- 共享锁与排它锁
- 锁粒度之 行与表
- 锁粒度之 间隙(Gap)
3.1 何为间隙?
3.2 为什么要有间隙锁?
3.3 插入意图锁(Insert Intention Locks) - RR级别下的加锁案例分析
4.1 主键
4.2 唯一索引
4.3 一般索引
4.4 无索引 - 死锁
5.1 SQL执行顺序不一致
5.2 二级索引中记录锁的获取顺序不同
5.3 同一SQL不同索引的选择
5.4 插入唯一索引导致的死锁
5.5 一些减少死锁的建议
1. 共享锁与排它锁
- 共享锁(Shared Lock,以下简称S):允许多个一起共享;
- 排它锁(Exclusive Lock,以下简称X):独占式的锁。
| S | X | |
|---|---|---|
| S | 不冲突 | 冲突 |
| X | 冲突 | 冲突 |
锁的冲突与否都是针对同一个对象来说的,比如线程1给对象A加了一把S锁了,线程2可以继续给对象A加S锁,但不能加X锁(因为冲突),然而对象A的S锁和对象B是没有任何关系的。
也有称共享锁为读锁,排它锁为写锁,字面意思“读可以大家一起读,写只能一个人写”,类似于共享和独占。
2. 锁粒度之 行与表
我们常说的行锁(Record Locks)与表锁(Table Locks),是以锁粒度来分的。行也有分行读锁和行写锁,表也有表读锁和表写锁。
可以结合一些常说的描述理解下:
(1)这几行加了S锁了,这些行不能再加X锁了;
(2)这个表加了X锁了,这个表不能再加其他S或X锁了。
关于表锁,还有表意图锁(Intention Locks),本文不会对表锁过多关注。有兴趣的读者可以了解下冲突情况,以及其作用。
注:行锁/记录锁(Record Locks)是基于索引记录实现的(二级索引和聚簇索引),参考官网:Record locks always lock index records
3. 锁粒度之 间隙(Gap)
3.1 何为间隙?
大家都知道,索引的数据结构为B+树,叶子节点的索引记录均是按照顺序排序的,比如:10,20,30;而10和20之间,还可以插入11、12、...19,而这两者之间的“距离”就被称之为间隙,如下图:
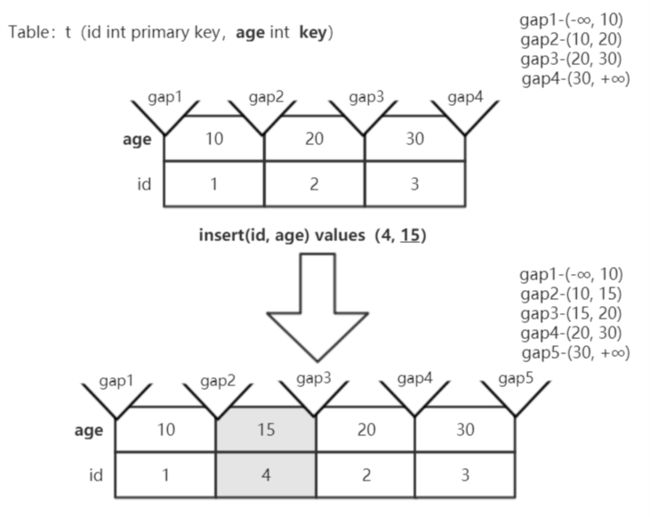
而所谓的间隙锁,就是以Gap为维度进行的加锁。
和行表一样,间隙锁也有读写之分 ,不同的是:一般的间隙读写锁之间均不冲突(见下文“插入意图锁”)
3.2 为什么要有间隙锁?
首先确定一点:MySQL在默认的可重复读(REPEATABLE READ,以下简称RR)隔离级别下,是不存在幻读问题的,而间隙锁就是解决幻读问题的关键之一。
回顾select语句,主要分两类:
- 常规select:
select .. where ... - 带锁select:
select .. where ... in share mode、select ... where ... for update
在RR隔离级别中,为了解决幻读问题:
- 针对常规select,采用快照读的方式:第一次读时建立快照,之后无论其他事务是否新增/删除了记录,读取的永远都是那个快照对应的数据,从而避免了幻读问题。
- 针对带锁select,当读取数据记录时,除了锁住记录本身(Record Lock),同时将符合条件的间隙锁起来(Gap Lock),预防第一次读和第二次读的期间,其他事务往间隙插入了新数据。这就是间隙锁的意义!
参考官方文档:一致性读(Consistent Nonlocking Reads)、带锁读(Lock Reads)
3.3 插入意图锁(Insert Intention Locks)
3.3.1意图锁的冲突情况
所谓“意图”,表示“将要”、“想要”的意思;插入动作发起前,会先尝试获取这个插入意图锁,如果无法获取到则进入等待状态。插入意图锁是一种特殊的间隙锁(锁定粒度依然是Gap)。
特别地:插入意图锁之间不冲突,一般的间隙锁(Gap S-Lock和Gap X-Lock)之间不冲突,但是插入意图锁和一般的间隙锁冲突:
| 插入意图锁 | Gap S-Lock | Gap X-Lock | |
|---|---|---|---|
| 插入意图锁 | 不冲突 | 冲突 | 冲突 |
| Gap S-Lock | 冲突 | 不冲突 | 不冲突 |
| Gap X-Lock | 冲突 | 不冲突 | 不冲突 |
3.3.2 为什么需要插入意图锁?
如果单纯地为了解决幻读,使用Gap S/X-Lock就可以实现:
假如Gap 的S/X-Lock和一般的S/X-Lock冲突情况是一样的话,插入时加Gap X-Lock,带锁读时加Gap S/X-Lock,因为存在冲突,一样能避免幻读的问题。然而这样玩的话,插入的并发能力就受阻了,比如现在有个Gap-(10, 20),插入11和12是冲突的(因为都是Gap X-Lock),尽管这时候没有带锁读。
新增插入意图锁的话,意图锁与意图锁之间兼容,允许两个事务同时插入11、12。而插入意图锁和一般的间隙锁冲突,有效防止了幻读的问题,两全其美。
4. RR级别下的加锁案例分析
- select .. where ... in share mode
- select ... where ... for update
- update ... where ...
- delete ... where ...
以上几个语句,可以简单地认为:同一张表,如果where 条件一样,其加锁范围也是一样的;只不过select ... in share mode加的是S锁,其他的是X锁。
以下以用户表(t_user)为例(id为主键,name为唯一索引,age为一般索引,address无索引)分析不同索引条件的加锁表现。
CREATE TABLE `t_user` (
`id` bigint NOT NULL,
`name` varchar(20) ,
`age` int ,
`address` varchar(20) ,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_name` (`name`) USING BTREE,
KEY `idx_age` (`age`)
) ENGINE=InnoDB;
4.1 主键
例:delete from t_user where id=120;
条件为主键,此时锁住聚簇索引中对应的行记录:

SQL验证:
| time | session 1 | session 2 |
|---|---|---|
| 1 | start transaction; | start transaction; |
| 2 | delete from t_user where id=120; Query OK, 1 row affected (0.00 sec) |
|
| 3 | delete from t_user where id=120; ...Lock wait timeout...(阻塞至超时) (聚簇索引Record X-Lock冲突) |
4.2 唯一索引
例:delete from t_user where name='n20';
条件为唯一索引,锁住索引记录,同时锁住聚簇索引中的对应行记录:
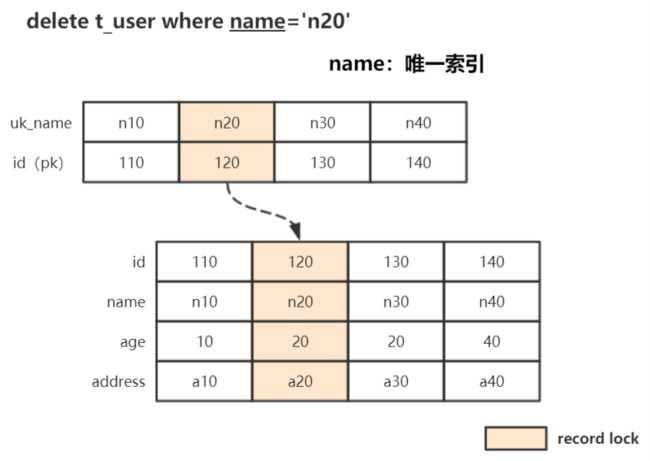
SQL验证:
| time | session 1 | session 2 |
|---|---|---|
| 1 | start transaction; | start transaction; |
| 2 | delete from t_user where name='n20'; Query OK, 1 row affected (0.00 sec) |
|
| 3 | delete from t_user where name='n20'; ...Lock wait timeout... (唯一索引Record X-Lock冲突) |
|
| 3 | delete from t_user where id=120; ...Lock wait timeout... (聚簇索引Record X-Lock冲突) |
为什么要把行记录也锁上?数据库中为了避免并发写操作导致的数据问题(比如丢失更新),写操作(增删改)总是加X锁执行的(串行),而InnoDB中的“数据”指的就是聚簇索引上的行记录(一行的完整数据)。
4.3 一般索引
例:delete from t_user where age=20;
与主键和唯一索引不同的是,一般索引的记录是允许重复的;换句话说,如果我们单纯地给索引加记录锁时,其他事务依然可以插入,也就有可能出现幻读问题了。
所以除了给对应索引记录加上记录锁之外,还要给Gap加上锁,如下图:

我们可以猜测这个操作一共需要的锁:
- age索引记录锁(Record Lock) :20_120, 20_130(以下均用age_id这种形式表示索引值)
- age索引间隙锁(Gap X-Lock):(10, 20)、(20, 20)、(20, 40)
- 聚簇索引上的记录锁(Record X-Lock):id=120/130对应的行记录
还记得我们之前说的各种不同类型锁的冲突情况吗?记录锁的S与S兼容、X与S/X冲突;Gap S/X-Lock与Gap S/X-Lock兼容,Gap S/X-Lock与插入意图锁冲突。我们来用SQL验证一下:
| time | session 1 | session 2 |
|---|---|---|
| 1 | start transaction; | start transaction; |
| 2 | delete from t_user where age=20; Query OK, 2 row affected (0.00 sec) |
|
| 3 | delete from t_user where age=20; ...Lock wait timeout... (age索引的Record X-Lock之间冲突) |
|
| 4 | delete from t_user where id=120; ...Lock wait timeout... (聚簇索引的Record X-Lock之间冲突) |
|
| 5 | insert into t_user(age) values(15); ...Lock wait timeout... ((10,20)的Gap X-Lock与插入意图锁冲突) |
|
| 6 | insert into t_user(age) values(25); ...Lock wait timeout... ((20,40)的Gap X-Lock与插入意图锁冲突) |
|
| 7 | insert into t_user(age) values(10); ...Lock wait timeout... (阻塞了?难道边界的10和40也会加锁?) |
|
| 8 | insert into t_user(age) values(40); Query OK, 1 row affected (0.00 sec) (这个不阻塞?) |
根据实际情况,3-6均符合我们预期,然而7和8则超出了我们预期的锁范围。
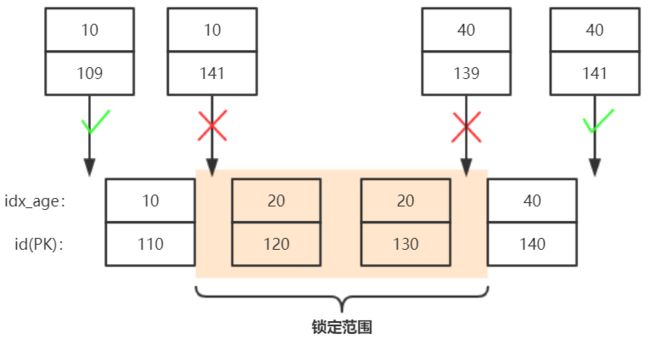
插入的索引项,因为是自增主键,7预计为:10_141、8预计为:40_141,为什么只有后者能插入呢?
其实我们可以将B+树中的间隙理解得更加精准一点:age=20的三个间隙应该为:(10_110, 20_120)、(20_120, 20_130)、(20_130, 40_140);
(10_110, 20_120)包含值还有:10_111、10_112、...、10_141..,因为该间隙被锁住了,所以 10_141 无法插入;而 40_141 已经在间隙之外了,无锁冲突,允许插入。如下图:
我们通过以下SQL可以验证:
| time | session 1 | session 2 |
|---|---|---|
| 1 | start transaction; | start transaction; |
| 2 | delete from t_userwhere age=20; Query OK, 2 row affected (0.00 sec) |
|
| 3 | insert into t_user(age,id) values(10,109); Query OK, 1 row affected (0.01 sec) (10_109插入成功) |
|
| 4 | insert into t_user(age,id) values(10,141); ...Lock wait timeout... (10_141插入失败) |
|
| 4 | insert into t_user(age,id) values(40,139); ...Lock wait timeout... (40_139插入失败) |
|
| 4 | insert into t_user(age,id) values(40,141); Query OK, 1 row affected (0.00 sec) (40_141插入成功) |
所以最终的加锁情况应该这样表示:
- age索引记录锁(Record Lock) :20_120, 20_130
- age索引间隙锁(Gap X-Lock):(10_110, 20_120)、(20_120, 20_130)、(20_130, 40_140)
- 聚簇索引上的记录锁(Record X-Lock):id=120/130对应的行记录
在RC(READ COMMITTED)隔离级别中,只会在对应的索引/行记录上加Record Lock,而不会加Gap锁;原因也很简单,因为该隔离级别是允许存在幻读问题的。
InnoDB将RR级别下的加锁方式称之为Next-Key Locks,其实就是上述Record Locks和Gap Locks的结合。比如Gap Lock为(10,20) ,record lock为20,结合的Next-Key lock 为:(10, 20]。分析Next-Key Locks其实就是要分析Record Locks和Gap Locks。
4.4 无索引
delete from t_user where address='a20',因为无法精准定位,InnoDB选择将聚簇索引中的所有行以及间隙都锁起来,功能上已经等于锁表了:

SQL验证:
| time | session 1 | session 2 |
|---|---|---|
| 1 | start transaction; | start transaction; |
| 2 | delete from t_user where address='a20'; Query OK, 1 row affected (0.00 sec) |
|
| 3 | delete from t_user where id=110; ...Lock wait timeout... (聚簇索引Record X-Lock之间冲突) |
|
| 4 | delete from t_user where age=40; ...Lock wait timeout... (一般索引Record X-Lock之间冲突) |
|
| 5 | insert into t_user(age) values(50); ...Lock wait timeout... (Gap X-Lock和插入意图锁冲突) |
|
| 6 | ... |
在RC隔离级别中,针对update/delete语句,遍历全部记录的过程中,如果某行记录不满足条件,其锁会被释放掉(最终会只锁住符合条件的记录);其过程为:加锁 -> where条件是否满足 -> 不满足释放锁,这个过程也表明了:如果一开始加锁的时候已经冲突了,就必须等待了。
RR隔离级别没有做类似的优化,其原因依然是为了防止幻读,因为你无法保证哪个地方会插入符合条件的记录。
5. 死锁
存在两个或以上的相互冲突的锁,而且多个线程(事务)加锁的顺序不一致时,就有可能发生死锁。
InnoDB默认启用死锁检测,当检测到死锁时,会结合事务日志大小、加锁数量、事务时间等,选择回滚其中一个成本最小的事务,从而推动系统正常运行。
5.1 SQL执行顺序不一致
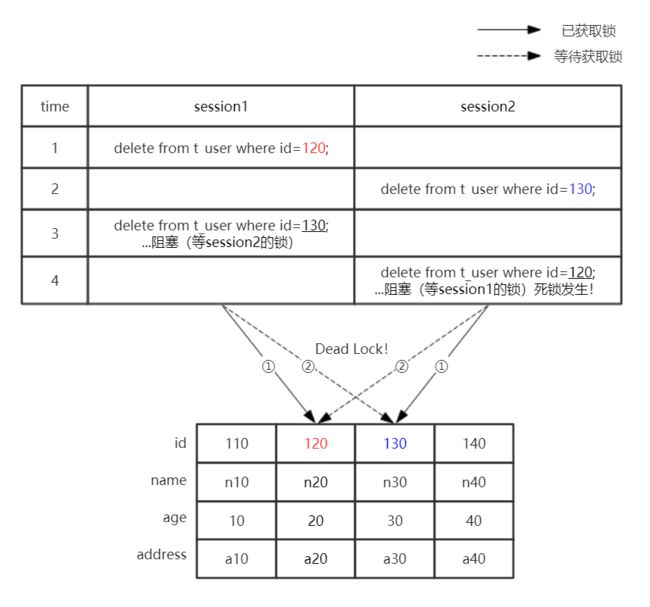
可以认为是同样的两条SQL,session1是先执行删120的,而session2则是先执行删130的,从而导致死锁的发生。
避免方法:尽量保证同样的多条SQL在不同事务中执行顺序一致。
5.2 二级索引中记录锁的获取顺序不同
基础知识:
(1)二级索引本身锁定后,还需要锁定聚簇索引上的行记录
(2)记录是一条一条地锁上的
基于上面两点,当不同索引指向的是多条相同记录时,因为加锁的顺序可能不一样,死锁的问题也就有可能发生:
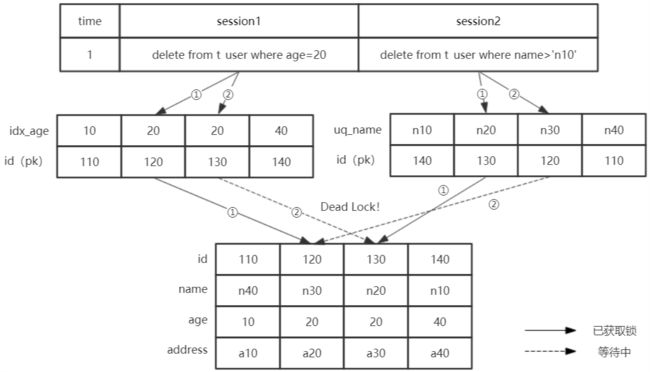
避免方法:留意根据不同索引进行的更新/删除语句,尽量使用某个特定的索引进行更新/删除,比如主键、订单号等。
5.3 同一SQL不同索引的选择
同事曾经提到的一种死锁情况:
SQL:update t set status=1 where a > ? and b > ? ,其中a和b均有建立二级索引;
a、b可能传入不同的值,当多个线程并发执行这条SQL时,死锁就有可能会出现。
原因:
(1)每次执行,只会选择其中一个索引
(2)根据不同的入参、或者同样的入参,但是索引a和b均没有明显的数量优势的情况,查询优化器每次执行时可能会选择不同的索引(尽管是同一SQL)。
因为存在交替选择索引的情况,这时候其实就是上一个案例的情况了。
避免方法:如果无法避免这样的索引和SQL,而且发生了死锁,可以使用FORCE INDEX强迫使用某个索引。
5.4 插入唯一索引导致的死锁
我们来看一个例子:
| time | session 1 | session 2 | session3 |
|---|---|---|---|
| 1 | start transaction; | start transaction; | start transaction; |
| 2 | insert into t_user(name) values('n99'); Query OK, 1 row affected (0.00 sec) |
||
| 3 | insert into t_user(name) values('n99'); ...阻塞中 |
||
| 4 | insert into t_user(name) values('n99'); ...阻塞中 |
||
| 5 | rollback; | Deadlock found when trying to get lock; | Query OK, 1 row affected (0.00 sec) |
name为唯一索引,主键也是唯一的,换成id也能重现这种情况。
根据官网的解释:
- session1插入后,获取到'n99'的Record X-Lock;
- 当session2/3再插入,唯一键检查发生duplicate-key error,此时session2/3会申请获取一个‘n99’的S锁(等待中);
- session1回滚后,session2/3会同时获取到S锁(共享);
- session2 申请获取‘n99’的Record X锁,此时无法获取(session3持有S锁); 同样地session3也无法获取X锁,死锁发生!
The first operation by session 1 acquires an exclusive lock for the row. The operations by sessions 2 and 3 both result in a duplicate-key error and they both request a shared lock for the row. When session 1 rolls back, it releases its exclusive lock on the row and the queued shared lock requests for sessions 2 and 3 are granted. At this point, sessions 2 and 3 deadlock: Neither can acquire an exclusive lock for the row because of the shared lock held by the other.
避免方法:尽量避免同样的记录并发重复插入。这样的情况通常发生在:用户重复提交、HTTP/RPC重试等情况下,如有必要,引入分布式锁进行防止。
5.5 一些减少死锁的建议
- 尽量少用锁;
select ... lock in share mode、select ... for update这种带锁读,尽量避免使用; - 不要在事务中逗留过长的时间;比如在应用层,查询与组装参数等动作尽量放到真正事务开启前;
- 尽量精简事务的任务数量;这个根据实际情况出发;
- 尽量使用上索引条件;在RR隔离级别下,没有索引条件会锁住全部记录。
官方文档也专门提到了减少死锁和处理死锁的相关建议。
参考资料:
- 官方文档,一切以官方为准。
- 何登成的技术博客,推荐阅读