflow的API结构
Tensorflow的API结构
-
2.2.执行模式
2.2.1.Eager执行模式
不使用Graph模式,直接对数据进行执行运算,并输出结果。
这种模式在tensorflow2.0全面采用。
-
需要在整个执行开始的位置,直接启动eager执行模式。
tf.enable_eager_execution()
-
eager模式在,输出的结果依然是张量对象,但已经失去张量的某些功能,很多属性访问就没有意义。
- tensorflow提供numpy()函数返回:numpy array or a scalar with the same contents as the Tensor.
在这个文档中,这种执行模式我们不做多的介绍。下面是一个简单的例子,用来说明这种执行特点。
import tensorflow as tf
import numpy as np
# 启动立即执行模式
tf.enable_eager_execution()
# 立即自行执行一个普通的运算
m =[
[1, 2],
[3, 4]
]
# 一个list数据运算操作
p = tf.matmul(m, m)
print('tensorflow执行输出', p) # 输出的是Tensorflow对象
print(p.numpy())
# 一个ndarray数据运算操作
m = np.matrix([1,2])
p = tf.matmul(m, m.T)
print('tensorflow执行输出', p)
p.numpy()
# help(p)
tensorflow执行输出 tf.Tensor(
[[ 7 10]
[15 22]], shape=(2, 2), dtype=int32)
[[ 7 10]
[15 22]]
tensorflow执行输出 tf.Tensor([[5]], shape=(1, 1), dtype=int64)
array([[5]])
2.2.2.Graph执行模式
- Graph (tf.Graph) 就是程序(或者程序流程)
- 程序的基本构成单元是Tensorflow(张量)。
- 程序的构建不依赖具体的数据;
- Graph的执行依赖Session (tf.Session)
- 在Session执行Graph的时候,需要提供运行依赖的数据(类似函数定义与函数调用)
import tensorflow as tf
import numpy as np
m =[
[1, 2],
[3, 4]
]
# 一个list数据运算操作
p = tf.matmul(m, m)
print('定义的一个Tensor:', p)
# 仅仅是定义了一个简单的Graph
定义的一个Tensor: Tensor("MatMul_1:0", shape=(2, 2), dtype=int32)
# 使用Session执行Graph
session = tf.Session()
p_out = session.run(p)
print('Session执行输出:', p_out)
Session执行输出: [[ 7 10]
[15 22]]
2.3. 使用TensorBoard可视化Graph
- Tensorflow提供了一个模块实现Graph的仪表盘可视化:
- 保存Graph:使用
tf.summary模块 - 可视化Graph:
TensorBoard应用
- 保存Graph:使用
2.3.1.保存Graph
- tensorflow提供FileWrite类负责存储Graph的保存;
-
tf.summary.FileWriter构造器:
__init__(
logdir, # 保存目录,不是文件,因为该类不仅仅是保存Graph,生成的也不仅仅是一个文件。
graph=None, # Graph对象,一般不在构造器提供保存的Graph
max_queue=10,
flush_secs=120,
graph_def=None,
filename_suffix=None,
session=None
)
-
tf.summary.FileWriter与Graph有关的主要方法:-
add_graph方法
-
add_graph(
graph, # 要保存的图
global_step=None,
graph_def=None
)
-
与io有关的方法
flushclosereopen
-
其他方法
add_eventadd_meta_graphadd_run_metadataadd_session_logadd_summary
-
特别说明:
- 为了操作方便,
FileWriter提供了与with运算有关的两个运算符:__enter____exit__
- 为了操作方便,
Graph保存的例子代码
import tensorflow as tf
import numpy as np
m =[
[1, 2],
[3, 4]
]
# 一个list数据运算操作
p = tf.matmul(m, m)
print('定义的一个Tensor:', p)
# 仅仅是定义了一个简单的Graph,上面的p仅仅是一个Tensor,一个Tensor构成一个Graph。
writer = tf.summary.FileWriter('./graphs', tf.get_default_graph())
# writer.add_graph(tf.get_default_graph())
writer.flush()
writer.close()
定义的一个Tensor: Tensor("MatMul_8:0", shape=(2, 2), dtype=int32)
-
生成的文件名
events.out.tfevents.{timestamp}.{hostname}
-
获取Graph的方式很多
- 直接使用tf获取
- 从Session中获取
使用TensorBoard
-
TensorBoard应用程序
- 该应用程序会启动一个web服务,通过web的方式把graph等信息可视化展示出来。
-
TensorBoard命令介绍
- 主要参数
-
--logdir PATH# 日志目录,可以使用,指定多个目录,而且还可是指定名字:--logdir=name1:/path/to/logs/1,name2:/path/to/logs/2--logdir=/path/to/logs/1
-
--host ADDR# web服务的IP,可选,默认本机所有IP -
--port PORT# Web服务的端口 ,可选,默认6006
-
- 主要参数
-
启动TensorBoard服务
tensorboard --logdir ./graphs
-
使用TensorBoard服务
http://127.0.0.1:6006/
3. 理解Tensor与Op
- 在Tensorflow中,图就是程序,图由两种类型的对象组成。
- 操作(简称“op”):图的节点。操作描述了消耗(输入)和生成(输出)张量的计算。
- 张量:图的边。它们代表将流经图的值。大多数 TensorFlow 函数会返回 tf.Tensors。
3.1. 从Tensor的属性认识Tensor与Op
- Tensor一共提供了如下几个属性
- name:名字
- dtype:类型
- shape:形状
- op:操作
- device:设备
- graph:调用这个Tensor的Graph
- value_index:该张量在其运算输出中的索引
import tensorflow as tf
import numpy as np
m =[
[1, 2],
[3, 4]
]
# 一个list数据运算操作
p = tf.matmul(m, m)
print('name:',p.name)
print('dtype:',p.dtype)
print('shape:',p.shape)
print('op:',p.op)
print('device:',p.device)
print('graph:',p.graph)
print('value_index:',p.value_index)
session = tf.Session()
p_out = session.run(p)
print(type(p.op))
name: MatMul_5:0
dtype:
shape: (2, 2)
op: name: "MatMul_5"
op: "MatMul"
input: "MatMul_5/a"
input: "MatMul_5/b"
attr {
key: "T"
value {
type: DT_INT32
}
}
attr {
key: "transpose_a"
value {
b: false
}
}
attr {
key: "transpose_b"
value {
b: false
}
}
device:
graph:
value_index: 0
3.2.Tensor的构造器
- 构造器定义
__init__(
op, # 构造Tensor最难的就是op的描述。
value_index,
dtype
)
- 说明
- 从上面属性看得出来,构造Tensorflow的最难的,也是最核心的就是op的描述。
- op的类型是tensorflow的一个数据类型:
tensorflow.python.framework.ops.Operation
import tensorflow as tf
import numpy as np
m =[
[1, 2],
[3, 4]
]
# 一个list数据运算操作
p = tf.matmul(m, m)
print(type(p.op))
3.3.构造Tensor
-
从上面可以看出,自己手动构造Tensor是一件比较麻烦的事情,Tensorflow框架的最基本的就是,根据不同的操作,提供各种函数来返回Tensor对象,开发者无需使用构造器构造:
- Tensor的构造已经成为Tensorflow框架内置的一部分。
-
tf.Tensors核心是操作的数据描述,也包括关联的操作;- Tensorflow操作是单独的类型与对象,一般与Tensor关联。
3.3.1.构造不变张量
-
tf.constant函数定义
tf.constant(
value, # 需要初始操作的数据
dtype=None,
shape=None,
name='Const',
verify_shape=False
)
import tensorflow as tf
import numpy as np
# v = tf.constant(20) # 观察标量的初始化
# v = tf.constant([1, 2]) # 观察数组的初始化
v = tf.constant(np.array([1, 2]))
print(v)
print(v.op)
Tensor("Const_3:0", shape=(2,), dtype=int64)
name: "Const_3"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT64
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT64
tensor_shape {
dim {
size: 2
}
}
tensor_content: "\001\000\000\000\000\000\000\000\002\000\000\000\000\000\000\000"
}
}
}
- 不变张量的执行
import tensorflow as tf
import numpy as np
# v = tf.constant(20) # 观察标量的初始化
# v = tf.constant([1, 2]) # 观察数组的初始化
v = tf.constant(np.array([1, 2]))
session = tf.Session()
re_op = session.run(v)
print(type(re_op), ':', re_op)
: [1 2]
- 不变张量的作用
- 用来存储程序中一些不变的数据;
3.3.2.构造可变张量
-
tf.placeholder函数定义
tf.placeholder(
dtype, # 指定数据类型
shape=None, # 指定数据大小
name=None # 操作名(可选)
)
import tensorflow as tf
import numpy as np
# v = tf.constant(20) # 观察标量的初始化
# v = tf.constant([1, 2]) # 观察数组的初始化
v = tf.placeholder(dtype=tf.float32, shape=(2, 2), name='Var')
print(v)
print(v.op)
Tensor("Var:0", shape=(2, 2), dtype=float32)
name: "Var"
op: "Placeholder"
attr {
key: "dtype"
value {
type: DT_FLOAT
}
}
attr {
key: "shape"
value {
shape {
dim {
size: 2
}
dim {
size: 2
}
}
}
}
- 可变张量的执行
- 可变张量执行的时候,需要提供数据值,与不变张量的区别就是在执行时指定值。就算执行后,值也不会保存在张量中,这一点是与不变张量不同的。
- 在Session.run参数中指定数据值。
- Session.run函数定义:
run(
fetches, # 张量与操作。
feed_dict=None, # 通过字典,提供数据值。
options=None,
run_metadata=None
)
import tensorflow as tf
import numpy as np
# v = tf.constant(20) # 观察标量的初始化
# v = tf.constant([1, 2]) # 观察数组的初始化
v = tf.placeholder(dtype=tf.float32, shape=(2, 2), name='Var')
session = tf.Session()
re_op = session.run(v, feed_dict={
v:[[1,2],[3,4]]
})
print(type(re_op), ':', re_op)
: [[1. 2.]
[3. 4.]]
- 可变张量的用途
- 用来做输入数据。
- 执行的时候输入。
3.3.3.张量的封装管理类Variable
张量中的值使用一个Content的属性管理,一般对这个属性操作比较麻烦,tensorflow提供了
tf.Variable来管理对张量的读写操作。-
使用
tf.Variable类提供对张量的封装管理,一般简化对张量的频繁读写操作。-
tf.Variable管理者一个Tensor, -
tf.Variable对张量的读写由initializer成员函数来完成。
-
-
tf.Variable类的定义
__init__(
initial_value=None, # 初始值:Tensor对象, 或者可以转化为Tensor的Python对象(一般数据性对象都能转换)
trainable=True, # 是否可训练(用来存放训练后生成的参数)
collections=None,
validate_shape=True,
caching_device=None,
name=None,
variable_def=None,
dtype=None,
expected_shape=None,
import_scope=None,
constraint=None,
use_resource=None,
synchronization=tf.VariableSynchronization.AUTO,
aggregation=tf.VariableAggregation.NONE
)
import tensorflow as tf
import numpy as np
v = tf.Variable(20)
print(v) # 默认初始化器
-
tf.Variable初始化张量与执行- tf.Variable需要初始化才能使用
import tensorflow as tf
import numpy as np
v = tf.Variable(20)
session = tf.Session()
session.run(v.initializer)
re_op = session.run(v)
print(type(re_op), ':', re_op)
: 20
- 访问Variable管理的张量
- 访问张量与张量的值。
import tensorflow as tf
import numpy as np
v = tf.Variable(20)
session = tf.Session()
session.run(v.initializer)
t = v.value() # 返回Variable管理的张量
print(t) # 返回张量
t_value = session.run(t) # 执行张量
print(t_value)
Tensor("Variable_17/read:0", shape=(), dtype=int32)
20
- 写数据到Variable管理的张量
import tensorflow as tf
import numpy as np
v = tf.Variable(20)
session = tf.Session()
session.run(v.initializer)
t = v.assign(40)
print('新的Tensor:', t)
print('原始Tensor:', v.value())
print('---------------')
t_value = session.run(t) # 执行张量
print('新的值:', t_value)
print('---------------')
value2 = session.run(v.value()) #
print('原始值:', value2)
新的Tensor: Tensor("Assign_7:0", shape=(), dtype=int32_ref)
原始Tensor: Tensor("Variable_25/read:0", shape=(), dtype=int32)
---------------
新的值: 40
---------------
原始值: 40
-
说明:
- 实际上Variable管理的张量比较复杂,包括张量的作用范围,生命周期等。这里不深入解释,能达到应用的目的就行。
- Tensorflow还提供了创建Variable对象的函数:
tf.get_variable()
-
对Variable快速的初始化
- 调用每个Variable的默认initializer实现初始化比较麻烦,Tensorflow提供session中所有变量的初始化封装。
tf.global_variables()-
tf.initializers.global_variables()tf.global_variables_initializer()
- 调用每个Variable的默认initializer实现初始化比较麻烦,Tensorflow提供session中所有变量的初始化封装。
import tensorflow as tf
import numpy as np
v = tf.Variable(20)
session = tf.Session()
init_op = tf.global_variables_initializer() # 返回操作
# print(init_op)
session.run(init_op)
t = v.assign(40)
print('新的Tensor:', t)
print('原始Tensor:', v.value())
print('---------------')
t_value = session.run(t) # 执行张量
print('新的值:', t_value)
print('---------------')
value2 = session.run(v.value()) #
print('原始值:', value2)
# print(tf.global_variables())
新的Tensor: Tensor("Assign_9:0", shape=(), dtype=int32_ref)
原始Tensor: Tensor("Variable_29/read:0", shape=(), dtype=int32)
---------------
新的值: 40
---------------
原始值: 40
[, , , , , , , , , , , , , , , , , , , , , , , , , , , , , ]
3.4.Tensorflow基础运算
- Tensorflow的运算都是通过函数与运算符来实现,大部分函数返回数据类型有两个:
- 张量(也包含操作):执行后返回张量的值。
- 操作:执行后返回None。
3.4.1.Tensor的运算符
- Tensor的运算符与Python的基本数据类型的运算基本上一样。下面使用例子说明;
- Variable也封装了同等的运算发,提供对张量的运算。
- Tensor中的运算符例子
import tensorflow as tf
import numpy as np
x = tf.constant(20)
y = tf.constant(30)
session = tf.Session()
session.run(tf.global_variables_initializer())
z = x + y
print(z)
r_z = session.run(z)
print(r_z)
Tensor("add:0", shape=(), dtype=int32)
50
import tensorflow as tf
import numpy as np
x = tf.placeholder(dtype=tf.float32, shape=(1,3))
y = tf.placeholder(dtype=tf.float32, shape=(3,1))
session = tf.Session()
z = x @ y
r_z = session.run(z, feed_dict={x:[[1, 2, 3]], y:[[4], [5], [6]]})
print(r_z)
[[32.]]
- Variable中的运算例子
import tensorflow as tf
import numpy as np
x = tf.Variable(20)
y = tf.Variable(30)
session = tf.Session()
session.run(tf.global_variables_initializer())
z = x + y
print(z)
r_z = session.run(z)
print(r_z)
Tensor("add_4:0", shape=(), dtype=int32)
50
3.4.2.数学与随机运算
- 数学与随机函数基本上与math模块,numpy模块的差不多,同时也增加了一些新的数学函数,比如sigmoid函数,sign符号函数等。
- 下面主要使用例子说明下统计函数
reduce_mean- 求均值(会降维):
reduce_mean
- 求均值(会降维):
import tensorflow as tf
import numpy as np
# x = tf.Variable([1,2,3,4])
x = [1,2,3,4]
m = tf.math.reduce_mean(x)
print(m)
session = tf.Session()
session.run(tf.global_variables_initializer())
r_m = session.run(m)
print(r_m)
# 不能直接运算输出
# print(tf.math.reduce_mean([1,2,3,4]))
Tensor("Mean_8:0", shape=(), dtype=int32)
2
import tensorflow as tf
import numpy as np
# x = tf.Variable([1,2,3,4])
x = tf.placeholder(dtype=tf.int32, shape=(4, ))
m = tf.math.reduce_mean(x)
session = tf.Session()
r_m = session.run(m, feed_dict={x:[1, 2, 3, 4]})
print(r_m)
2
3.4.3.线性代数运算
- 线性代数运算与numpy差不多,下面使用特征值与奇异值举例子说明
import tensorflow as tf
import numpy as np
x = tf.Variable([
[1.0, 2.0, 3.0],
[2.0, 6.0, 1.0],
[9.0, 2.0, 6.0]
])
cp = tf.linalg.eigh(x) # x必须是float64, float32, complex64, complex128四种
session = tf.Session()
session.run(tf.global_variables_initializer())
eigh_val, eigh_vec = session.run(cp)
print(eigh_val)
print(eigh_vec)
[-5.853533 5.01042 13.843116]
[[ 0.7987046 0.17742541 -0.5749706 ]
[-0.03339223 -0.94099814 -0.3367607 ]
[-0.60079604 0.2881717 -0.7456549 ]]
3.5.Tensorflow的高级操作
3.5.1.损失函数
-
tf.losses.hinge_loss-
- 表示样本总数
- 一般用于SVM作为最大间隔分类
-
-
tf.losses.huber_loss-
- Huber loss是为了增强平方误差损失函数(squared loss function)对噪声(或叫离群点,outliers)的鲁棒性提出的
-
-
tf.losses.log_loss- 逻辑回归中的损失函数,也称逻辑回归损失(Logistic Loss)或交叉熵损失(cross-entropy Loss)
tf.losses.mean_squared_error-
tf.losses.sigmoid_cross_entropy- 就是
tf.losses.log_loss函数执行前,多一个sigmoid函数运算。
- 就是
-
tf.losses.softmax_cross_entropy- 就是``函数执行前,多一个softmax函数运算
- softmax函数定义
- 为softmax函数的输出。
3.5.2.评估度量运算
tf.metrics.accuracytf.metrics.auctf.metrics.precisiontf.metrics.recall
3.5.3.优化算法
-
tf.train.AdagradOptimizer- 集成算法中的Ada梯度下降优化算法
-
tf.train.GradientDescentOptimizer- 梯度下降优化算法
3.5.4.神经网络独有的运算
-
tf.nn.conv3d- 卷积运算
-
tf.nn.dropout- 停用
-
tf.nn.pool- 池化
-
各种激活函数
-
tf.nn.relu等
-
3.6.使用各种Tensor构建算法实现
3.6.1.线性回归实现
import numpy as np
import tensorflow as tf
# 年龄
X_DATA = np.loadtxt('ex2x.dat')
# 身高
Y_DATA = np.loadtxt('ex2y.dat')
# 改变形状(在上面的推导中,我们对x与X的定义是确定的,x是多元特征构成的行向量;X是多个样本构成的矩阵,其中每行是一个多元特征的样本)
X=np.zeros(shape=(X_DATA.shape[0], 2),dtype=np.float)
Y=Y_DATA.reshape(Y_DATA.shape[0], 1)
X[:, 0]=X_DATA
X[:, 1]=1
# 下面是Tensorflow代码------------
x = tf.placeholder( tf.float32, [None, 2] ) #标量
y = tf.placeholder( tf.float32, [None, 1] ) #标量
# 求转置
t=tf.transpose(x)
# 求内积
d1=tf.matmul( t, x )
# 求逆矩阵
i= tf.matrix_inverse( d1 )
# 求内积
d2=tf.matmul( i, t )
# 求内积
d3=tf.matmul( d2, y )
session=tf.Session()
init_op=tf.global_variables_initializer()
#参数传递
re=session.run(d3, feed_dict={ x:X, y:Y } )
print(re)
[[0.06388131]
[0.7501621 ]]
3.6.2.逻辑回归分类实现
import numpy as np
import tensorflow as tf
import tensorflow.math as ma
import tensorflow.losses as ls
import tensorflow.train as tr
from sklearn import datasets
'''
'''
INPUT_SIZE=4
OUTPUT_SIZE=1
# 我们使用鸢尾花数据作为分类测试
# 1. 定义数据(一般是样本与样本标签)
x=tf.placeholder(dtype=tf.float32,shape=[None,INPUT_SIZE])
y=tf.placeholder(dtype=tf.float32,shape=[None,OUTPUT_SIZE])
init_w=tf.random_uniform(shape=(INPUT_SIZE,OUTPUT_SIZE),minval=-0.1,maxval=0.1,dtype=tf.float32)
init_b=tf.random_uniform(shape=[OUTPUT_SIZE],minval=-0.1,maxval=0.1,dtype=tf.float32)
w=tf.Variable(init_w)
b=tf.Variable(init_b)
# 2. 决策参数模型描述
o_y=tf.matmul(x,w)+b
o_predict=tf.sigmoid(o_y)
# 3. 梯度下降参数模型
loss=ls.sigmoid_cross_entropy(y,o_y) # y是输入的真实标签,o_y是决策模型输出的理想标签
optimizer=tr.GradientDescentOptimizer(learning_rate=0.01)
trainer=optimizer.minimize(loss=loss)
# 4. tensorflow运算执行会话环境
op_init=tf.initializers.global_variables()
session=tf.Session()
session.run(op_init)
# 5. 执行与训练
data,target=datasets.load_iris(return_X_y=True)
data=data[50:150]
target=target[0:100]
target=target.reshape(target.shape[0],OUTPUT_SIZE)
# 训练次数
# 分epoch,每个epoch分若干batch,每个batch若干样本
epoch=10000
batch_size=10
batch_num=10
for t in range(epoch):
for i in range(batch_num):
session.run(trainer, feed_dict={x:data[i*batch_size:(i+1)*batch_size],y:target[i*batch_size:(i+1)*batch_size]})
# 训练误差低于某个值就结束训练
ls=session.run(loss, feed_dict={x:data,y:target})
if ls < 10e-5:
print("梯度过小,结束训练!")
break
# 6. 预测与分类评估
o_v=session.run(o_predict, feed_dict={x:data})
#print(o_v)
# 统计正确率
# 前50个
a_num=(o_v[0:50]<0.5).sum()
print(a_num)
b_num=(o_v[50:100]>0.5).sum()
print(b_num)
47
50
3.6.3. SVM分类实现
- SVM的损失函数如下(假设为固定参数值):
import numpy as np
import tensorflow as tf
import tensorflow.math as ma
import tensorflow.losses as ls
import tensorflow.train as tr
from sklearn import datasets
'''
'''
alpha = 1
INPUT_SIZE=4
OUTPUT_SIZE=1
# 我们使用鸢尾花数据作为分类测试
# 1. 定义数据(一般是样本与样本标签)
x=tf.placeholder(dtype=tf.float32,shape=[None,INPUT_SIZE])
y=tf.placeholder(dtype=tf.float32,shape=[None,OUTPUT_SIZE])
init_w=tf.random_uniform(shape=(INPUT_SIZE,OUTPUT_SIZE),minval=-0.1,maxval=0.1,dtype=tf.float32)
init_b=tf.random_uniform(shape=[OUTPUT_SIZE],minval=-0.1,maxval=0.1,dtype=tf.float32)
w=tf.Variable(init_w)
b=tf.Variable(init_b)
# 2. 决策参数模型描述
o_y = tf.add(tf.matmul(x, w), b)
o_predict = tf.sign(o_y)
# Declare vector L2 'norm' function squared
l2_norm = tf.reduce_sum(tf.square(w))
# Loss = max(0, 1-pred*actual) + alpha * L2_norm(A)^2
alpha = 0.01
hinge = tf.losses.hinge_loss(y, o_y) # tf.reduce_mean(tf.maximum(0., tf.subtract(1., tf.multiply(o_y, y))))
# loss = tf.add(l2_norm, tf.multiply(alpha, hinge))
loss = hinge + alpha*l2_norm
optimizer=tr.GradientDescentOptimizer(learning_rate=0.01)
# optimizer = tf.train.RMSPropOptimizer(learning_rate=0.01)
trainer=optimizer.minimize(loss=loss)
# --------------------------------- 静态图
graph_writer=tf.summary.FileWriter("./graphs",graph=tf.get_default_graph())
graph_writer.flush()
graph_writer.close()
# ---------------------------------
# 4. tensorflow运算执行会话环境
op_init=tf.initializers.global_variables()
session=tf.Session()
session.run(op_init)
# 5. 执行与训练
data,target=datasets.load_iris(return_X_y=True)
data=data[50:150]
target=target[0:100]
target[target==0] = -1 # -1 与 1
target=target.reshape(target.shape[0],OUTPUT_SIZE)
# 训练次数
# 分epoch,每个epoch分若干batch,每个batch若干样本
epoch=10000
batch_size=10
batch_num=10
for t in range(epoch):
for i in range(batch_num):
session.run(trainer, feed_dict={x:data[i*batch_size:(i+1)*batch_size],y:target[i*batch_size:(i+1)*batch_size]})
ls=session.run(loss, feed_dict={x:data,y:target})
# print(ls)
if ls < 10e-5:
print("梯度过小,结束训练!")
break
# 6. 预测与分类评估
o_v=session.run(o_predict, feed_dict={x:data})
# print(o_v)
(o_v == target).sum()
96
- SVM的Graph可视化
-
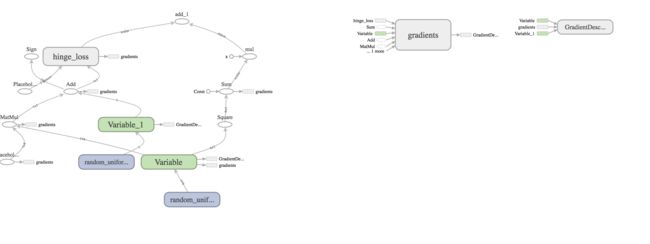 SVG的Graph可视化
SVG的Graph可视化
-
3.6.4.感知器分类实现
# coding=utf-8
from sklearn import datasets #获取鸢尾花数据样本
import tensorflow as tf #tensoflow模块
import time
start = time.clock()
#########################################
LEARNING_RATE = 0.001 #学习率
TIMES = 10 #训练轮数
DATA_SIZE = 4 #特征个数,也就是训练样本的数组长度
# 一、感知器计算图描述
# 1.描述输入数据:训练样本sample,训练样本的期望标签label
sample = tf.placeholder(dtype=tf.float32, shape=[None, DATA_SIZE]) # 第一个是训练样本个数(不确定设置为None),第二个特征个数
label = tf.placeholder(dtype=tf.float32, shape=[None]) # 训练样本的期望标签是标量,其值为0或者1
# 2.描述权重与偏置值(初始值随机)
w_init = tf.random_uniform(shape=[DATA_SIZE, 1], minval=-0.1, maxval=0.1, dtype=tf.float32)
weights = tf.Variable(w_init) # 传统方式
b_init = tf.random_uniform(shape=[], minval=-0.1, maxval=0.1, dtype=tf.float32)
bias = tf.Variable(b_init)
# 3.描述加权求和操作节点
amount = tf.matmul(sample,weights)+bias
# 4.描述损失函数操作节点
loss = tf.reduce_mean(tf.square(amount-label))
#5.描述梯度优化操作节点
trainer=tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(loss) #使用学习率,最小化误差损失
#二、感知器计算图运行
#加载鸢尾花数据
data,target=datasets.load_iris(return_X_y=True) #第一个返回值是样本数据,第二个返回值是样本的期望标签
#取前面100个眼本测试(这100个是线性可分的)
train_data=data[:100]
label_data=target[:100] #第一类是0,第二类是1
#1.构建运行会话
session=tf.Session()
#2.初始化环境
init_op=tf.global_variables_initializer()
session.run(init_op)
#---------------------------
graph_writer=tf.summary.FileWriter("./graphs",graph=session.graph) # Session执行的所有变化都会记录
#---------------------------
#3.开始训练
print("开始训练!")
for n in range(TIMES):
# print("第%4d轮训练"%(n+1))
for i in range(len(train_data)):
session.run(trainer,feed_dict={sample:train_data[i:i+1],label:label_data[i:i+1]})
#session.run(trainer, feed_dict={sample: train_data, label:label_data})
print("训练完毕!")
#4.测试训练
correct_counter=0
#前50个期望标签都是0(近似0.5以下都算正确)
for item in train_data[:50]:
result=session.run(amount,feed_dict={sample:[item]})
# print(result)
if result<0.5:
correct_counter+=1
print("===============")
#后50个期望标签都是1(近似0.5以上都算正确)
for item in train_data[50:]:
result = session.run(amount, feed_dict={sample: [item]})
# print(result)
if result>=0.5:
correct_counter+=1
#打印正确率:
print("正确率:%8.2f"%((correct_counter/100.0)*100))
#########################################
end=time.clock()
print("CPU运行时间:",end-start)
#-----------------------
graph_writer.close()
#-----------------------
开始训练!
训练完毕!
===============
正确率: 100.00
CPU运行时间: 1.8461539999998422
- tensorboard的可视化Graph图(在jupyter-notebook中还包含其他Graph,可以再独立环境中输出)
-
 感知器的Graph
感知器的Graph
-
附录:
- Tensorflow的框架从软件开发的角度实际挺简单的,其中使用的难点在于对算法的理解以及应用。
- 本文的资料获取:
- https://github.com/QiangAI/ClassCodes/tree/master/day31